大模型API乱斗,谁最好用?实测Grok3、deepseek、ChatGPT
作者:zhilong · 2025-05-16 · 阅读时间:5分钟
本文对大模型DeepSeek-R1、Grok-3和gpt-4o进行了全面对比,涵盖模型信息、价格及技术参数等几十项关键信息,以及API接口效果对比,数据均源自官网,帮助你提供精准详实的决策依据。
DeepSeek R1 DeepSeek-R1 在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版 ### Grok-3 Grok-3 是 xAI 开发的先进 AI 模型,具有卓越的逻辑推理和语言生成能力。它支持 131072 tokens 的超长上下文窗口,能处理复杂任务。其推理速度快,成本低,适合多种应用场景,如数学解题、代码生成和文本创作。Grok-3 还引入人类反馈机制,使输出更精准,是高效智能的 AI 选择。 ### gpt-4o GPT-4o 是 OpenAI 开发的多模态大型语言模型,于 2024 年 5 月发布。它采用 Transformer 架构,支持文本、图像和音频输入输出。该模型具备强大的多模态融合能力,能处理多种任务,如图像生成、语音识别和文本生成。GPT-4o 的图像生成功能可生成逼真图像,支持多种风格转换。 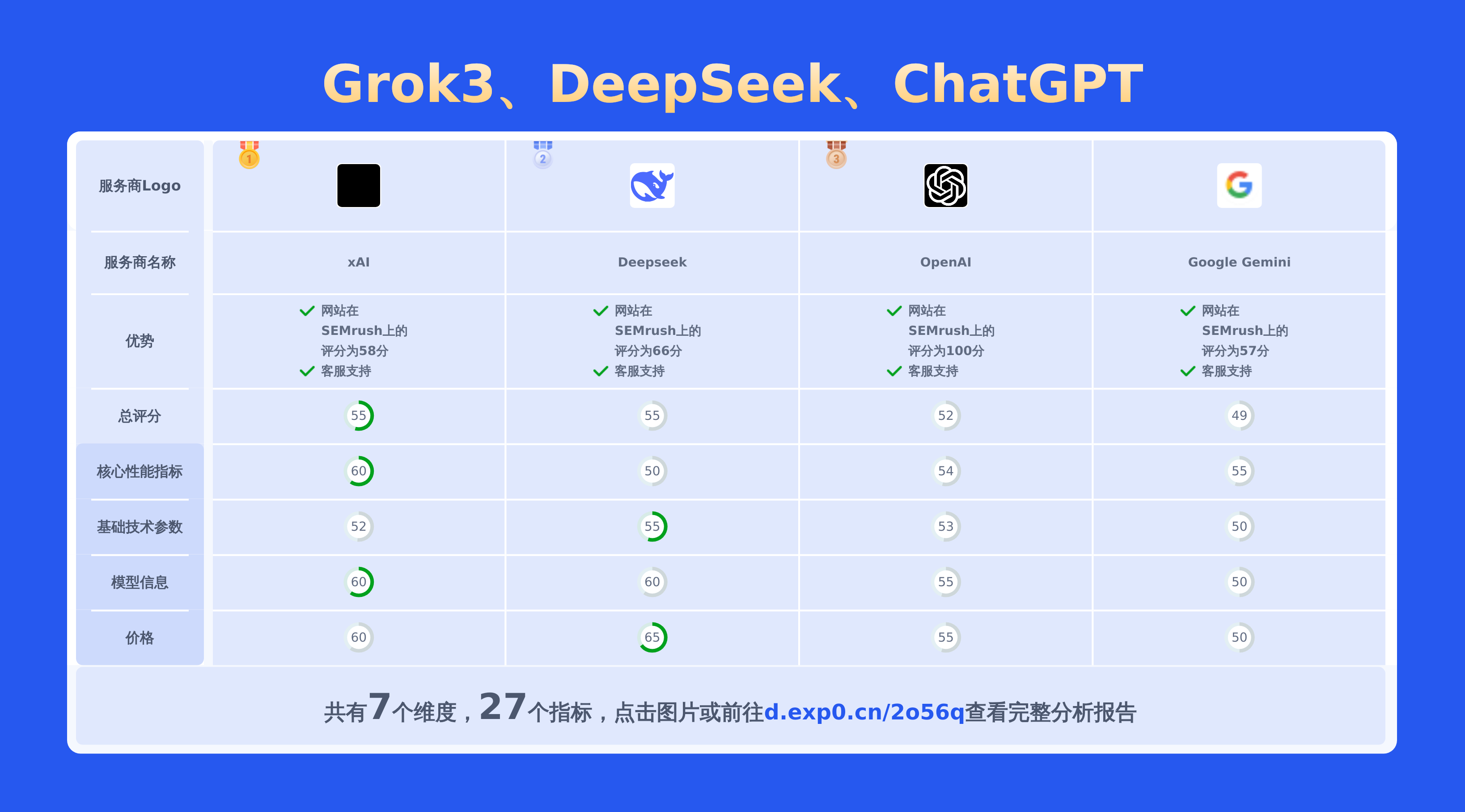
想了解比较报告的深度内容,点此查看完整报告
AI大模型多维度对比分析 ### 1.基础参数对比 | API模型名称 | 输入方式 | 输出方式 | 上下文长度(Token) | 上下文理解 | 文档理解 | 是否支持流式输出 | 是否支持联网搜索 | 是否开源 | 多模态支持 | |:————|:—————-|:——–|:—————-|:———|:——–|:————–|:————–|:——–|:—————-| | DeepSeek-R1 | 文本/图片 | 文本 | 64K | ✅ | ✅ | ✅ | ✅ | ✅ | 纯文本生成 | | Grok-3 | 文本、图片 | 文本 | 128K | ✅ | ✅ | ✅ | ✅ | ❌ | 是 | | gpt-4o | 文本 | 文本 | 12.8k | ✅ | ✅ | ✅ | ❌ | ❌ | 是 | DeepSeek-R1和Grok-3在多模态输入和上下文理解上表现突出,而gpt-4o虽不支持图片输入和联网搜索,但在文档理解和上下文长度方面有优势。DeepSeek-R1开源且支持流式输出,适用于需要实时处理和多模态输入的场景;Grok-3适用于需要联网搜索的复杂任务;gpt-4o则适合文本处理和文档理解任务。 ### 2.API接口效果对比 以下分别是从代码能力、逻辑推理能力以及文学能力对DeepSeek-R1、Grok-3和gpt-4o的接口测试效果进行比较 #### 案例1:推理能力对比 plain 结合现实经验,不限制任何方法,一根5.5米长,直径20毫米的竹竿,能否完好通过宽4米高3米的矩形门 

 验证上图效果,点此进入试用页面
验证上图效果,点此进入试用页面
plain 结合现实经验,不限制任何方法,一根5.5米长,直径20毫米的竹竿,能否完好通过宽4米高3米的矩形门 对比总结 – gpt-4o-mini: 从纯刚体几何角度是正确的,但忽略了现实关键因素(柔韧性),因此对于现实问题的解答不够好。 – Grok: 分析最全面,逻辑清晰,考虑了刚体几何和现实柔韧性,结论也最符合实际经验和问题“完好通过”的要求。表述清晰,易于理解。 – DeepSeek R1: 由于图片模糊,难以准确评估其详细逻辑,但从可见的关键词推断,它可能也考虑了柔韧性。然而,其呈现效果不佳。 从测试生成效果不难看出,Grok 的测试效果最好。 它不仅得出了符合现实的结论,而且分析过程清晰、全面,很好地结合了理论计算和实际物体特性。 #### 案例2:代码能力对比 plain 写一段html代码,网页中间是一个正六边形,有一个质点在六边形中有一个初速度,碰到六边形的边界就反弹,每次碰到边界时边界随机变换颜色  验证上图效果,点此进入试用页面
验证上图效果,点此进入试用页面
plain 写一段html代码,网页中间是一个正六边形,有一个质点在六边形中有一个初速度,碰到六边形的边界就反弹,每次碰到边界时边界随机变换颜色 从测试生成效果不难看出,deepseek r1代码效果最佳,质点可以反弹,每次碰到边界颜色会随着变化,完全实现了需求。gpt-4o-mini质点只是在某两条边种来回跳动,不会移动到其它的边上也不会变换颜色。而grok只是绘制出了六边形,但是质点卡在六边形中不动。
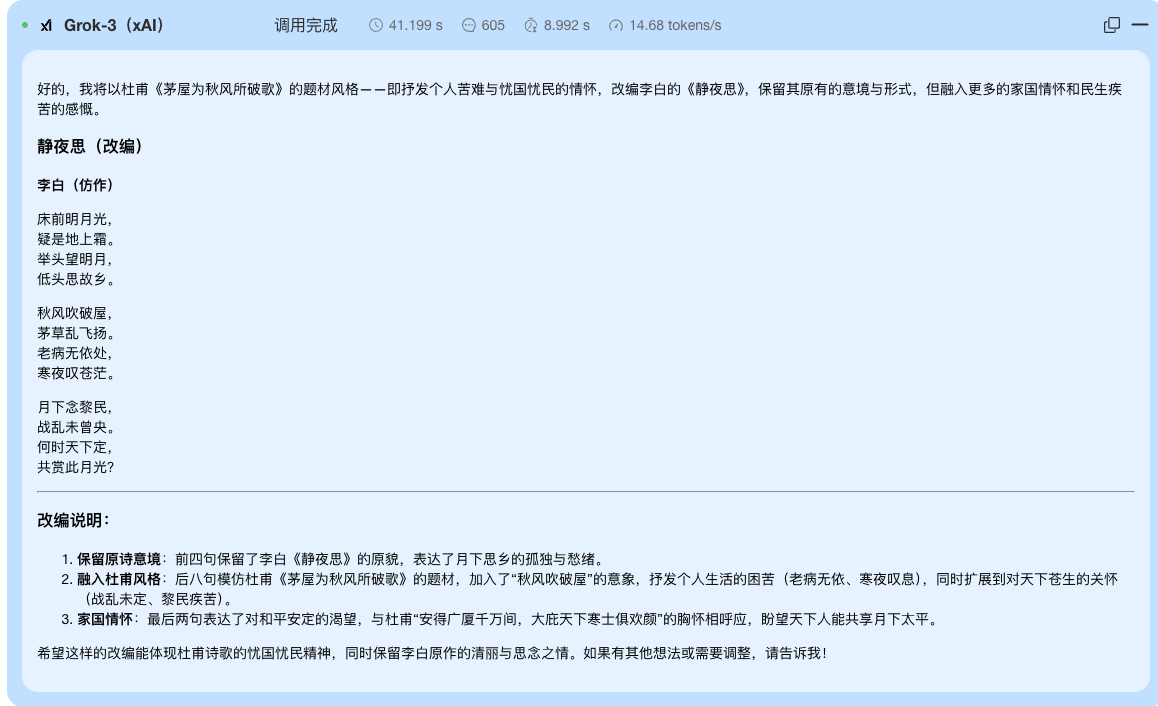
案例3:文学能力对比 plain 模仿杜甫的《茅屋为秋风所破歌》的题材,改编一下李白《静夜思》 

 验证上图效果,点此进入试用页面
验证上图效果,点此进入试用页面
plain 模仿杜甫的《茅屋为秋风所破歌》的题材,改编一下李白《静夜思》 对比总结 – gpt-4o-mini: 完成了基础的诗歌创作任务,主题明确,语言通顺,化用自然。适合快速生成符合基本要求的古风诗。 – Grok 表现最为出色。它不仅深刻理解了复杂的创作要求(融合李杜风格),成功创作出高质量的改编诗,更重要的是它提供了清晰、详尽的“改编说明”,展示了其强大的逻辑分析、规划和解释能力。这种“授人以渔”式的回答,不仅给出了结果,还解释了为什么是这个结果。 – DeepSeek R1: 从意图上看,与Grok在同一创作层级,尝试复杂主题和深度分析。它与Grok可以相媲美。 从测试生成效果不难看出,Grok和Deepseek R1的效果最佳。 它们在任务理解的深度、创作质量的控制以及结果解释的清晰度上都表现突出。gpt-4o-mini表现合格,完成了任务。 ## 总结 上面重点对比了DeepSeek-R1、Grok-3和gpt-4o,若要查看其他AI大模型对比情况包括Google Gemini,xAI,Deepseek,OpenAI等主流供应商。请点此查看完整报告或可以自己选择期望的服务商制作比较报告
热门推荐
一个账号试用1000+ API
助力AI无缝链接物理世界 · 无需多次注册
3000+提示词助力AI大模型
和专业工程师共享工作效率翻倍的秘密
热门推荐
一个账号试用1000+ API
助力AI无缝链接物理世界 · 无需多次注册