大模型从原理到应用开发——提纲挈领,十问十答
文章目录
- 问题1:大语言模型应用开发有哪些技术栈,他们之间的关系如何?
- 问题2:大语言模型的底层原理,如Transformer架构,学到什么程度比较合适?
- 问题3:大语言模型有哪些打开方式?
- 问题4:大语言模型应用开发核心内容,重点为何?有没有好的学习路线图?
- 问题5:LangChain、LlamaIndex、SemticKernel、OpenAI API这些开发工具关系如何,特点优劣比较?
- 问题6:Agent到底是什么,怎么开发,怎么用?有哪些认知模式?
- 问题7:RAG和模型微调选择哪个?
- 问题8:如何设计产品级别的RAG系统
- 问题9:到底如何做大模型的微调、量化和推理加速?
- 问题10:AI应用开发、产品和商业模式创新,为什么是现在?
本文是 新加坡科研局首席AI研究员黄佳 在CSDN直播间主题分享的文字版。
问题1:大语言模型应用开发有哪些技术栈,他们之间的关系如何?
首先看一下大模型的整个知识体系。
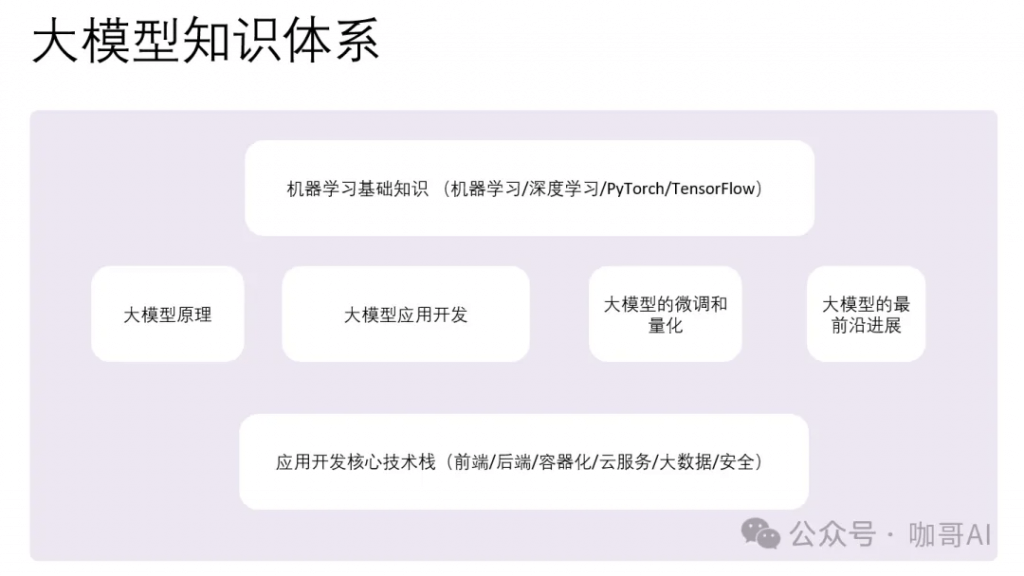
因为无论学习什么,总是要先鸟瞰全局,再循序渐进,反正我是这么学的,有先学后学,但是更重要的先入门,对体系中的每一个部分都有一个最基本的知识,然后是不断循环,不断深入。

对于我们大部分人来说,我们学大模型,要么是为了微调,要么是为了应用开发。
然而,原理仍然很重要。
尤其是当你学到微调的时候,如果不了解底层原理,你根本无法理解各种微调的区别(比如说面试官可能问你Lora和Adapter的区别),那你也就更不可能轻松的理解更新的架构为什么这样或者那样去设计。
做应用开发也是。为什么要打扎实原理基础 – 因为不深刻了解原理,你用LLM来做应用的时候心里就没底。
当我们心中有了一个技术地图,那么剩下的,更深入的东西就可以一点点地往这个技术地图里面安插。那么当一个新的技术又突然来临时,因为你胸中已有丘壑,你也就没有那么焦虑了。
问题2:大语言模型的底层原理,如Transformer架构,学到什么程度比较合适?
我们要从语言模型的定义和起源开始去理解到底什么是大语言模型,看看它是怎样一步一步进化到今天这个状态的。
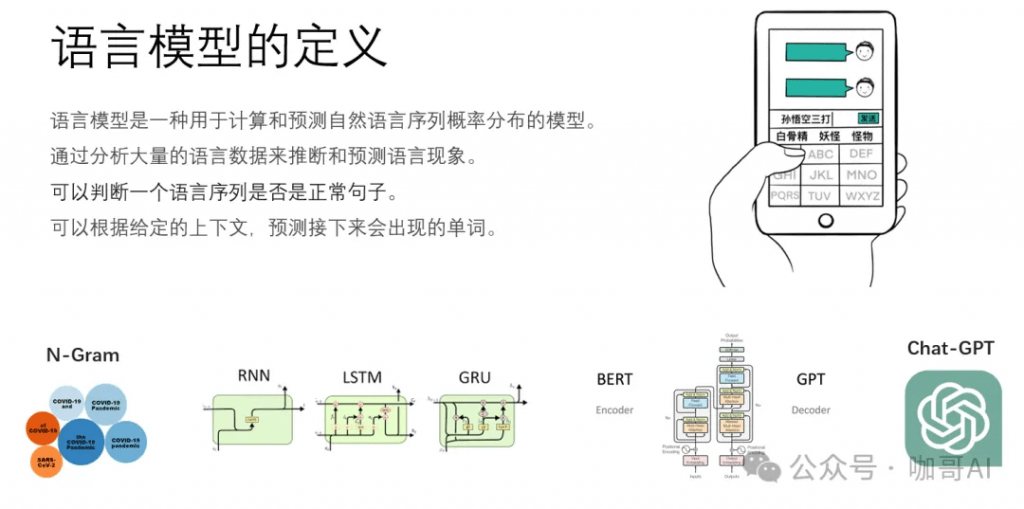
语言模型是一种用于计算和预测自然语言序列概率分布的模型,它通过分析大量的语言数据来推断和预测语言现象,为自然语言上下文相关的这种特性来建立数学模型。简单地说,它可以根据给定的上下文,预测接下来的单词。
常见的语言模型n-Gram模型、循环神经网络(RNN)模型、长短时记忆网络(LSTM)模型,以及现在非常流行的基于Transformer架构的预训练语言模型(Pre-trained Language Model,PLM),如BERT、GPT系列等,本质上都是语言模型。
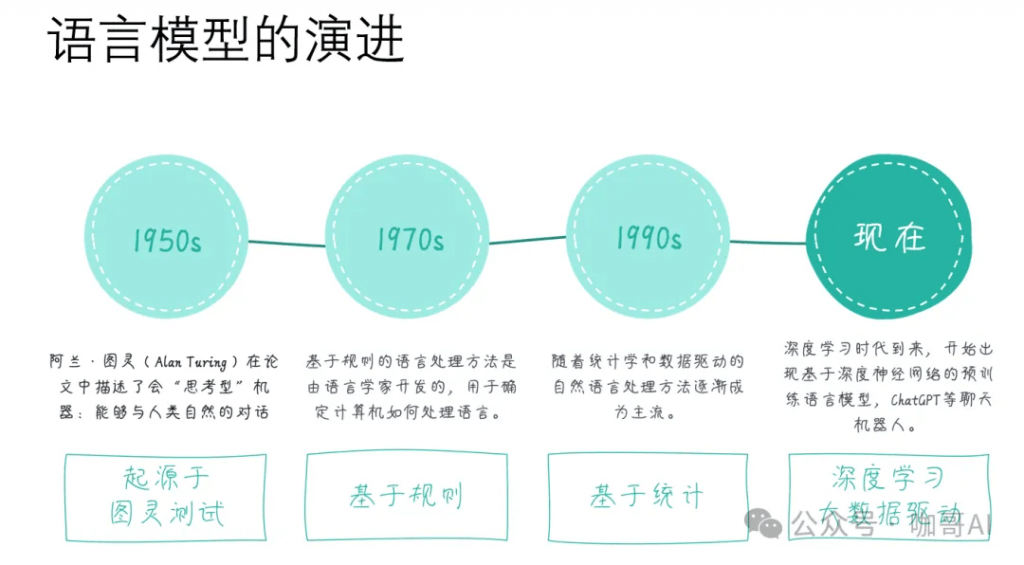
以我个人的经验来看,对语言模型的原理,了解到科普的程度是远远不够的,手撕几次Transformer框架,无论对于后续做应用开发,还是做微调,或者是去面试,都是很有好处的。
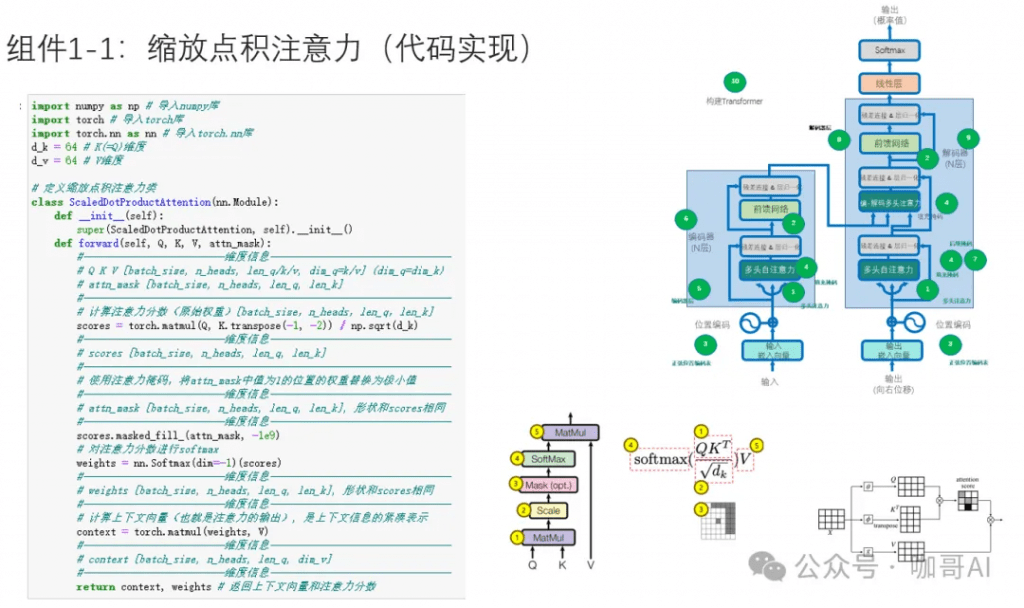
问题3:大语言模型有哪些打开方式?
那么具体到我们每个人,每一个企业,我们打开,也就是解锁大模型能力的方式有哪几种呢?
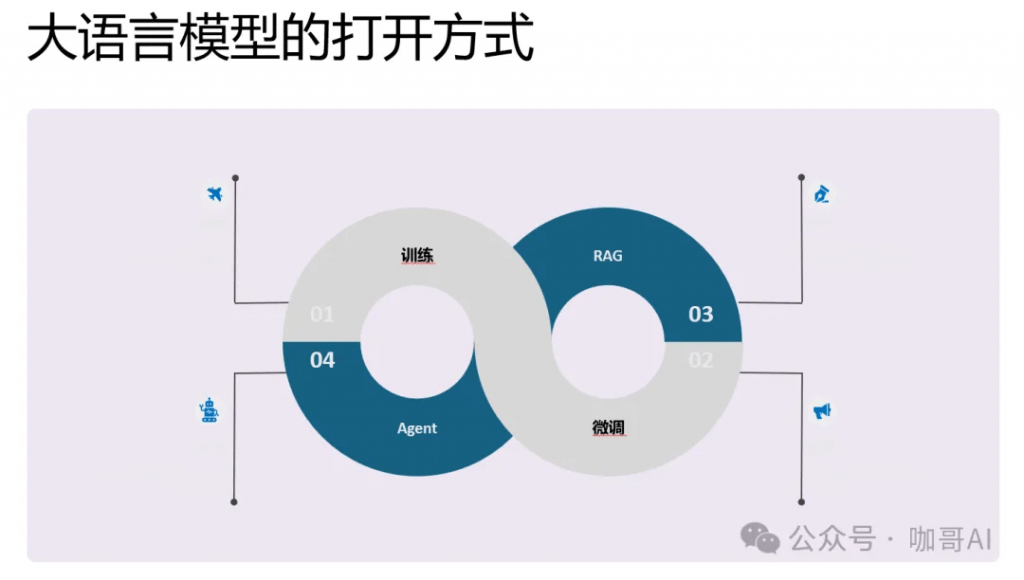
第一个就是从头训练出属于你自己的企业大模型。
第二个就是基于基础模型,微调一部分参数。二者的区别在于数据的数量需求不同。
那么第三个相对比较成熟的就是RAG应用。通过企业知识库来构建检索增强功能。
第四个就是尚未完全成熟但是大家都在探索的Agent技术。
问题4:大语言模型应用开发核心内容,重点为何?有没有好的学习路线图?
核心内容就是找到属于你自己的应用场景。
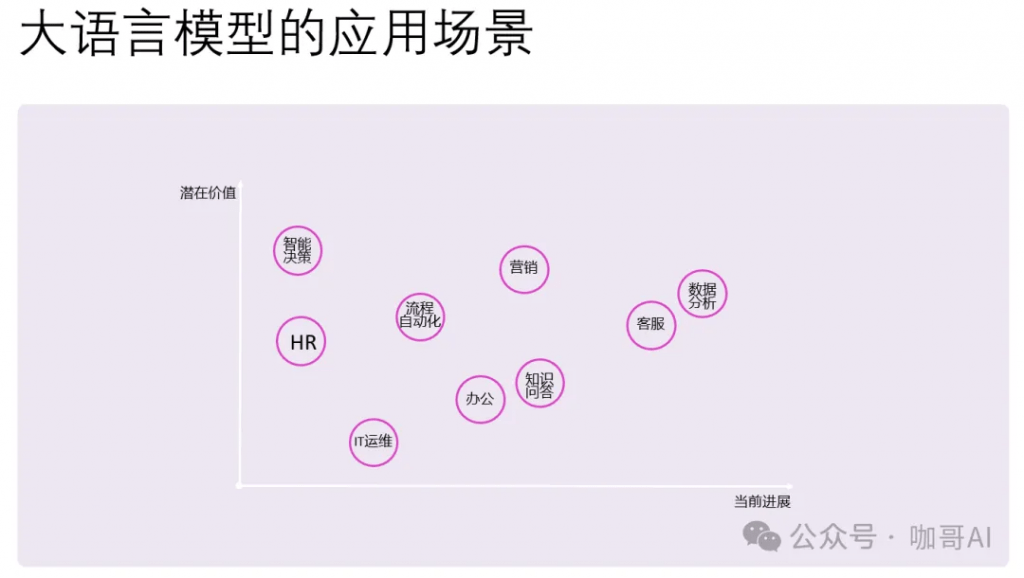
具体到大语言模型的应用场景,有两个维度,一个是当前进展,也就是落地的难度。难度小,进展就大。
有些场景是很难落地的,但是潜在价值却很大。比如如何让AI进行智能化的决策,也就是AI Agent的应用,大家还都在摸索之中。
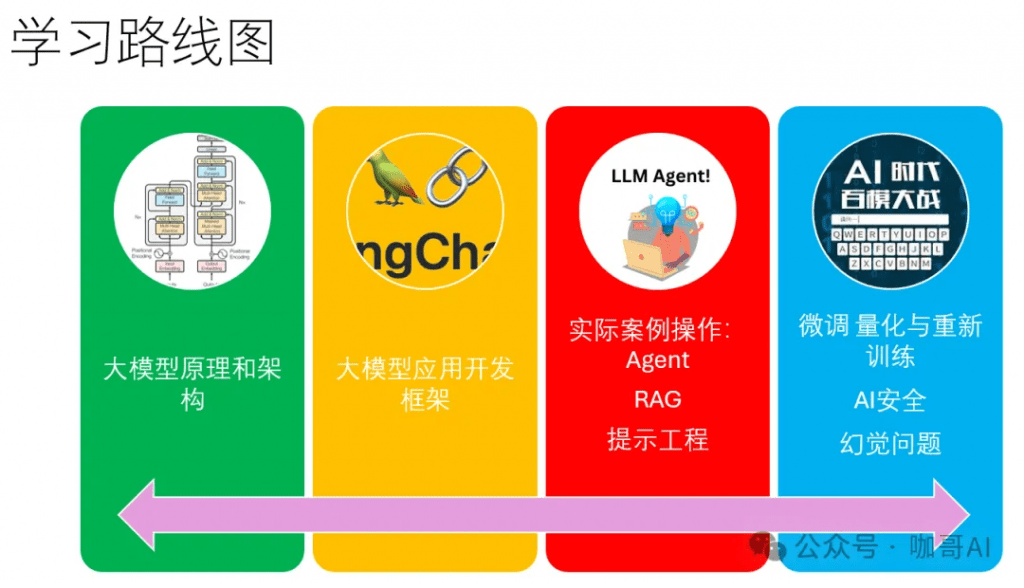
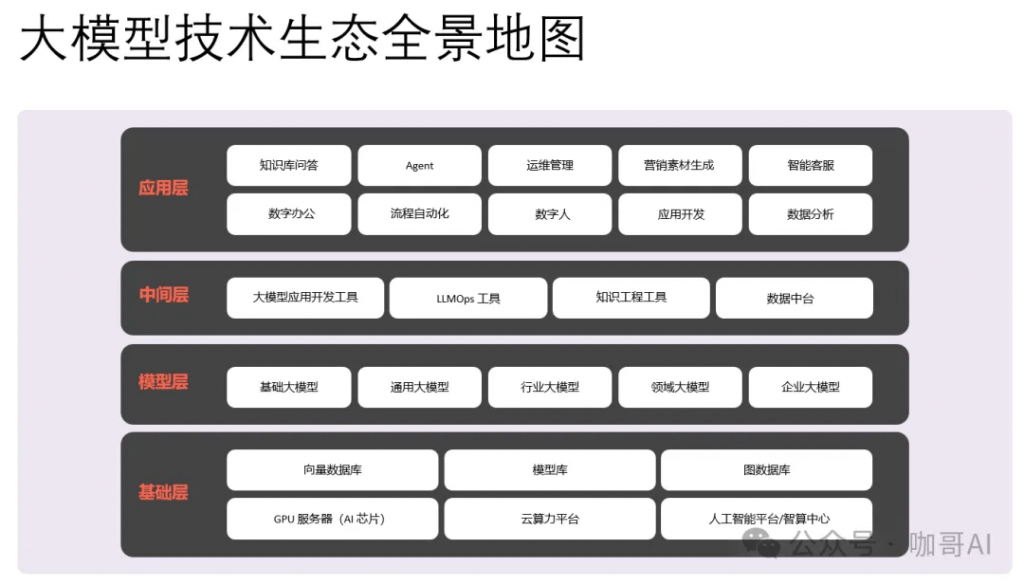
上图中的这些技术,都是进军大模型应用开发的良好切入点。
问题5:LangChain、LlamaIndex、SemticKernel、OpenAI API这些开发工具关系如何,特点优劣比较?
LangChain、LlamaIndex、Semantic Kernel 和 OpenAI API 都是为了加强与大型语言模型(LLMs)的交互而设计的开发工具,它们在特点和用途上各有侧重。
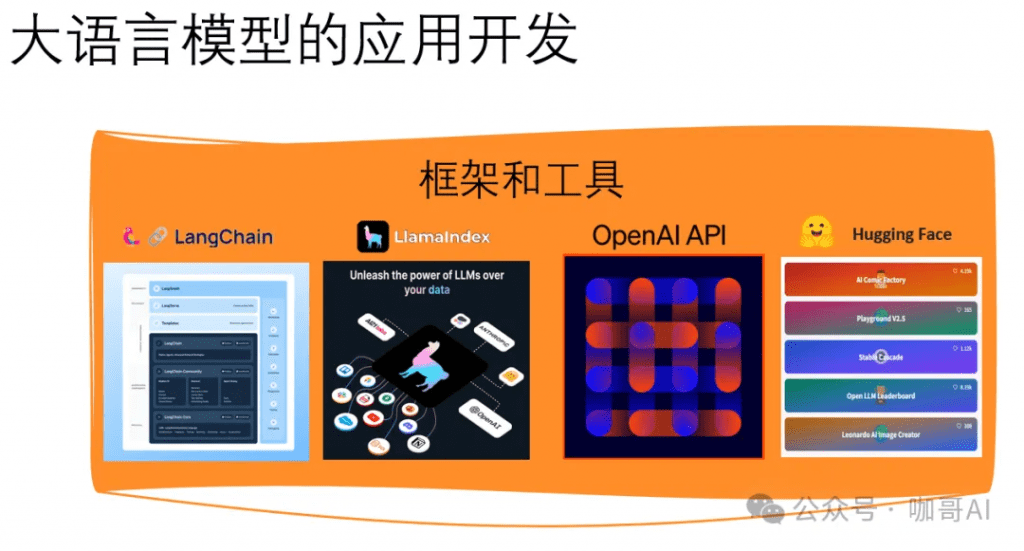
- LangChain:LangChain 专注于将语言模型与外部数据源(如数据库、APIs、文档等)结合使用。它支持从多个数据源加载数据,并使这些数据在推理时可供LLMs使用。它通过标准接口简化了提示的构建和模型的交互,允许开发者创建能够执行多任务的智能代理。
- LlamaIndex:LlamaIndex 主要关注于数据的深度索引和检索。它提供了数据连接器、索引和查询引擎,这些工具帮助将私有或特定领域的数据集成到LLMs中。LlamaIndex 适合需要智能搜索和检索功能的应用场景。
- Semantic Kernel:Semantic Kernel 是一个由微软支持的SDK,它使开发者能够将LLMs整合到常规编程语言(如C#、Python)中。它提供了插件机制,这些插件可以在几行代码中串联起来,支持多种编程语言,很适合需要深度集成到Microsoft生态系统中的项目。
- OpenAI API:OpenAI提供的API允许开发者直接访问GPT-4和其他模型,用于各种文本生成和处理任务。API的设计旨在简化开发者的使用流程,无需深入底层就能构建应用。
在选择这些工具时,重要的是考虑您的具体需求:如果项目侧重于数据驱动的交互和多数据源集成,LangChain可能是更好的选择。如果需要高效的数据索引和检索,LlamaIndex将非常适合。而如果希望在多种编程环境中快速集成语言模型,或者需要与Microsoft的工具和服务无缝协作,Semantic Kernel可能更加合适。对于直接访问最新的语言模型并快速部署文本相关应用,OpenAI API则提供了一个非常直接和强大的选项。—— 对于我个人来说,现在我经常使用OpenAI API(或者其它任何国内LLM的API)直接创建LLM应用。
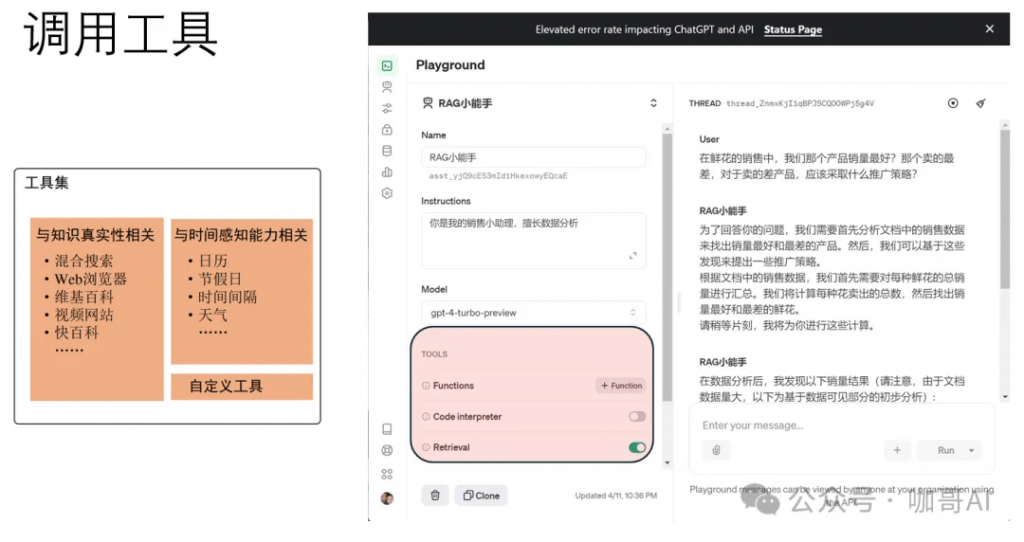
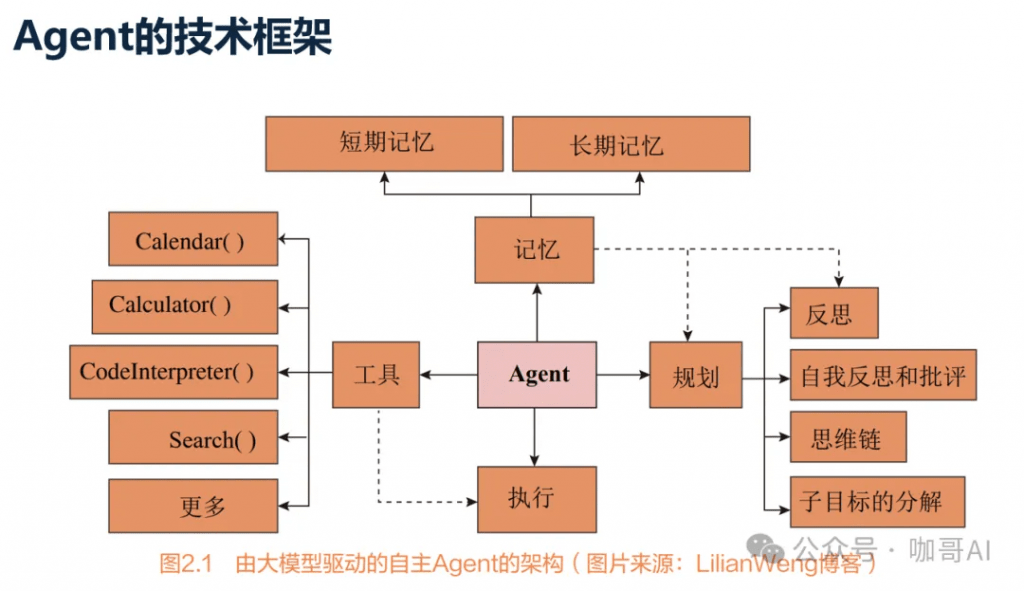
问题6:Agent到底是什么,怎么开发,怎么用?有哪些认知模式?
我们把所有能够感知环境、做出决策并采取行动的实体或系统视为人工智能领域中的Agent。
Agent能够自主推理。

Agent能够调用工具。

问题7:RAG和模型微调选择哪个?
许多大型语言模型(LLM)的应用需要使用用户特定的数据,而这些数据并不是模型训练集的一部分。实现这一点的主要方法是通过检索增强生成(RAG)。在这个过程中,会检索外部数据,然后在生成步骤中传递给LLM。
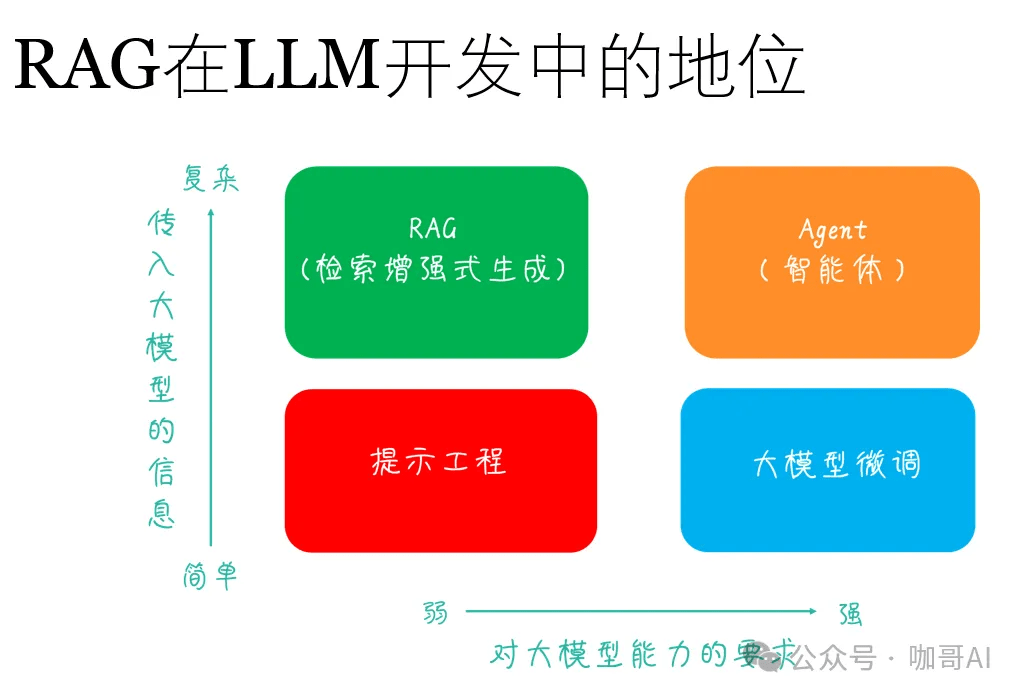
RAG在基于LLM的应用开发中地位不低,堪称AI大模型落地应用第一站。
RAG的实现架构如下。
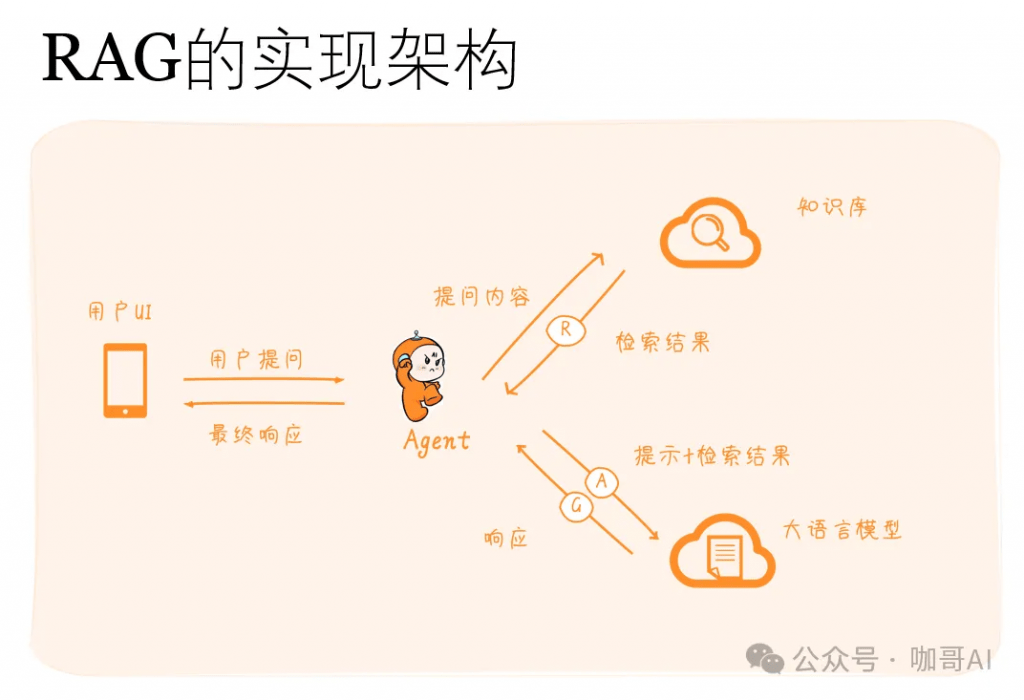
RAG 的工作原理可以分为如下两个主要部分:
- 信息检索(Retrieval):在这一阶段,系统会从一个大型的数据集中检索相关信息。这个数据集通常包含大量的文本数据,如维基百科文章、新闻报道或其他相关文档。(当然,因为目前的检索也是通过大模型来完成,而且大模型通常具有多模态能力,因此这个被检索的数据集并不一定都是文档,还可以是图片、代码、关系数据库等多种形式。)当系统接收到一个查询(例如一个问题)时,它会在这个数据集中寻找与查询相关的信息。
- 文本生成(Generation):在检索到相关信息后,系统会使用这些信息来生成一个响应。这个阶段通常是通过一个预训练的语言模型完成的,如 GPT(Generative Pre-trained Transformer)。语言模型会根据检索到的信息来构造一个连贯、相关的回答或文本。
那么,遇到行业相关的LLM应用,做RAG,还是做微调,这是一个问题!
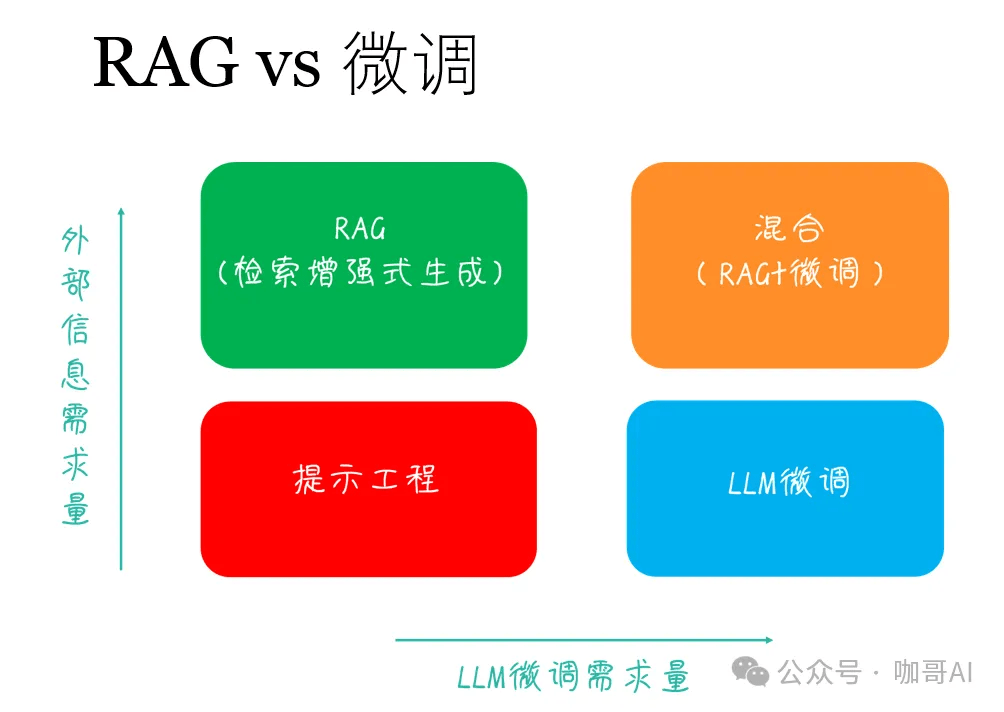
有论文指出——相对于做微调来说,RAG其实是性价比更高的选择。
问题8:如何设计产品级别的RAG系统
设计出产品级别的RAG系统并非易事,有很多工程细节需要思考。比如说,如果几十万甚至上百万文档,如何还能高效检索。在文档切片时,如何保留前后上下文。
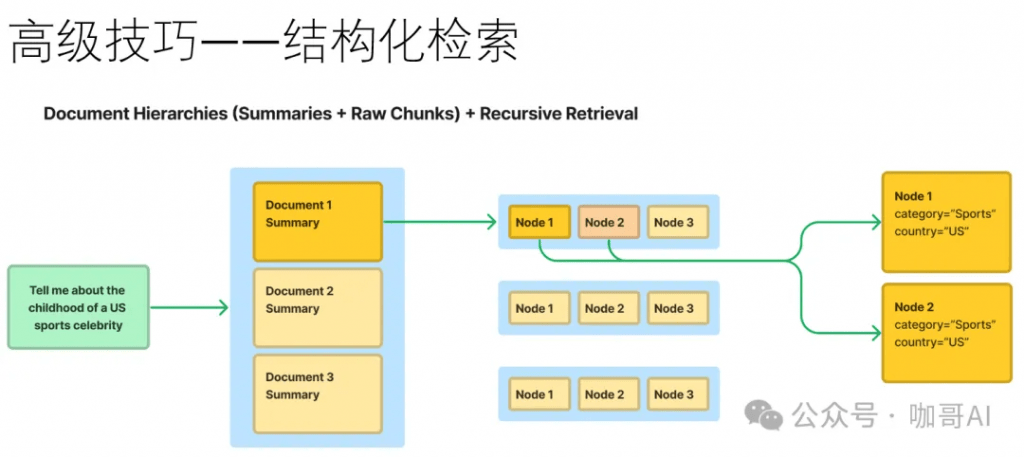
此时我们的确需要一些高级技巧,以及实战经验的总结和积累。有效地选择Embedding模型,优秀的向量数据库,优化的索引和检索方案,以及强大的生成模型都是必不可少的。
问题9:到底如何做大模型的微调、量化和推理加速?
对于这个问题,就更不是几句话可以说清楚的了。
- 微调:在特定任务上对预训练模型进行额外训练,以提高其在该任务上的性能。
- 量化:将模型参数从高精度表示(如32位浮点数)转换为低精度表示(如8位整数),以减少存储和计算资源。
- 推理加速:通过优化算法或硬件加速器减少模型在推理(即实际使用)过程中的计算时间,提高响应速度。

佳哥希望有机会带着你,做一些LLM微调/量化和加速框架的项目实战。

问题10:AI应用开发、产品和商业模式创新,为什么是现在?
从新技术的爆发周期来看,AI革命正逢其时,这是技术带给我们每一个人的千载难逢的良机。AI应用的爆发期可能还需要2-3年的时间,killer app暂时没有进入大众用户人群是符合客观规律的。

桌面程序时代,互联网时代,移动互联网时代,都催生了大量独角兽,唯独AI时代,仍然有大量空白区域虚位以待。—— 这是我们程序员、开发人员、产品经理,每一个IT人的机会。
原文转自 微信公众号@咖哥AI
- 问题1:大语言模型应用开发有哪些技术栈,他们之间的关系如何?
- 问题2:大语言模型的底层原理,如Transformer架构,学到什么程度比较合适?
- 问题3:大语言模型有哪些打开方式?
- 问题4:大语言模型应用开发核心内容,重点为何?有没有好的学习路线图?
- 问题5:LangChain、LlamaIndex、SemticKernel、OpenAI API这些开发工具关系如何,特点优劣比较?
- 问题6:Agent到底是什么,怎么开发,怎么用?有哪些认知模式?
- 问题7:RAG和模型微调选择哪个?
- 问题8:如何设计产品级别的RAG系统
- 问题9:到底如何做大模型的微调、量化和推理加速?
- 问题10:AI应用开发、产品和商业模式创新,为什么是现在?