
Avro编码的用途和价值?
Avro 是一个开源项目,用于为 Hadoop 提供数据序列号和数据交换服务,是Spark(Apache Spark是一种用于大型数据集的开源数据处理引擎。 它旨在提供大数据所需的计算速度、可扩展性和可编程性,特别适用于流数据、图形数据、机器学习和 人工智能 应用程序。) 内嵌的数据处理格式。 这些服务可以一起使用,也可以单独使用。 Avro 简化了在以任何语言编写的程序之间交换大数据的过程。 借助序列化服务,程序可以将数据高效地序列化为文件或消息。 数据存储非常紧凑且高效。 Avro 将数据定义和数据存储在一条消息或一个文件中。
Avro 以 JSON 格式存储数据定义,使其便于阅读和解释;数据本身以二进制格式存储,以达到紧凑且高效的目的。 Avro 文件包含可用于将大型数据集拆分为适用于 Apache MapReduce 处理的子集的标记。 一些数据交换服务使用代码生成器来解释数据定义并生成代码以访问数据。 Avro 不需要此步骤,因而成为脚本编制语言的理想之选。
Avro 的一个主要功能是可对随时间变化的数据模式(通常称为模式演进)提供强大支持。 Avro 可处理类似缺少字段、添加字段和更改字段等的模式更改;因此,原有程序可读取新数据,新程序也可以读取原有数据。 Avro 包含适用于 Java、Python、Go、C、C++ 等的 API。 通过 Avro 存储的数据可从不同语言编写的程序进行传递,甚至从诸如 C 这样的编译式语言传递到 Apache Pig 一类的脚本语言。
Avro为什么被大数据选为默认格式?
Avro 格式以 JSON 格式存储模式,使其易于被任何程序读取和解释。
数据本身以二进制格式存储,使其在 Avro 文件中紧凑且高效。
Avro格式是语言中立的数据序列化系统。它可以被多种语言处理(目前是 C、C++、C#、Java、Python 和 Go)。
Avro 格式的一个关键特性 是对随时间变化的数据模式的强大支持,即模式演变。Avro 处理模式更改,例如缺少字段、添加的字段和更改的字段。
Avro 格式提供了丰富的数据结构。例如,您可以创建包含数组、枚举类型和子记录的记录。
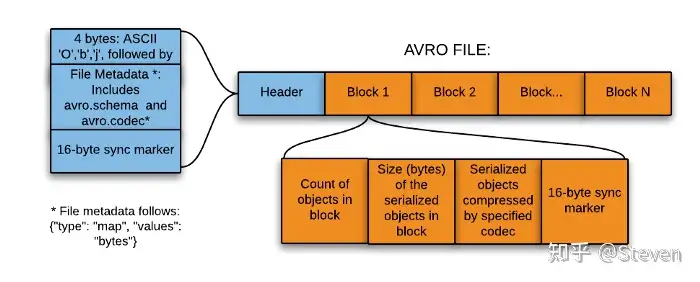 Avro 格式是在数据湖登陆区存储数据的理想选择,因为:
Avro 格式是在数据湖登陆区存储数据的理想选择,因为:
1.落地区的数据通常被整体读取,以供下游系统进一步处理(这种情况下基于行的格式效率更高)。
-
下游系统可以轻松地从 Avro 文件中检索表模式(无需将模式单独存储在外部元存储中)。
-
任何源模式更改都很容易处理(模式演变)。
Avro可以用于RPC调用?
Avro也可以作为RPC调用的一种编码格式,同XML、JSON、Hessian, Thrift, Protocol Buffers等相同作用,用于API技术体系中。
初步使用过程,可以参考《Avro序列化和RPC实现》
参考资料:
详细了解Avro,访问其官网
简单了解Avro,可参考 《Avro从入门到入土》,《Avro简介及使用入门》,《Avro 之Java语言入门案例》
Avro与大数据相关,可参考《Avro在Spark中的应用入门》,《Hadoop存储格式》