一文说尽大语言模型技术之二:LLM的分布式预训练
作者:姚建东 · 2024-08-05 · 阅读时间:11分钟
原文较长,细度之后可以分为三方方面分别深入了解,让我们对大语言模型技术有一个全面的认识,从而对我们研究或定制大语言模型起到抛砖引玉的作用,感谢原博主的整理:
LLM的分布式训练技术概览
在训练大语言模型时,分布式技术发挥着至关重要的作用。数据并行(Data Parallelism)确保多个处理单元同时处理不同的数据子集,显著提高训练速度。张量模型并行(Tensor Model Parallelism)和流水线并行(Pipeline Parallelism)则针对模型的不同部分进行分布式处理,进一步优化了计算资源的利用率。3D并行则进一步拓展了分布式计算的维度。
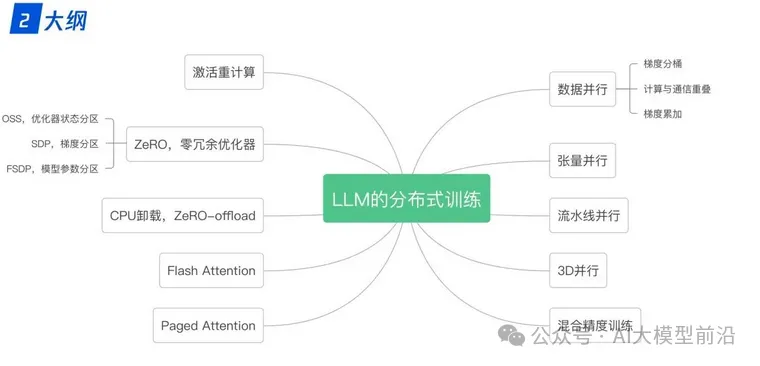
同时,零冗余优化器ZeRO(Zero Redundancy Optimizer)和CPU卸载技术ZeRo-offload,通过减少内存占用和提高计算效率,进一步加速了训练过程。混合精度训练(Mixed Precision Training)则通过结合不同精度的计算,平衡了计算速度与内存占用。激活重计算技术(Activation Recomputation)和Flash Attention、Paged Attention等优化策略,则进一步提升了模型的训练效率和准确性。

2. LLM 的分布式预训练
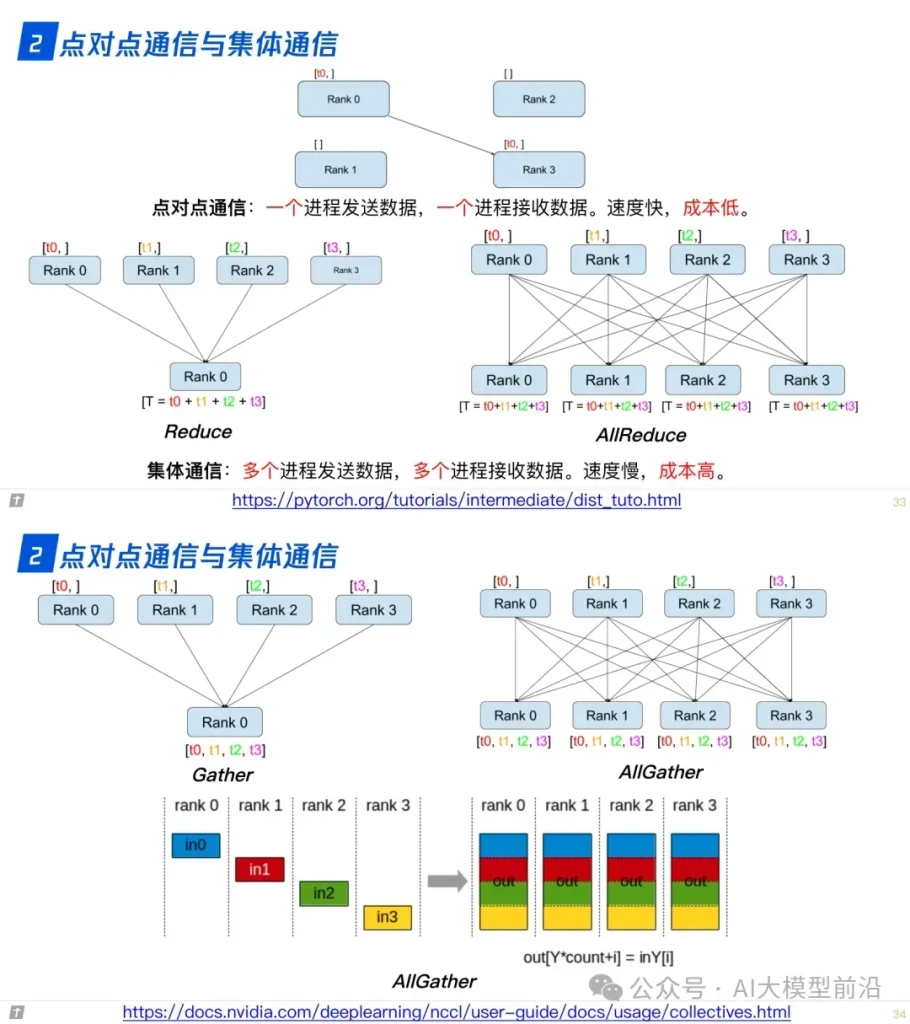
2.0 点对点通信与集体通信
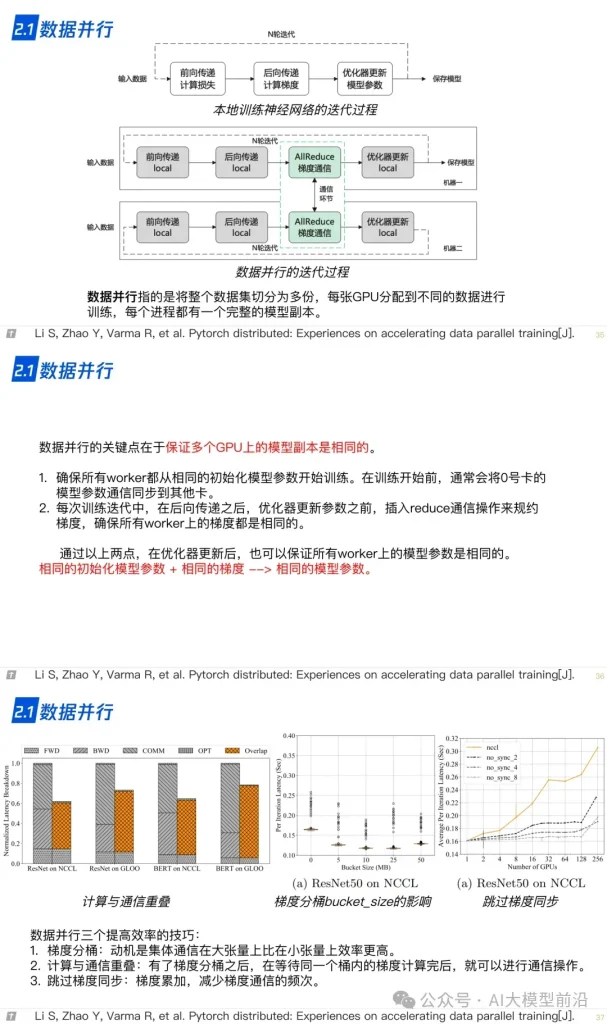
2.1 数据并行
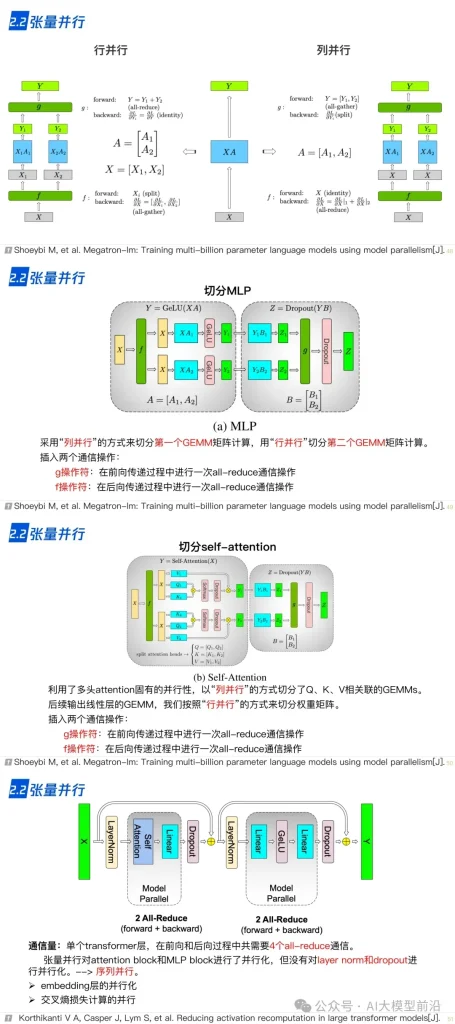
2.2 张量并行

2.3 流水线并行
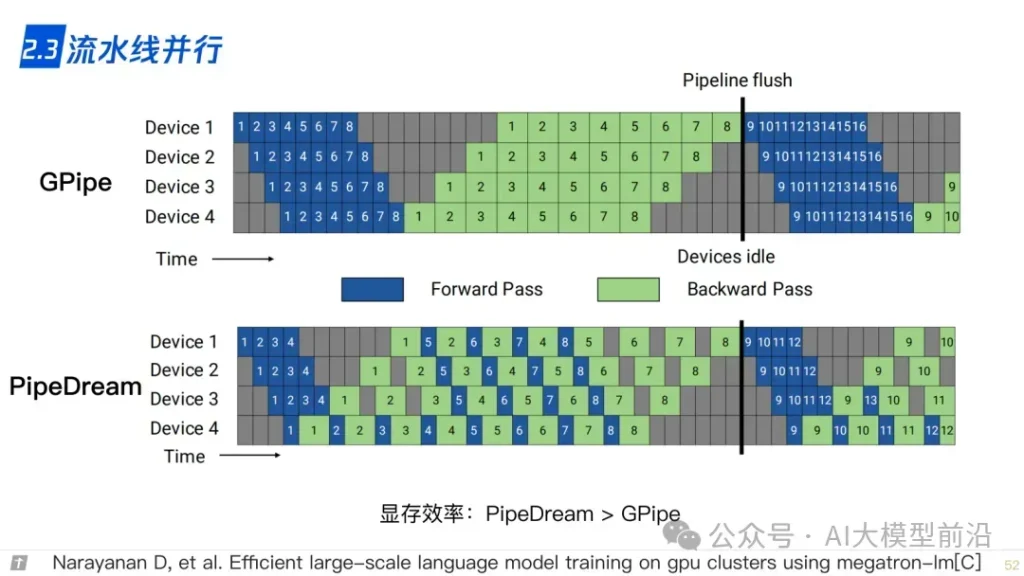
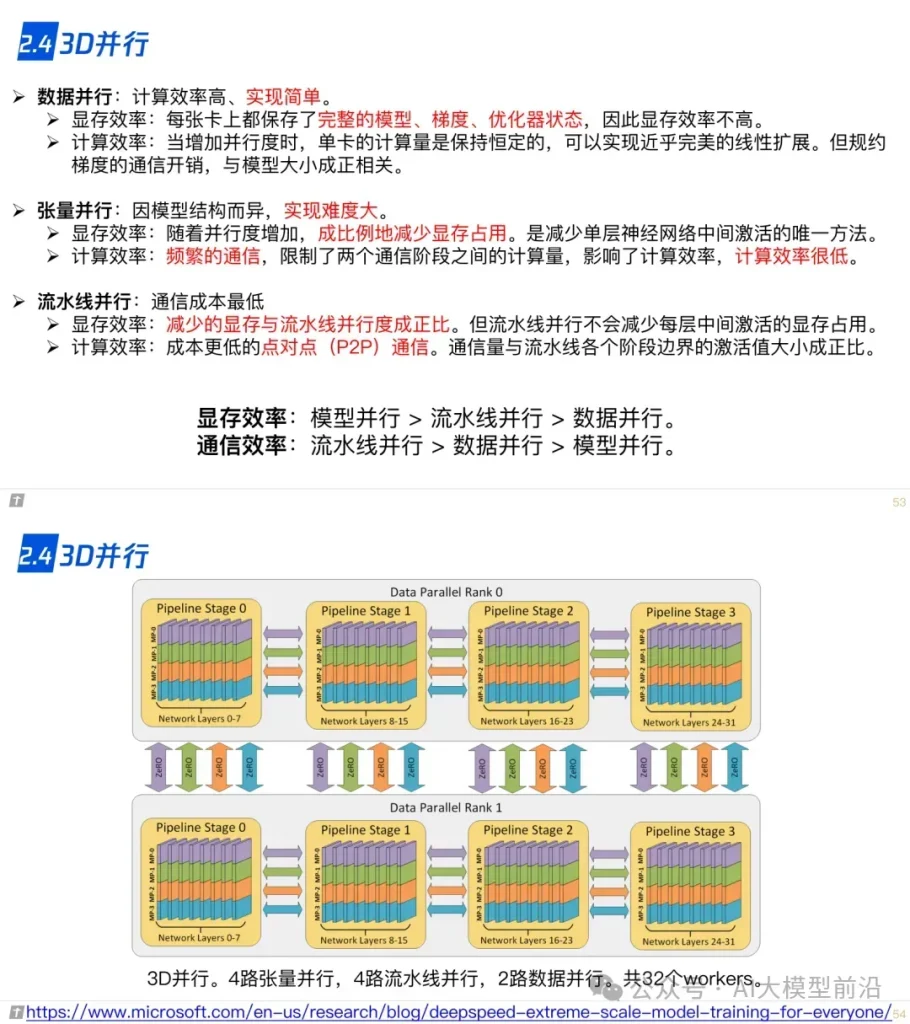
2.4 3D 并行
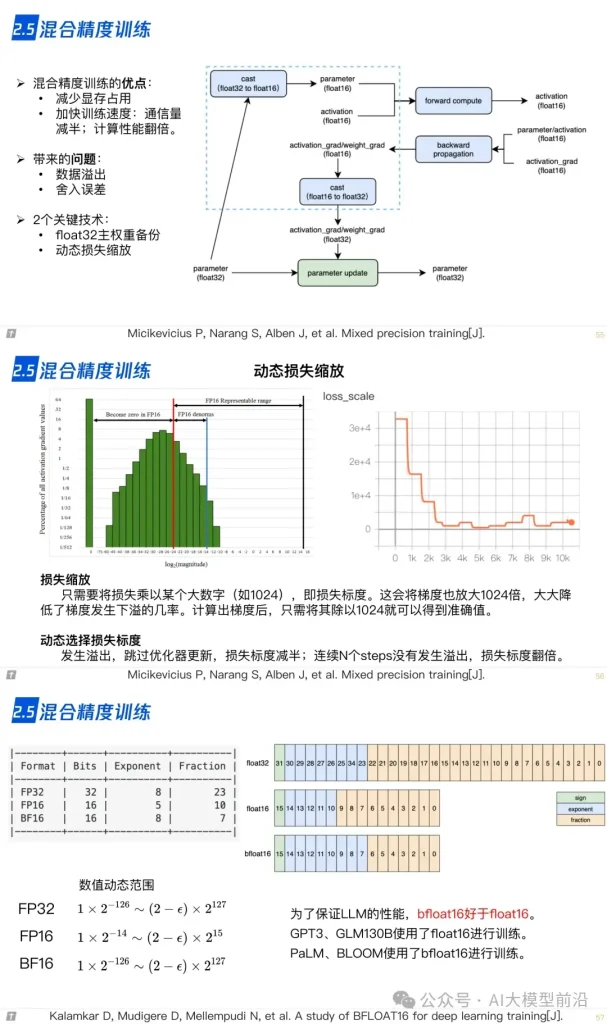
2.5 混合精度训练
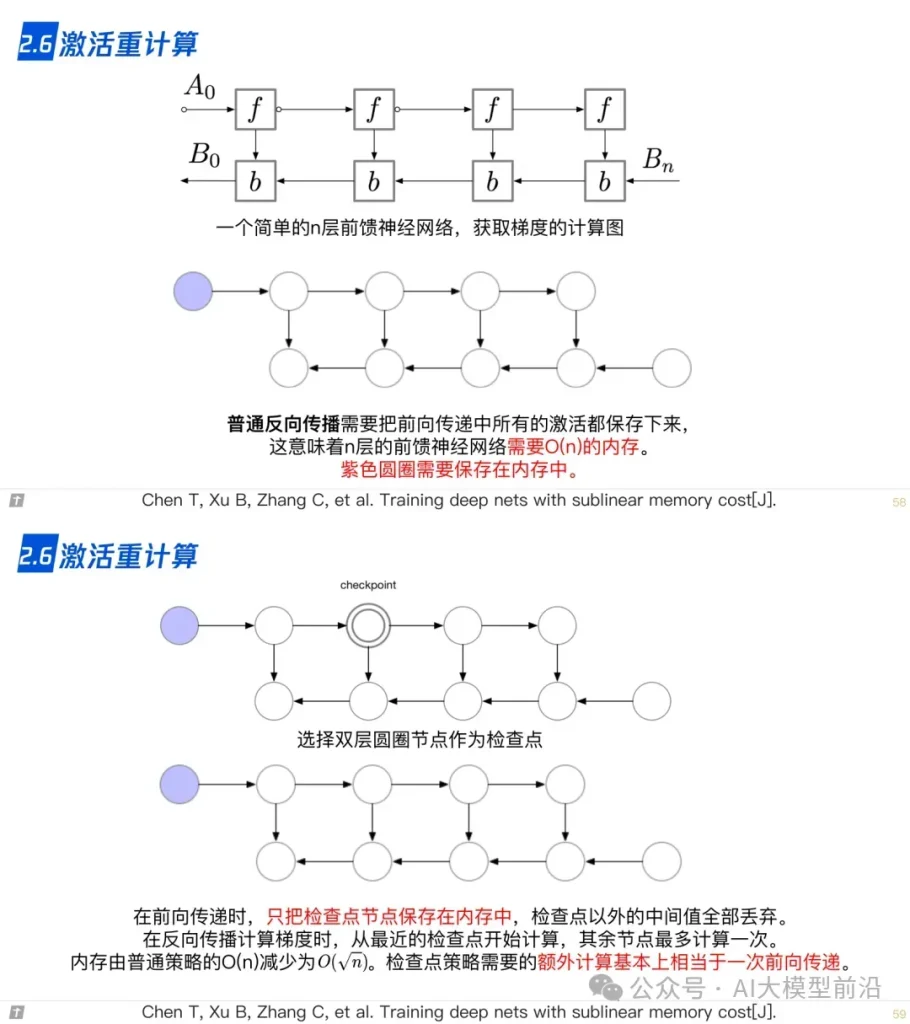
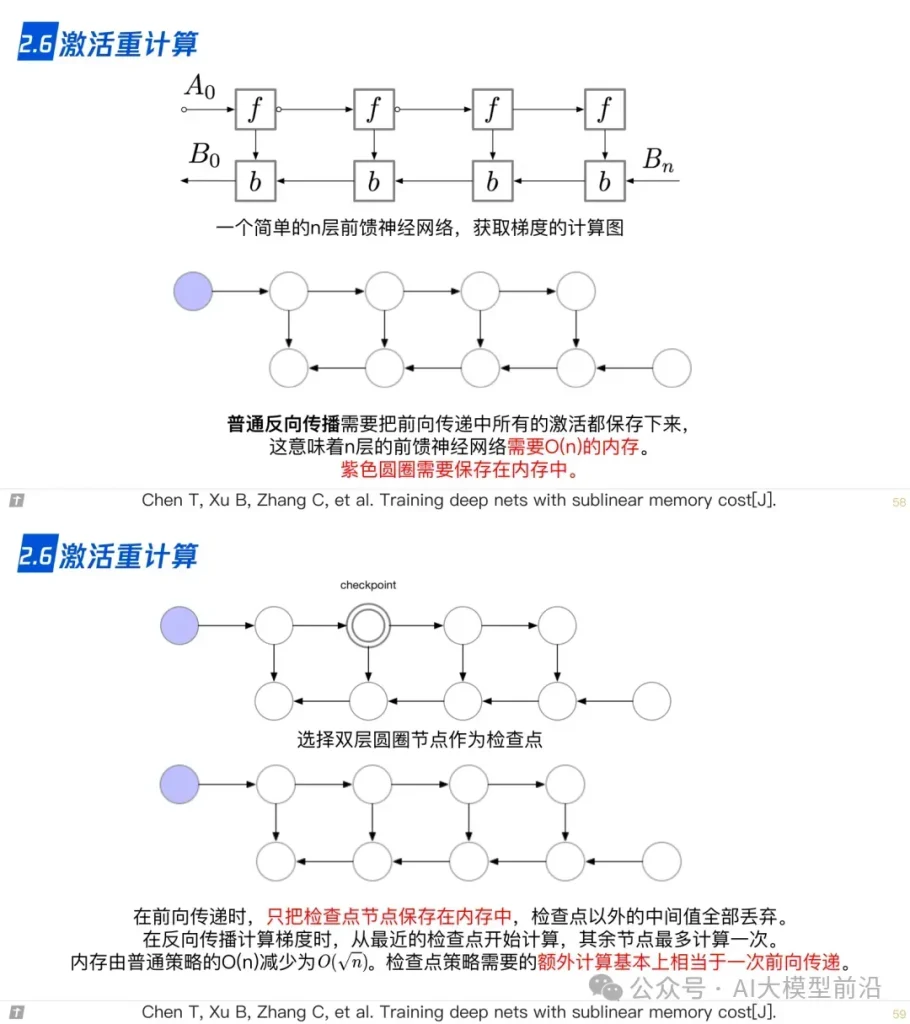
2.6 激活重计算
2.7 ZeRO,零冗余优化器
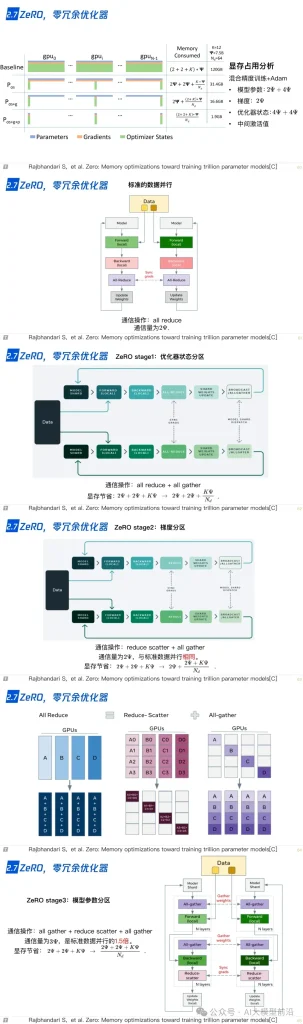
2.8 CPU-offload,ZeRO-offload

2.9 Flash Attention

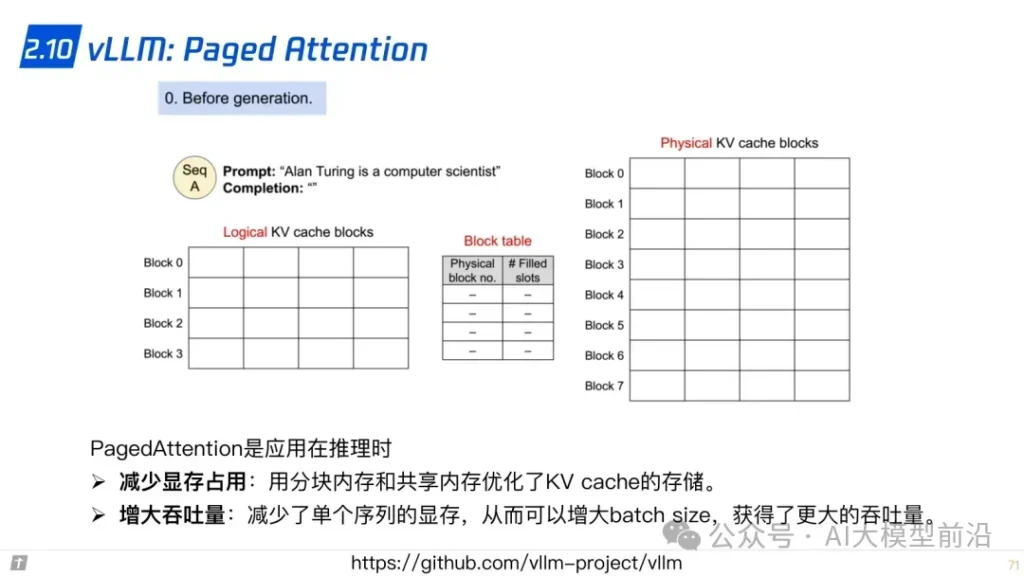
2.10 vLLM: Paged Attention
导读
理解大语言模型,可以从‘LLM的架构、LLL的训练、LLL的微调’三个方面进行,也可以针对需求重点理解一部分。例如,训练+微调,可以读后两篇,只做微调,读最后一篇。
- 一文说尽大语言模型技术之一:LLM的架构
- 一文说尽大语言模型技术之二:LLM的分布式预训练
- 一文说尽大语言模型技术之三:LLM的参数高效微调
参考资料

原文转自 微信公众号@AI大模型前沿
热门推荐
一个账号试用1000+ API
助力AI无缝链接物理世界 · 无需多次注册
3000+提示词助力AI大模型
和专业工程师共享工作效率翻倍的秘密