生成式AI中的LLM偏移与提示工程优化:链式结构与级联效应解析
LLM偏移、提示偏移与级联
在使用大型语言模型(LLM)时,尽管措辞可能有所不同,但基本事实通常保持不变。然而,在某些情况下,LLM的响应可能会出现偏差。这种偏差可能源于模型的弃用或迁移,例如最近OpenAI弃用了一些模型的情况。在这种情况下,虽然提示内容保持不变,但底层模型却发生了变化。
此外,在推理(inference)过程中,注入到提示中的数据也可能有所不同。这些因素共同导致了一种被称为“瞬时漂移”的现象。
瞬时漂移与提示管理
瞬时漂移是指由于模型的变化或提示数据的不同,导致生成结果出现偏差。为了解决这一问题,市场上已经出现了一些开源的提示管理和测试接口,以及相关的商业产品。这些工具的目标是确保生成应用程序(Gen Apps)能够在LLM迁移或弃用之前进行充分测试。
理想情况下,一个模型应该尽可能对底层模型的变化保持不敏感。实现这一目标的一个方法是利用大型语言模型的上下文学习(ICL)能力,通过动态调整提示内容来适应不同的模型。
级联效应的影响
级联效应是指在链式应用程序中,一个节点引入的异常或偏差会被传递到下一个节点,并可能在传递过程中被放大。这种现象会导致每个节点的输出逐渐偏离预期结果。
例如,在链式应用程序中,用户的输入可能是意外的或未计划的,这会导致节点产生意外的输出。如下图所示:
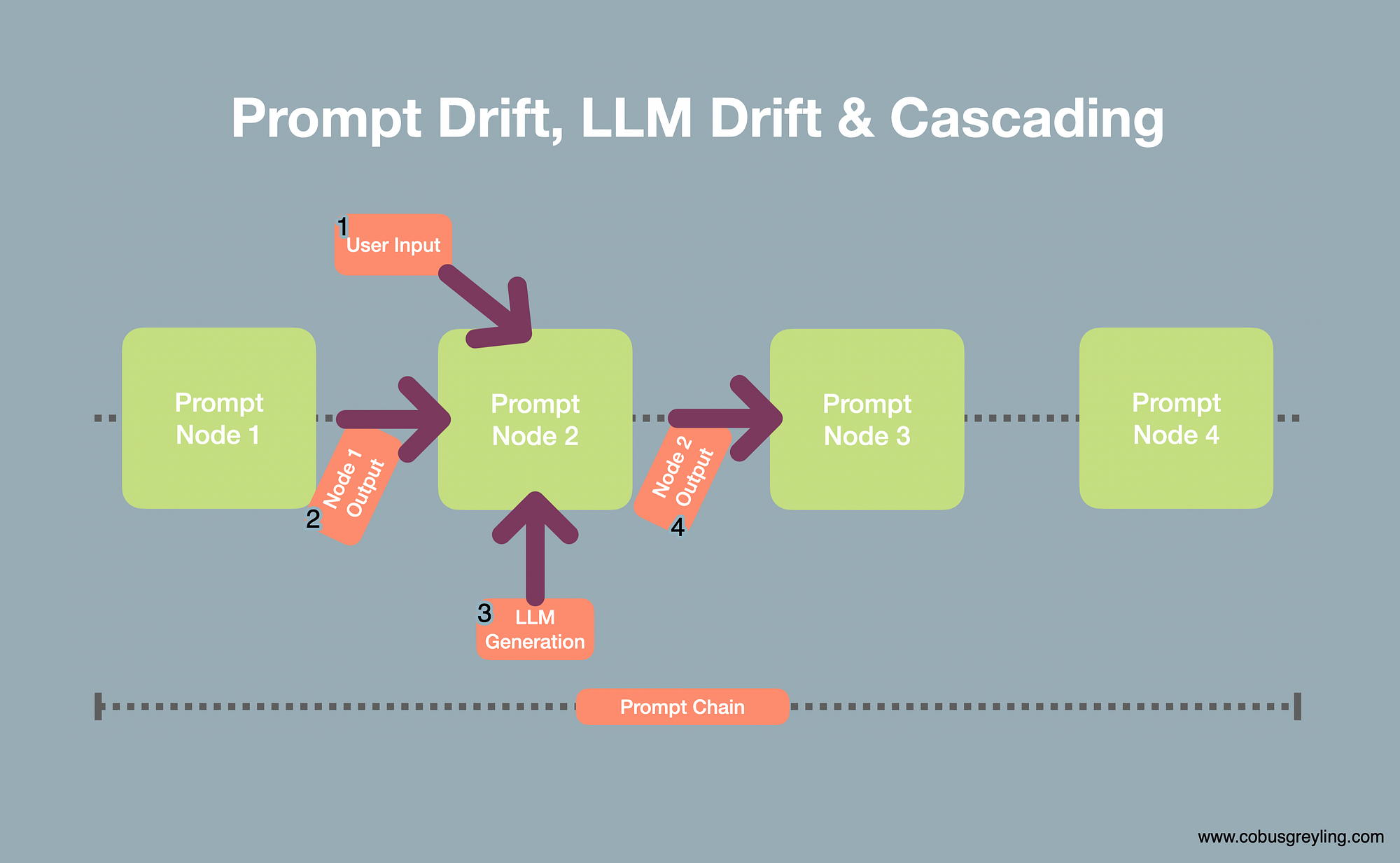
提示工程与链式结构
Prompt Engineering)是链式应用程序的基础。它不仅仅是单一的技术,而是由多个分支组成的学科。提示工程的措辞和技巧对生成结果的质量有着显著影响。
随着LLM技术的发展,提示工程正变得更加可编程。例如,通过检索增强生成(RAG)技术,可以在提示中动态注入模板和上下文信息。此外,提示工程还被集成到更复杂的结构中,例如代理、管道和思维链推理等。
这些技术的结合,使得链式结构的应用更加灵活和高效,为解决复杂问题提供了强大的支持。
总结
LLM的偏移、提示偏移以及级联效应是生成式AI应用中需要重点关注的问题。通过有效的提示管理、上下文学习能力以及提示工程的优化,可以在一定程度上缓解这些问题。同时,随着技术的不断发展,链式结构和提示工程的结合将为生成式AI的应用带来更多可能性。
原文链接: https://blog.kore.ai/cobus-greyling/llm-drift-prompt-drift-cascading