扩散模型理论在生成式AI中的应用
文章目录
扩散模型理论在生成式AI中日益受到关注,其通过逐步添加和去噪高斯噪声来生成数据,与GAN和VAE等模型相比,具有无对抗性和高维隐空间的优势。本文详细解析了扩散模型在图像生成中的基本原理和实现方法,结合最新的研究成果,如DALL·E 2和Imagen,阐述了扩散模型在AI+艺术领域的应用潜力。
DiffusionModel基本介绍
发展背景
扩散模型(Diffusion Models)在生成模型领域的重要性日益增长。尽管最初未受到广泛关注,但随着OpenAI的DALL·E 2和Google的Imagen的成功应用,扩散模型逐渐走入大众视野。这些模型通过扩散过程生成高质量图像,展示了其在图像合成方面的潜力。

扩散模型的原理
扩散模型的核心是通过添加噪声的方式破坏数据,然后逆向去噪以恢复数据。其过程可以视为一种马尔可夫链,逐渐将图像转换为纯噪声,最后通过逆过程生成新图像。
关键特性
与GAN和VAE等生成模型不同,扩散模型依赖固定的过程来学习,隐变量空间的维度较高,这使得模型在生成复杂图像时表现出色。此外,扩散模型的训练过程相对不需要对抗性训练,避免了GAN中常见的调试难题。
生成模型对比
GAN与扩散模型
生成对抗网络(GAN)通过生成器和判别器的对抗过程实现数据生成。虽然GAN在生成逼真图像方面表现优异,但对抗过程使得训练不稳定。扩散模型则通过固定的噪声添加和去噪过程,提供了一种更为稳定的生成方法。
VAE与扩散模型
变分自编码器(VAE)通过生成隐变量z来实现数据生成。与VAE相比,扩散模型通过马尔可夫链和高斯噪声,提供了更高维度的隐空间,这使得其在复杂数据的生成上具有优势。
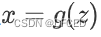
Flow-based Models与扩散模型
Flow-based Models通过可逆的变换实现数据生成,与扩散模型的固定过程不同。扩散模型通过连续添加噪声,再逆向去噪,提供了一种新颖的数据生成方式。
直观理解Diffusionmodel
概念阐述
生成模型本质上是一组概率分布。扩散模型通过噪声扰动,将数据从有序的分布转变为无序的噪声分布,然后逆向恢复。这种过程可以直观地理解为从噪声中构建数据样本。
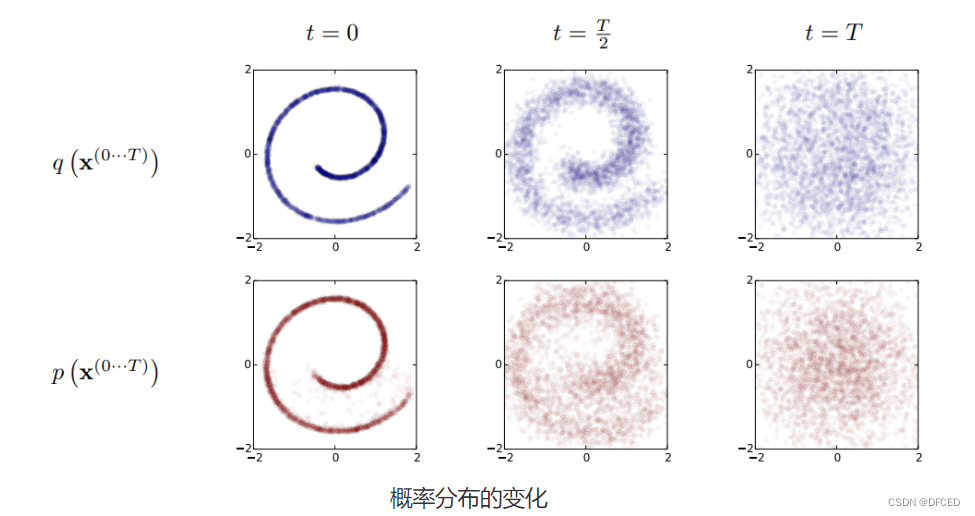
过程解析
在扩散过程中,数据不断被噪声化,直到形成纯噪声。逆扩散过程则是从噪声逐步去噪,恢复至原始数据或生成新的数据。
应用实例
通过扩散模型,我们可以从噪声分布中采样,生成高质量的图像。这一过程不仅适用于图像生成,还可扩展至其他领域,如文本和音频生成。
形式化解析Diffusionmodel
马尔可夫链的应用
扩散模型采用马尔可夫链进行数据映射。在每个时间步中,噪声逐步添加到数据中,形成后验概率。这一过程在模型训练中尤为关键。

后验概率和马尔可夫性质
后验概率在贝叶斯统计中用于描述条件概率,而马尔可夫链强调无记忆性。这些概念构成了扩散模型的理论基础,指导模型在噪声和数据之间进行有效转换。
逆过程的实现
通过训练逆扩散过程,扩散模型能够从噪声中生成逼真的图像。与GAN不同,扩散模型不依赖对抗性训练,提供了一种更为稳定和可控的生成方式。
Diffusion前向过程扩散过程
正向过程详解
在正向扩散过程中,数据逐步被高斯噪声扰动。这一过程可以通过马尔可夫链的方式进行描述,每一步都将数据推向完全噪声化的状态。
数据扰动的效果
正向过程的目标是将数据转换为标准的高斯噪声分布。通过这一过程,扩散模型能够有效地学习数据的内在结构,为逆向生成奠定基础。

关键算法
import torch
import torch.nn as nn
class DiffusionModel(nn.Module):
def __init__(self):
super(DiffusionModel, self).__init__()
# 初始化模型参数
def forward(self, x):
# 实现正向扩散过程
return xDiffusion逆扩散过程
逆向过程详解
逆扩散过程旨在从纯噪声中恢复数据。通过学习噪声的逆向转换,扩散模型能够生成与训练数据相似的新样本。

去噪过程
在逆扩散过程中,模型逐步去除噪声,恢复数据的细节。这一过程依赖于对正向过程的有效学习,确保生成结果的质量。
模型训练
逆扩散过程的训练通常涉及大量的数据迭代和优化,确保模型能够准确地从噪声中恢复数据。
训练损失
损失函数设计
扩散模型的训练损失通常涉及到对去噪精度的评估。通过优化损失函数,模型能够更好地学习噪声和数据之间的映射关系。

训练策略
在训练过程中,合理的损失函数设计可以显著提高模型的生成效果。通常采用的策略包括最小化噪声残差等。
优化方法
常用的优化方法包括随机梯度下降等,通过有效的优化算法,模型能够快速收敛至理想状态。
参考文献
- Denoising Diffusion Probabilistic Models
- Diffusion Models Beat GANs on Image Synthesis
- Deep Unsupervised Learning using Nonequilibrium Thermodynamics
FAQ
问:扩散模型的基本原理是什么?
- 答:扩散模型通过添加噪声的方式破坏数据,然后通过逆向去噪以恢复数据。整个过程可以视为一种马尔可夫链,从而逐渐将数据转换为纯噪声,最终通过逆向生成高质量的新图像。
问:扩散模型与GAN相比有哪些优势?
- 答:扩散模型与生成对抗网络(GAN)不同,其依赖于固定的噪声添加和去噪过程,不需要对抗性训练。这种固定的过程使得扩散模型提供了一种更为稳定的生成方法,避免了GAN中常见的训练不稳定问题。
问:扩散模型如何与VAE进行比较?
- 答:与变分自编码器(VAE)相比,扩散模型通过马尔可夫链和高斯噪声提供了更高维度的隐空间,这使得其在生成复杂数据时具有更好的表现。VAE通过生成隐变量z来实现数据生成,而扩散模型则通过噪声扰动和逆向去噪实现。
问:扩散模型的训练损失如何设计?
- 答:扩散模型的训练损失通常涉及对去噪精度的评估。通过优化这些损失函数,模型能够更好地学习噪声和数据之间的映射关系,常用的训练策略包括最小化噪声残差等。
问:扩散模型在实际应用中有哪些实例?
- 答:扩散模型在图像生成方面显示了强大的能力,例如OpenAI的DALL·E 2和Google的Imagen。这些模型通过扩散过程生成高质量图像。此外,扩散模型的应用还可扩展至其他领域,如文本和音频生成。
最新文章
- Python应用 | 网易云音乐热评API获取教程
- 22条API设计的最佳实践
- 低成本航空公司的分销革命:如何通过API实现高效连接与服务
- 实时聊天搭建服务:如何打造令人着迷的社交媒体体验?
- 简化API缩写:应用程序编程接口终极指南
- Mono Creditworthy API 集成指南|实时评估用户信用状况
- Gcore 收购 StackPath WAAP,增强全球边缘Web应用与API安全能力
- 免费IPv6地址查询接口推荐
- 什么是Unified API?基于未来集成的访问
- 使用JWT和Lambda授权器保护AWS API网关:Clerk实践指南
- 宠物领养服务:如何帮流浪毛孩找到温馨的新家?
- Python调用IP地址归属地查询API教程