Slack宕机原因分析——API智能如何提供帮助
摘要
2025年2月26日,Slack经历了一次重大宕机事件,导致数千名用户的通信中断。经过调查,问题的根本原因被追溯到数据库分片故障,进而引发API崩溃。这次中断持续了约10个小时,影响了Slack的多个核心功能。
API智能在此次事件中展现了其潜在的重要性。通过检测错误峰值和流量异常等预警信号,API智能有助于在问题扩大前采取有效措施。本文将深入分析此次事件的细节,探讨API智能如何帮助防止类似中断,并阐述主动可观察性在保护数字服务中的关键作用。
出了什么问题?
Slack的宕机始于美国东部时间上午10:30左右,用户开始报告无法连接平台。在高峰期,Downdetector上记录了3099份相关报告。用户反馈的问题主要集中在登录、消息传递、应用程序集成、API以及工作流功能上。
根据Slack官方的调查,问题的根源在于数据库分片的故障。数据库分片是处理和分发数据请求负载的关键组件,由于分片出现意外错误,连接前端接口与后端基础设施的API随之崩溃,导致服务大范围中断。
Slack官方状态页面显示,从问题调查到完全恢复,整个过程耗时约10个小时。
API智能的重要性
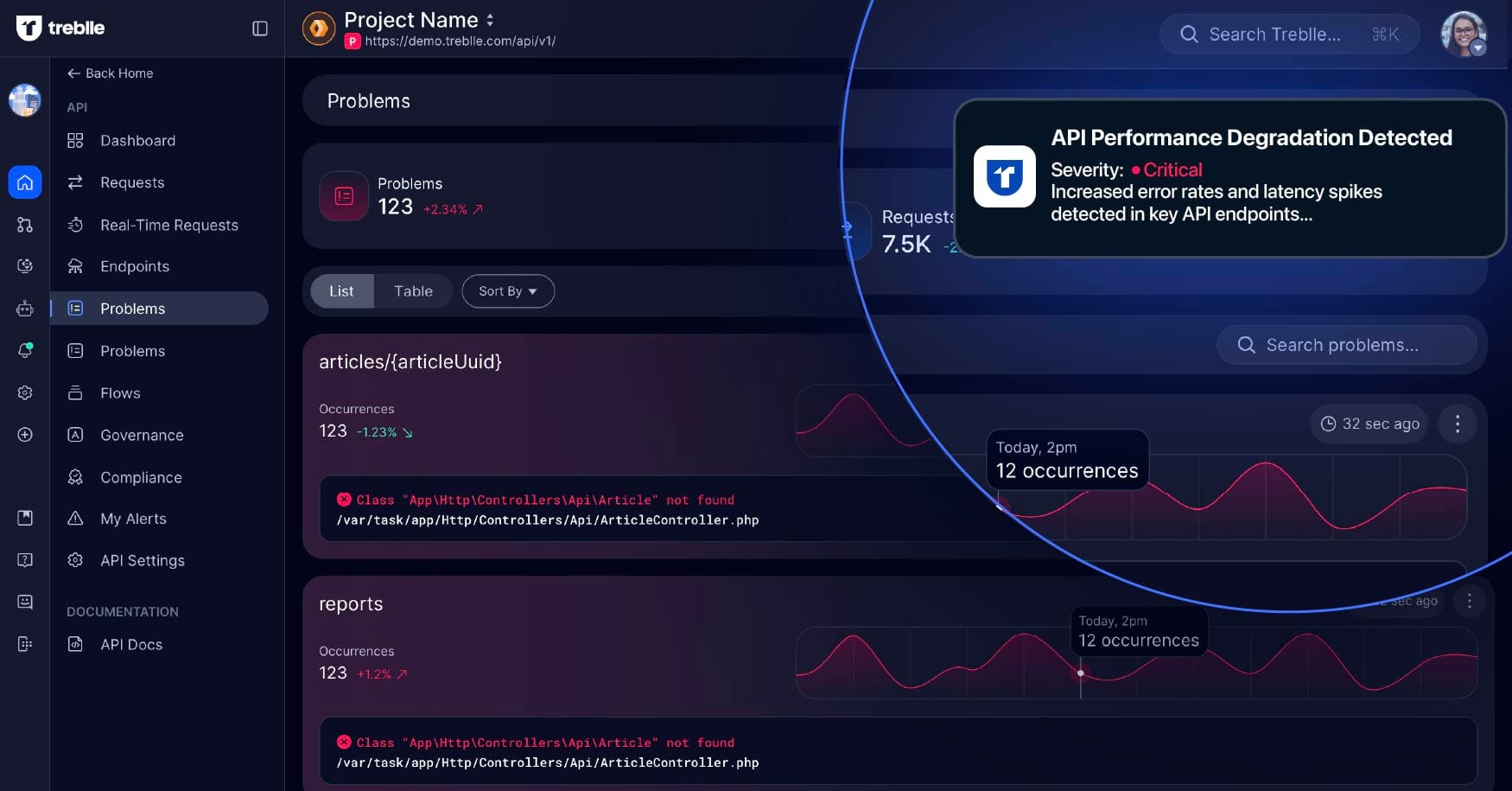
此次事件凸显了API智能在现代数字生态系统中的重要性。API智能的核心在于实时可观察性、分析能力以及对系统间数据交换的高效管理。通过API智能,组织可以实时监控API的性能和运行状况,提前发现并解决潜在问题,避免问题升级为全面宕机。
强大的API智能系统能够捕捉到以下早期预警信号:
- 错误率突然增加:API请求失败的数量显著上升。
- 意外的延迟峰值:响应时间异常变长,可能预示后端存在问题。
- 异常的流量模式:API调用量的异常激增或下降。
这些指标可以作为数字生态系统潜在问题的早期警报,帮助企业主动排查故障,而不是被动应对危机。
常见的API智能策略
一个全面的API智能策略通常包括以下几个关键组成部分:
- 实时可观察性:持续监控API流量、响应时间和错误率,识别异常模式。
- 完整日志记录:捕获每个请求和响应的详细日志,为问题溯源提供数据支持。
- 自动警报:当系统检测到异常超过设定阈值时,自动触发警报,及时通知相关团队。
- 性能分析:通过分析API使用模式和响应指标,了解正常运行条件,并快速发现偏差。
API智能在何处发挥作用?
API智能的高精度监控能力使其能够近乎实时地识别和解决潜在问题,从而避免类似Slack宕机的情况发生。以下是API智能平台可以检测到的典型早期预警信号:
- 错误率飙升:API请求失败率突然增加。
- 意外的延迟峰值:响应时间显著变慢,可能表明后端系统存在性能瓶颈。
- 异常流量模式:API调用量的异常波动可能预示潜在的安全风险或服务问题。
通过及时发现这些异常,企业可以有效防止API滥用,避免因滥用导致的安全风险和服务中断。
接下来是什么?
Slack的这次宕机事件为所有依赖API驱动架构的企业敲响了警钟。它提醒我们,部署强大的API智能解决方案至关重要。这些解决方案能够提供持续的可观察性和主动的错误检测,帮助企业提高系统的可靠性和用户满意度,同时维护企业在数字化时代的信任与声誉。
虽然没有任何系统能够完全避免意外问题,但投资于API智能能够有效降低重大服务中断的风险。随着数字生态系统的日益复杂,API智能的作用将愈发重要。通过采用这些技术,企业可以更好地应对未来的挑战,确保其数字服务的稳定性和安全性。
原文链接: https://blog.treblle.com/slack-outage-api-failures/