大模型 "蒸馏" 是什么?
文章目录
论文《A Survey on Knowledge Distillation of Large Language Models》

https://arxiv.org/abs/2402.13116 这篇论文是干嘛的?这篇论文是关于“知识蒸馏”(Knowledge Distillation,简称 KD)在大型语言模型(Large Language Models,简称 LLMs)中的应用。
简单来说,知识蒸馏就像是让一个“聪明的大老师”(比如 GPT-4)教一个“普通的小学生”(比如开源模型 LLaMA),把大模型的聪明才智传给小模型,让小模型也能变聪明,而且更省资源、更容易用。
论文的作者们想给大家讲清楚三件事:
- 知识蒸馏怎么做:有哪些方法能把大模型的知识“蒸馏”出来,教给小模型?
- 能教什么本领:小模型通过学习能掌握哪些具体的技能,比如理解上下文、写代码、回答问题?
- 用在哪:这些“蒸馏”出来的小模型能在哪些领域发挥作用,比如医疗、法律、金融?
他们还特别提到了一种“数据增强”(Data Augmentation,简称 DA)的技术,说它在知识蒸馏里特别重要,能让小模型学得更好。
论文结构很清晰,分成了算法、技能和应用三个大块(这叫“三大支柱”),后面我会详细讲。
为什么要研究这个?
想象一下,GPT-4 这样的“大模型”超级聪明,能写文章、回答问题、甚至帮你解决问题,但它有个问题:太大了,太贵了,不是每个人都能用得上。就像一台超级豪华跑车,性能强但耗油多、一般人开不起。
而开源模型(比如 LLaMA、Mistral)呢,虽然免费、灵活,但本事没那么大,就像一辆普通小轿车。知识蒸馏的目标就是:
- 让小轿车也能跑得快一点,至少能干点跑车能干的事。
- 这样,大家就能用更便宜、更小巧的模型,享受 AI 的好处。
论文里还提到,这种技术还能让开源模型自己教自己变得更强(自改进),或者把大模型压缩得更高效。
核心内容拆解
1. 知识蒸馏是什么?(Overview)
知识蒸馏最早是用来把复杂的神经网络“压缩”成简单的小网络。比如原来一个大模型有几亿个参数,跑起来很费电脑,蒸馏后弄成一个小模型,参数少多了,但还能干差不多的事。
到了大型语言模型时代,知识蒸馏变得更高级了。现在不光是压缩模型,还要把大模型的“知识”和“能力”传给小模型。比如,GPT-4 能写诗、推理、聊天,知识蒸馏就想让小模型也学会这些本事。
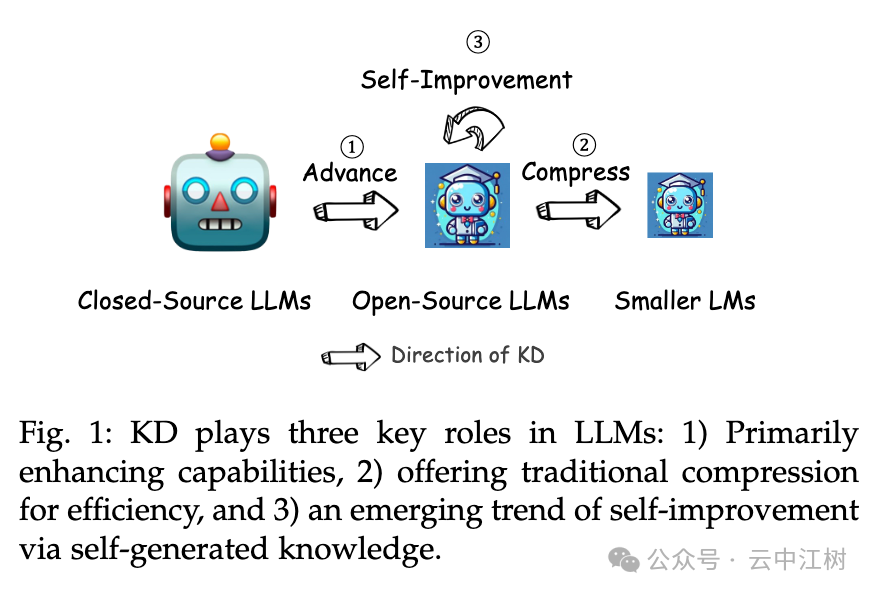
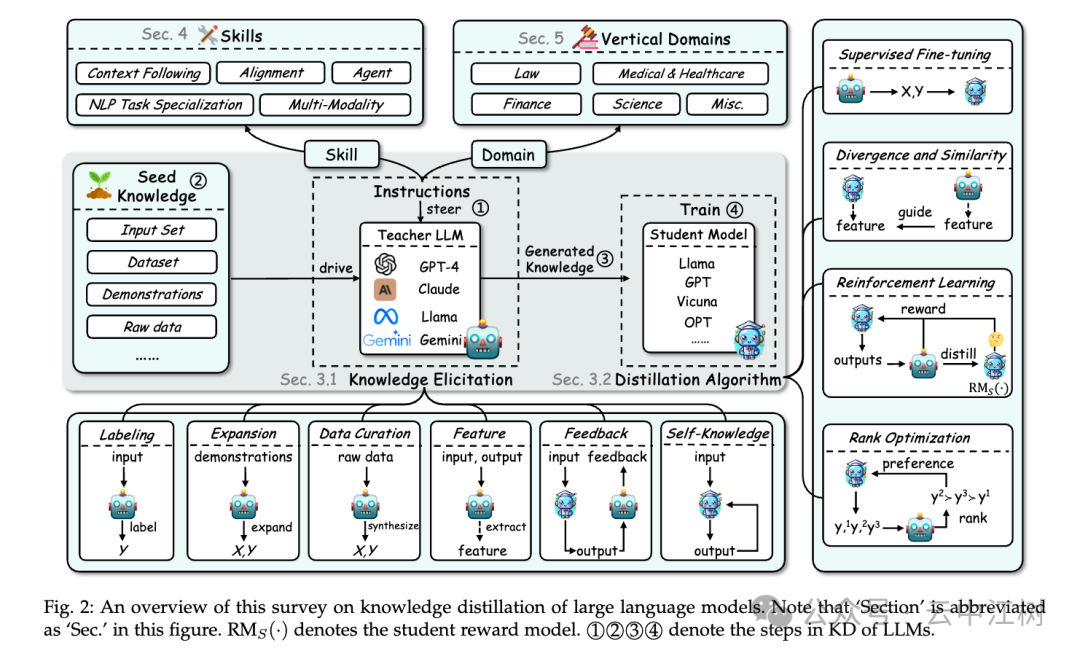
论文里提到,知识蒸馏有三个主要作用(见图 1 位置:Fig. 1: KD plays three key roles in LLMs):
- 提升能力:把大模型的本事传给小模型。
- 压缩模型:让大模型变小变快,但不丢本事。
- 自我改进:让小模型自己当老师,自己学着变强。
2. 数据增强(DA)和知识蒸馏的关系
数据增强听起来很高大上,其实就是“造数据”。
- 以前的 DA 可能是把一句话改改意思,或者翻译一下再翻回来,增加点训练数据。
- 现在的 DA 是用大模型生成一大堆高质量的“教学材料”。
比如,你给 GPT-4 一点点“种子知识”(比如几个问题和答案),它就能生成成千上万类似的问答对。这些数据不是随便乱造,而是针对特定技能(比如数学推理)或领域(比如医学)量身定做的。有了这些数据,小模型就能拿来练习,学到大模型的本事。
这就像给小学生准备了一堆精选练习题,比随便找点题做效果好多了。
3. 知识蒸馏的流程
论文给了个通用流程,告诉你怎么把大模型的知识传给小模型(见图 4 位置:Fig. 4: An illustration of a general pipeline to distill knowledge):
- 挑目标:先决定教小模型什么,比如“学会写代码”或“懂法律”。
- 给种子:给大模型一点“种子知识”(比如几个例子),让它知道从哪开始。
- 生成教材:大模型根据种子知识,生成一大堆教学材料(比如问答对)。
- 教学生:拿这些材料训练小模型,让它模仿大模型的本事。
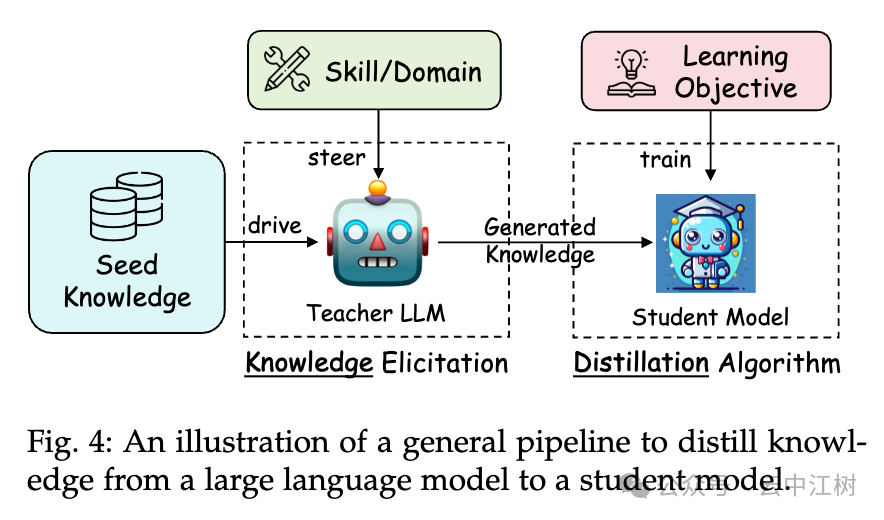
这个流程简单来说就是:
- 大模型先干活,产出“教材”,
- 小模型再拿教材学。
4. 知识蒸馏的三大支柱
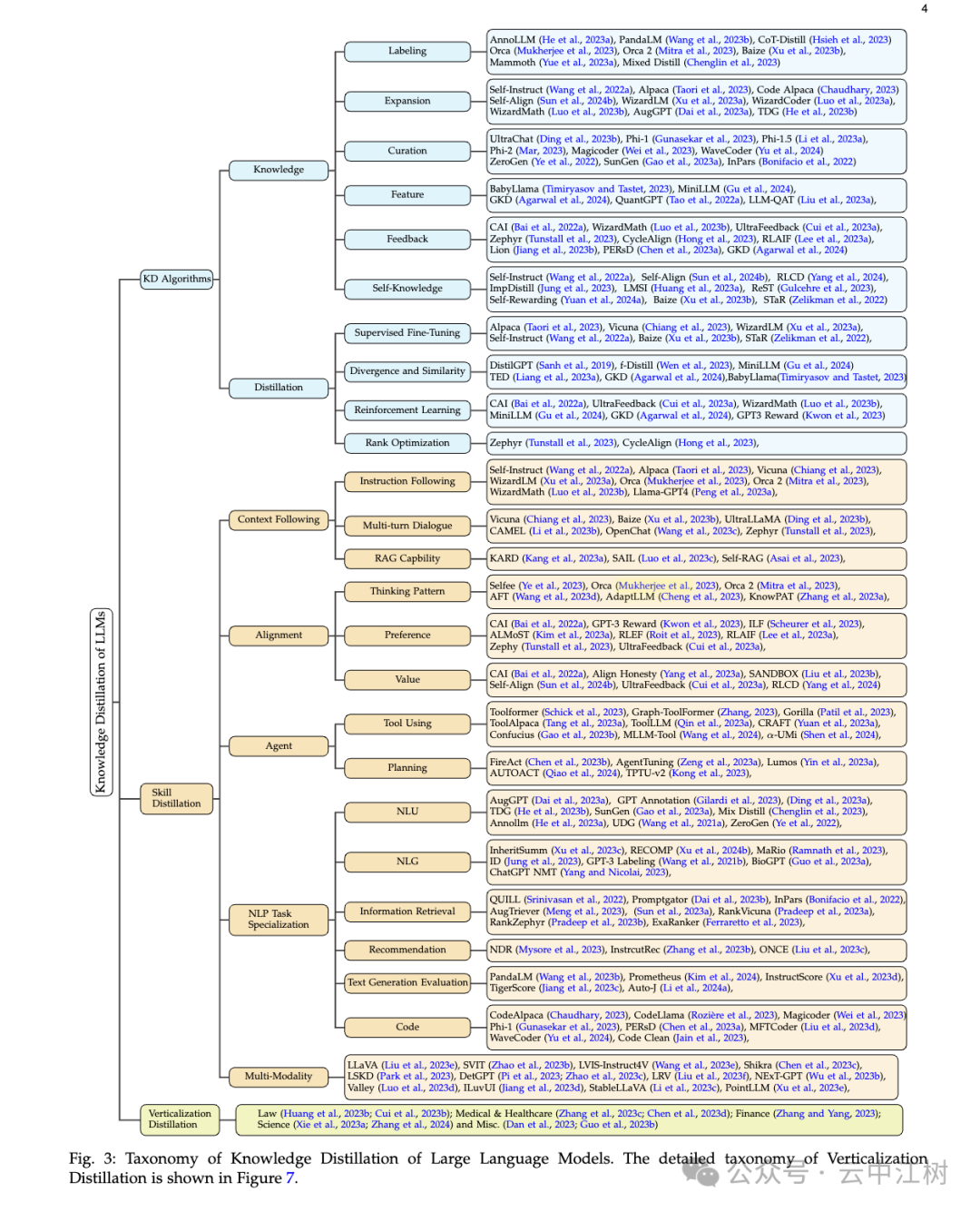
论文把知识蒸馏分成三大块(见图 3 位置:Fig. 3: Taxonomy of Knowledge Distillation of Large Language Models):
(1)算法(KD Algorithms)
这是讲怎么“教”。论文分了两步:
-
知识怎么挖出来(Knowledge):
- 标注(Labeling):给大模型一些问题,让它直接给出答案。比如,问“1+1=?”它回答“2”,这些问答对就是知识。
- 扩展(Expansion):给大模型几个例子,它自己生成更多类似的问答。比如,给几个数学题,它能造出几百个类似的题。
- 整理(Data Curation):大模型根据某个主题(比如医学)生成相关数据,再整理成教材。
- 特征提取(Feature):从大模型的“脑子”里挖出深层信息(比如它怎么思考的),教给小模型。
- 反馈(Feedback):小模型先试着回答,大模型看看对不对,给点建议。
- 自学(Self-Knowledge):小模型自己生成答案,自己挑好的学。
-
怎么教小模型(Distillation):
- 监督微调(Supervised Fine-Tuning):直接拿大模型的答案当标准,让小模型模仿。
- 差异最小化(Divergence and Similarity):让小模型的答案和大模型尽量靠近。
- 强化学习(Reinforcement Learning):给小模型打分,答得好就奖励,慢慢变强。
- 排序优化(Rank Optimization):教小模型学会挑最好的答案。
(2)技能(Skill Distillation)
这是讲教小模型“学会什么”。论文列了好多技能:
- 上下文理解:比如学会按指令办事(Instruction Following),或多轮对话(Multi-turn Dialogue)。
- 对齐用户意图:让小模型的回答更符合人的想法,比如推理方式(Thinking Pattern)或价值观(Value)。
- 任务专精:比如自然语言理解(NLU)、生成文本(NLG)、写代码(Code)、甚至处理图片和文字一起(Multi-Modality)。
(3)应用(Verticalization Distillation)
这是讲小模型“用在哪”。论文举了几个例子:
- 法律:帮律师分析案例。
- 医疗:回答医学问题。
- 金融:预测股票或分析报告。
- 科学:解决数学或物理问题。
这篇论文说了啥新鲜的?
- 数据增强很关键:以前知识蒸馏主要是模仿大模型的输出,现在加上了 DA,能生成更丰富的数据,让小模型学得更聪明。
- 不只是压缩:现在的知识蒸馏不光是让模型变小,还能教它高级技能,比如推理、对齐人类价值观。
- 三大支柱:算法、技能、应用,这个结构很清晰,帮你从“怎么做”到“做什么”再到“用在哪”全搞明白。
对应用的好处
- 省钱省力:不用买 GPT-4 那么贵的模型,小模型也能干活。
- 自己能用:开源模型蒸馏后,你可以随便改,随便用,不用担心隐私泄露。
- 领域定制:想让 AI 帮你干啥(比如看病、写合同),都能通过蒸馏搞定。
总结
这篇论文就像一份“AI 教学指南”。
它告诉你怎么用大模型(比如 GPT-4)当老师,把知识传给小模型(比如 LLaMA),让小模型变得聪明、好用还能省资源。核心是三大块:
- 怎么教(算法)
- 教什么(技能)
- 用在哪(应用)
数据增强是个秘密武器,能造出好教材,让小模型学得更好。论文还给了很多例子和方法(具体看图 2 位置:Fig. 2: An overview of this survey)。
如果你感兴趣,可以去他们的 GitHub(https://github.com/Tebmer/Awesome-Knowledge-Distillation-of-LLMs)找更多资料。