利用RLHF快速工程改进文本到图像模型
在现代文本到图像生成领域,许多用户希望快速生成美观的图像,用于博客文章、演示文稿或其他材料。然而,学习复杂的提示工程技巧(如“Artstation上的趋势”)对许多人来说并不现实。为了解决这一问题,Toloka团队开发了一种创新的解决方案,能够将简单的图像描述转化为专业提示,从而生成高质量的视觉效果。
通过结合人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF),我们不仅优化了提示生成的质量,还确保生成的图像始终具有吸引力。此外,我们提供了一个用户友好的界面,让用户只需输入基本的图像描述即可获得专业提示。无论是初学者还是专家,都可以利用我们的开源代码、数据和模型,轻松复制或扩展这一方法。
方法概述
我们的模型以以下格式的文本作为输入: 
模型会在SEP标记后生成提示,因为它是一个自回归语言模型,而非seq2seq模型。
从人类反馈中学习强化学习(RLHF)
RLHF的实现分为以下三个主要步骤:
步骤1:监督微调(SFT)
在监督微调阶段,我们为模型提供演示数据,帮助其学习所需的响应格式和相关信息。在我们的案例中,数据集格式为image_description[prompt](https://prompts.explinks.com/)。由于没有公开的图像描述和提示数据集,我们采用以下方法:
- 收集图像描述数据集,并通过OpenAI的text-davinci-003模型提取提示。
- 使用HuggingFace Transformers的标准脚本进行语言模型微调,并对脚本进行调整,仅在提示部分计算损失。
训练过程在单个NVIDIA A100 80GB GPU上耗时约90分钟。
步骤2:奖励建模(Reward Modeling)
奖励建模包含两个阶段:偏好收集和奖励建模。
偏好收集
我们为每个图像描述生成三个提示,并使用Stable Diffusion 1.5生成四张图像。随后,通过Toloka众包平台对这些图像进行成对比较,注释者选择更优的一组图像。 
奖励建模
我们选择使用distilroberta作为奖励模型,并通过Transformers库中的AutoModelForSequenceClassification进行训练。模型以image_description[SEP]prompt格式的文本输入,并预测一个表示质量的数值。
训练过程使用二进制交叉熵损失函数,目标是预测左提示是否优于右提示。在单个NVIDIA A100 80GB GPU上,训练耗时约15分钟,验证集准确率为0.63,足以支持RLHF微调。
步骤3:强化学习(RLHF)
在RLHF阶段,我们面临超参数调优的挑战,特别是学习率和init_kl参数的选择。我们发现较低的参数值效果最佳。
训练过程中,价值损失持续下降,奖励模型的预测奖励显著增加,但这并不意味着模型完全优化,因为奖励模型本身可能存在缺陷。 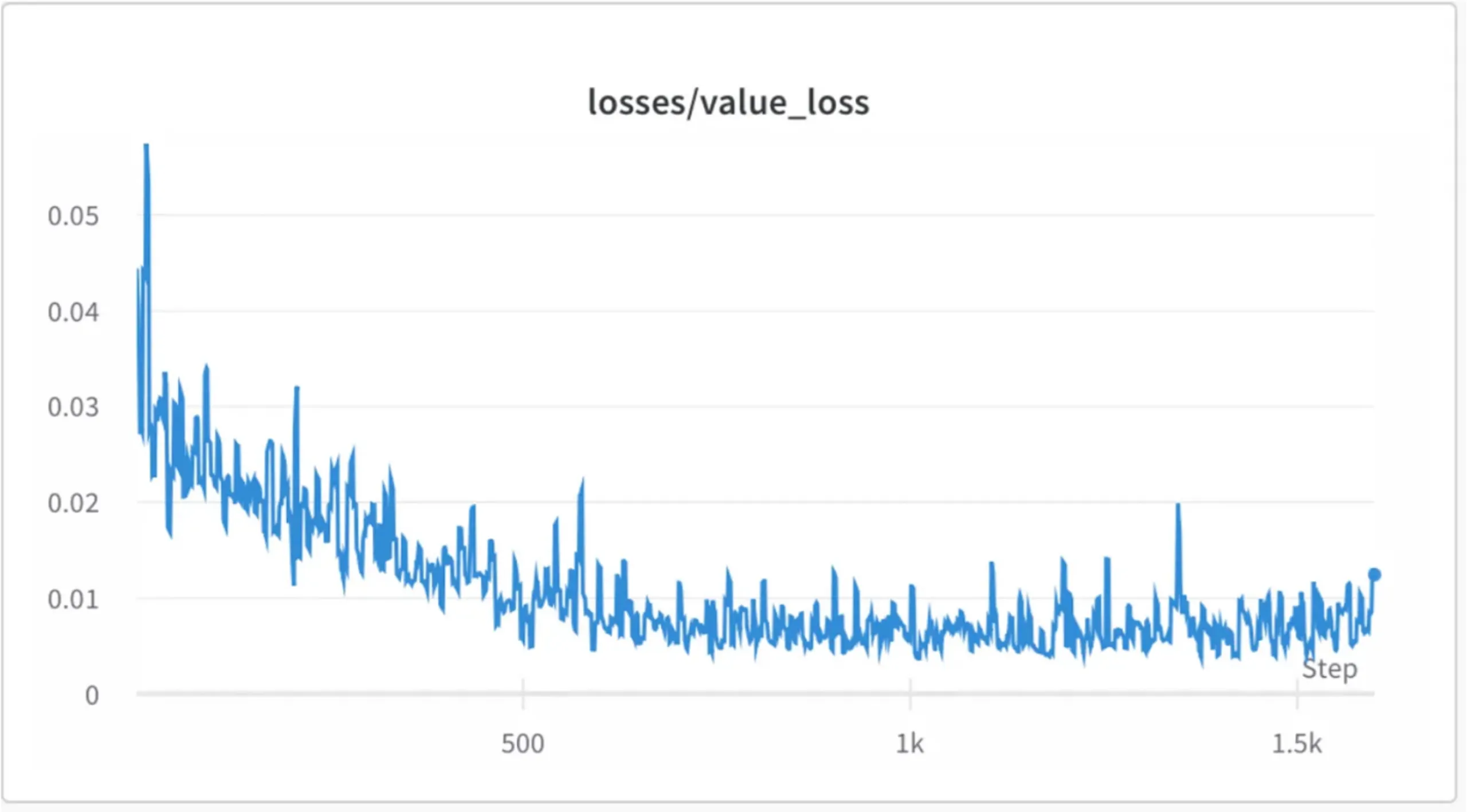
视觉效果展示
以下是通过我们的模型生成的图像示例:
-
外星人飞船内部

-
一只猫的肖像

-
其他生成效果

除非特别说明,以上图像均由Stable Diffusion 1.5生成。
下一步计划
我们已将所有代码和数据开源,供社区使用。未来,研究者可以基于我们的成果,为DALL-E 2、Midjourney等其他模型开发类似的解决方案。我们期待您的反馈和建议,共同推动文本到图像生成技术的发展。
原文链接: https://toloka.ai/blog/improving-text-to-image-models-by-prompt-engineering-with-rlhf/