从案例分析市场调研利器网页抓取API,是否存在风险!
网页抓取API是一种强大的工具,英文全称Web Scraping API,可以帮助企业进行全面的市场调研和对手分析。通过使用网页抓取API,企业可以快速获取大量的网络数据,并进行深入分析,以获得有关竞争对手、市场趋势和消费者行为的宝贵见解,例如:
- 市场调查。要保持竞争优势,公司必须了解自己所在的市场。分析竞争对手的数据和市场趋势有助于作出更加明智的决策。
- 品牌保护。网页抓取对品牌保护十分重要,因为它可以通过采集全网数据来确保在品牌安全方面没有违规行为。
- 价格监控。企业需要随时了解不断变化的市场价格。价格抓取是制定精准定价策略过程中不可或缺的一环。
- SEO监控。网页抓取可以帮助公司收集 搜索引擎结果网页(SERP)中的必要信息,以跟踪公司的排名结果和进展。公司通常会寻求SEO代理来进行SEO监控。
- 评价监控。跟踪客户评价并作出妥善回应可以提高公司的在线声誉,并帮助达成营销目标。
在使用网页抓取之前,大家常常会有如下问题:
- 网页抓取API是网络爬虫的一种吗?答:否
- 网页抓取API是否存在风险?答:是
怎么办?看到结论还要继续?往下看。
什么是网页抓取API?
网页抓取(即网络抓取、网站抓取、网络数据提取)是指从目标网站收集公共网络数据的自动化流程。不必手动采集数据,使用网页抓取工具几秒钟就可以获取大量信息。一般有两种方式获取该服务:
1、自建网络爬虫
网络爬虫是用于完成数据采集任务的特定工具。它能够向目标网站发出请求并从中提取信息。先进的网络爬虫还可以解析所需数据。
自建网络爬虫需要经验丰富、熟练掌握特定编程知识的开发团队。Python是其中最常用的编程语言。此外,如果选择自建,还要确保为开发人员提供各种必要资源。例如,IP代理维护、IP拦截、CAPTCHA验证和其他挑战。
2、使用三方网页抓取API
市场上有许多三方网页抓取API服务商,很适合中小企业或研发能力弱的企业使用,因为它们解决了很多技术难题。幂简集成整理了一些API服务商清单:
网页抓取与网页爬取的差异是什么?
“网页抓取”(Web Scraping)和”网页爬取”(Web Crawling)这两个术语经常被交替使用,它们都涉及到从互联网上自动获取信息。尽管它们在某些方面有相似之处,但它们在目的、方法和应用场景上存在一些区别:
| 网页抓取 | 网页爬取 | |
| 目的 | 主要目的是从网站上提取特定数据,如价格、评论、联系方式等,通常是为了分析或再利用这些数据 | 主要目的是发现和索引网页,以便搜索引擎能够检索到这些页面 |
| 技术 | 通常使用脚本或软件工具,模拟浏览器行为,解析HTML页面,提取所需的信息 | 使用爬虫(Crawler)或机器人(Bot),遵循网站的链接结构,访问和索引网页 |
| 内容过滤 | 选择性:抓取过程更具有选择性,只关注和提取页面中特定的数据片段 | 全面性:爬取过程更全面,旨在覆盖尽可能多的网页,以便构建完整的索引 |
| 应用场景 | 常用于市场调研、数据分析、信息聚合服务等 | 主要用于搜索引擎 |
| 法律和道德问题 | 可能涉及隐私和版权问题,尤其是在未经网站所有者同意的情况下抓取数据 | 搜索引擎爬虫通常会遵守robots.txt文件中的规则,尊重网站的爬取政策。非法爬虫也是存在的 |
网页抓取API是否存在风险?
网页抓取的合法性是个热门话题,对企业来说尤其重要,非常容易触发数据隐私、知识产权等方面法律和法规,例如:
- 1、侵犯隐私:如果API抓取了包含个人信息的网页,可能会侵犯个人隐私。
- 2、违反数据保护法规:许多国家和地区有严格的数据保护法规,如欧盟的通用数据保护条例(GDPR),网页抓取可能会违反这些法规。
- 3、知识产权/版权问题:网页上的内容可能受版权保护,未经授权的抓取和使用可能侵犯版权。
- 4、用户同意缺失:在没有获得数据所有者的明确同意的情况下抓取和使用数据,可能违反隐私政策和用户协议。
- 5、服务条款违规:许多网站在其服务条款中明确禁止未经授权的数据抓取,使用API抓取这些网站的数据可能违反服务条款。
如何规避?建议在开始进行网页抓取前,要了解以下事项:
- 了解版权政策,尽管是采集公共数据,也要确保遵守这类数据的适用法律,例如下载受版权保护的数据。
- 研究robots.txt,这是网站所有者对爬虫访问权限的指示。
- 研究授权政策,如果可能,直接与网站所有者联系。
- 隐私保护,避免登录网站来获取所需信息,因为这样做,您势必接受服务条款或其他法律协议,而这样可能会禁止自动数据采集流程。
网页抓取API案例研究
本文主要用Scraperbox 公司提供的网页抓取API示例使用过程。一般网页抓取API包括如下几个过程:抓取 –> 解析 –> 结构化存储 –>数据分析。
假定抓取Amazon竞品的商品信息
抓取工具一般会遇到很多这样的“机器人检查”页面,也是自研网页抓取API需要解决的第一个问题。
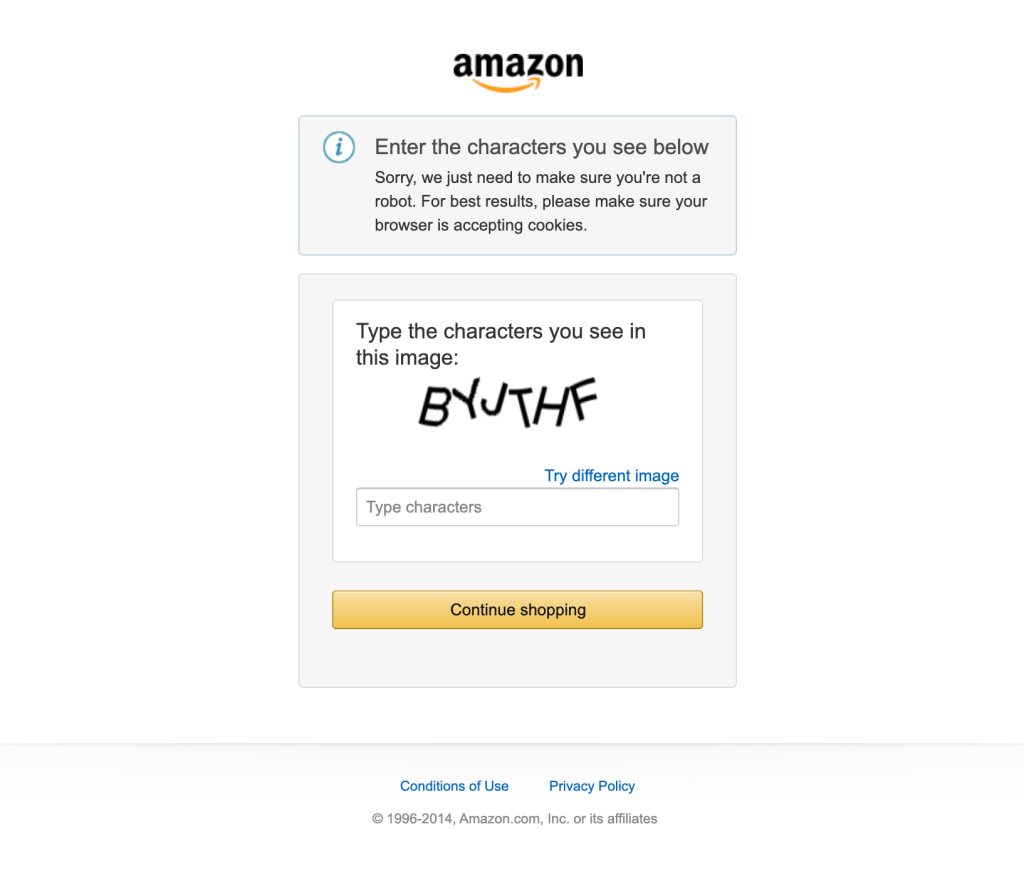
抓取:编写程序,集成网页抓取API
对于此示例,让我们创建一个调用 ScraperBox API 的 Python 程序,确保YOUR_API_KEY用您的 API 密钥替换:
import urllib.parse
import urllib.request
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
# Urlencode the URL
url = urllib.parse.quote_plus("https://www.amazon.com/Edward-Tools-Bend-proof-Garden-Trowel/dp/B01N297HU0")
# Create the query URL.
query = "https://api.scraperbox.com/scrape"
query += "?api_key=%s" % "YOUR_API_KEY"
query += "&url=%s" % url
# Call the API.
request = urllib.request.Request(query)
raw_response = urllib.request.urlopen(request).read()
html = raw_response.decode("utf-8")
print(html)解析:从 HTML 中提取数据
几乎每种编程语言都有一个 dom 解析器包。在我们的例子中,使用 Pyhton BeautifulSoup包:
# Rest of the code here
# Setup beautifulsoup
soup = BeautifulSoup(html, 'html.parser')
# Find the element
title_element = soup.select_one("#title")
# Get the text content
title = title_element.getText().strip()
print("Title=" + title)结构化存储:将数据按照分析要求存储在DB
将上面解析来的数据,结构化存储到数据库,例如商品综合信息表 (product_overview):
| 字段名 | 数据类型 | 键 | 描述或约束 |
|---|---|---|---|
| product_id | INT或BIGINT | 主键 | 唯一标识,主键约束 |
| asin | VARCHAR(10) | 亚马逊标准识别码,唯一 | |
| title | VARCHAR(255) | 商品标题 | |
| brand | VARCHAR(100) | 品牌名称 | |
| price | DECIMAL(10, 2) | 商品价格,保留两位小数 | |
| currency | VARCHAR(3) | 货币单位,如”USD” | |
| rating | DECIMAL(3, 2) | 评分,保留两位小数 | |
| review_count | INT | 评论数量 | |
| category_name | VARCHAR(100) | 分类名称,外键来自Categories表 | |
| description | TEXT | 商品描述,文本类型 | |
| inventory_quantity | INT | 库存数量 | |
| warehouse | VARCHAR(100) | 仓库位置 |
数据分析:Excel或BI工具
数据量小的情况下,直接使用Excel,简单又快捷;数据量比较大时,可以使用BI工具,甚至将AI+BI结合起来,更高效的产出研究报告。
网页抓取API还能用?
经过上面的分析及案例,可以看到如下结论:按照上文讲述的规则来用,是没有风险的,也是正常的商业手段。
自建网页抓程序取所依赖的API怎么找?
用幂简集成搜索API最方便!幂简集成专注于为开发者提供全面、高效、易用的API平台解决方案。幂简API平台提供了多种维度发现API的功能:通过关键词搜索API、从API Hub分类浏览API、从开放平台分类浏览企业间接寻找API等。
此外,幂简集成开发者社区会编写API入门指南、多语言API对接指南、API测评等维度的文章,让开发者选择符合自己需求的API。