Railyard:我们如何快速训练机器学习模型…… - Stripe
以现代企业的规模运行基础设施,常常会面临数据科学和机器学习模型。本文将详细介绍Railyard的架构设计以及在构建和运行机器学习基础设施中的最佳实践。
为组织提供高效的机器学习基础设施
Railyard已经在生产环境中运行了一年半,成为Stripe机器学习团队的主要训练平台。在此期间,基于这一架构训练了数万个模型,总结出以下关键经验:
- **时间序列预测和word2vec风格的嵌入等应用场景。
- 完全托管的Kubernetes集群降低运营负担:Railyard直接与Kubernetes API交互,集群由专门团队管理,使机器学习团队能够专注于核心任务。
- 灵活的集群扩展能力:无论是增加模型训练任务还是需要额外计算资源,集群都能快速扩展以满足需求。
- 集中化的模型状态跟踪与调试:通过作业ID即可快速定位问题,显著提升了调试效率。
- API驱动的模型训练:团队可以通过任何服务、调度器或任务运行器调用Railyard API,轻松集成到现有工作流中。
Railyard的架构设计
在Railyard开发之前,Stripe的工程师和数据科学家通常通过SSH登录到EC2实例,手动启动Python进程来训练模型。这种方式虽然满足了早期需求,但随着公司规模的扩大,逐渐暴露出以下问题:
- 如何从手动训练扩展到每天自动训练数百个模型?
- 如何设计一个通用接口,支持多种训练库、框架和范式?
- 如何跟踪每个模型的训练指标和元数据?
- 如何满足不同模型类型对计算资源(CPU、GPU、内存)的需求?
为了解决这些问题,Railyard的架构设计目标是简化数据科学家的工作流程,让他们专注于核心任务。以下是Railyard的高层架构概览:
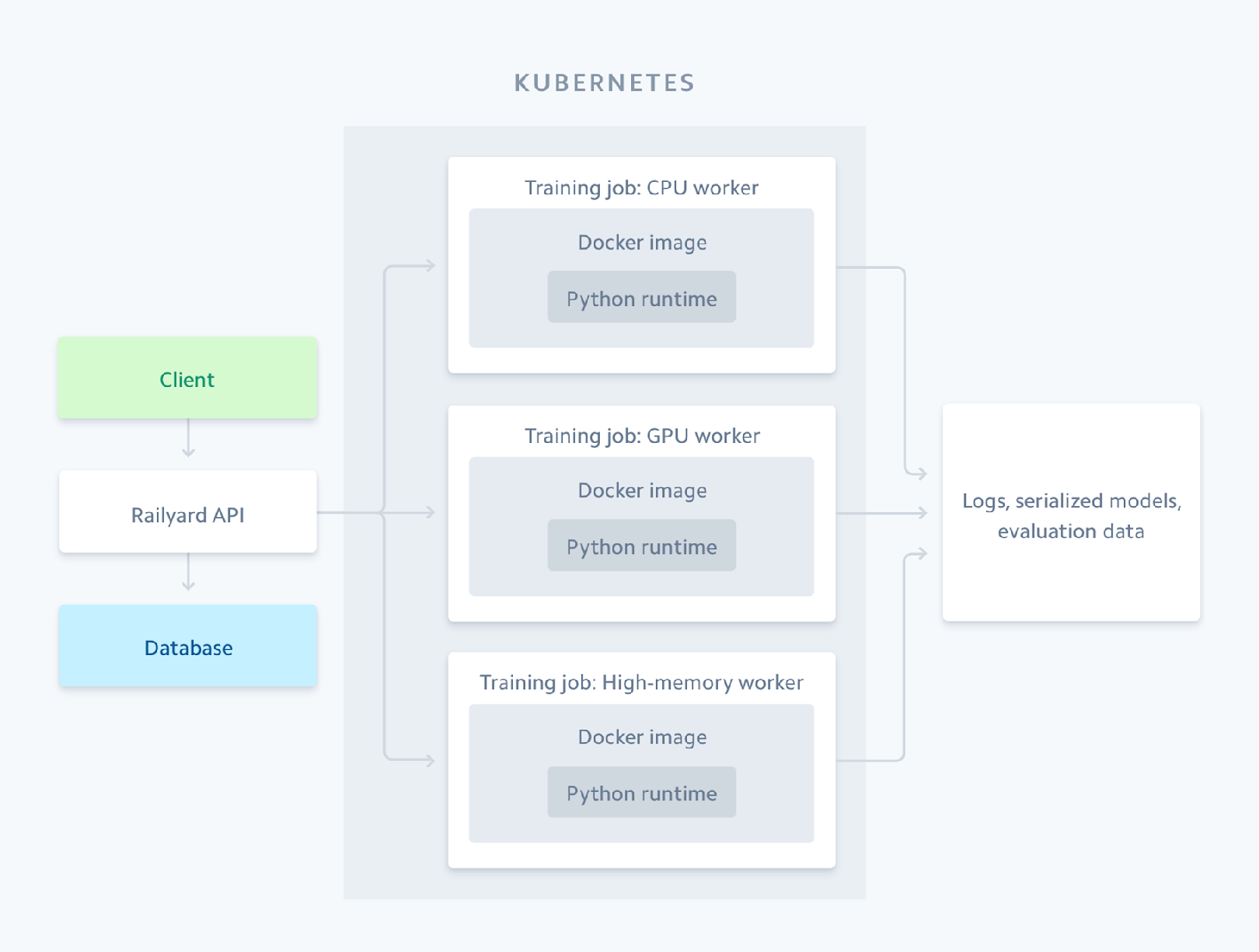
Railyard通过Kubernetes API完成,集群支持多种实例类型,能够根据作业需求分配合适的计算资源。
Railyard API设计
Railyard API允许用户指定模型训练所需的所有参数,包括数据源和模型参数。在设计过程中,团队面临的主要挑战是如何为多个训练框架提供通用接口,同时保持简洁性和表达力。最终的API设计包含以下特点:
- 灵活的模型参数支持:通过一个自由形式的“custom_params”字段,用户可以传递任何有效的JSON参数,满足多样化需求。
- 避免DSL(领域专用语言)设计:Railyard的API专注于核心功能,避免了因框架变化而频繁更新API的复杂性。
- 标准化接口:API提供了fetch_data、预处理、训练和write_evaluation_data等标准接口,支持灵活的数据加载和转换。
以下是一个API请求示例,展示了如何通过Railyard训练模型:
{
"data_source": "s3://example-bucket/data.csv",
"model_params": {
"learning_rate": 0.01,
"batch_size": 128
},
"custom_params": {
"feature_selection": ["feature1", "feature2"]
}
}Python工作流的集成
Railyard支持通过Python工作流定义训练方法,用户可以根据需求自定义数据预处理、训练逻辑和评估方法。例如,深度学习模型可以通过流式传输数据进行训练,最终生成序列化的模型和评估数据。
在设计机器学习API规范时,需要注意以下几点:
- 界面设计的重要性:提供灵活的标准接口,支持用户以多种方式加载和转换数据。
- 简化模型序列化和持久化:减少用户的认知负担,让他们专注于建模和特征工程。
- 细粒度指标收集:为每个训练步骤定义指标,帮助团队快速调试和优化工作流。
基于Kubernetes的扩展能力
Railyard充分利用Kubernetes的灵活性,支持以下功能:
- 快速扩展集群:根据资源需求动态调整实例类型。
- 智能作业调度:通过Kubernetes的亲和性和容忍度机制,将作业分配到合适的节点。
- 支持多种工作负载:针对不同的模型需求,提供CPU、GPU和内存优化实例。
以下是Railyard在Kubernetes上的作业调度示例:
tolerations:
- key: "gpu"
operator: "Exists"
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: "instance-type"
operator: "In"
values:
- "high-memory"通过这些配置,Railyard能够高效地管理资源,确保作业在集群中的最佳分布。
持续优化与未来展望
在过去的一年中,Railyard帮助Stripe团队训练了数千个模型,涵盖从时间序列预测到深度学习的多种用例。以下是一些关键经验:
- 实例灵活性:支持快速添加新实例类型,满足不同工作负载需求。
- 内存密集型工作流管理:通过智能重试和分布式库(如dask-ml),进一步优化内存使用。
- 依赖管理:Subpar在打包Python代码方面表现出色,与Bazel的兼容性尤为突出。
- 团队协作的重要性:Kubernetes团队的支持是Railyard成功的关键。
通过构建通用的机器学习基础设施,Stripe的团队能够专注于本地建模目标,同时实现高效的资源管理和模型优化。未来,Railyard将继续扩展其能力,为更多复杂的机器学习任务提供支持。
原文链接: https://stripe.com/blog/railyard-training-models