解析一个doc文件中的内容:深入理解其结构与标签提取
微软Word文档的格式演变
微软Word文档的格式经历了多个版本的演变,主要分为Office 97-03和Office 07以后的OpenXML格式。Office 97-03采用OLE(对象链接与嵌入)技术,这是一种COM对象的子集,可以包含文本、图形、电子表格等多种二进制数据。OLE对象由对象头和数据流组成,通过特定的分隔符进行分割。而Office 07及其后的版本则采用了OpenXML格式,这是微软在Office 2007中提出的一种新的文档格式,并成为ECMA国际标准的一部分。OpenXML格式的文件实际上是一个压缩包,其中包含多个XML文件,分别存储文档的各个部分,如内容、属性、关系等。
探索Word文档的内部结构
探索Word文档的内部结构是理解如何解析和提取其内容的基础。我们可以通过创建一个简单的Word文档,输入一些易于识别的内容,如文本框和表格,然后将文档后缀修改为.zip,解压后可以看到其目录结构。主要的内容文件是word/document.xml,其中的文本被</w:t>标签包围。通过解析这些XML文件,可以获取到文档的文字内容,以及其他相关信息。对于页眉和页脚的内容,还需要解析word/header1.xml和word/foot1.xml等文件。
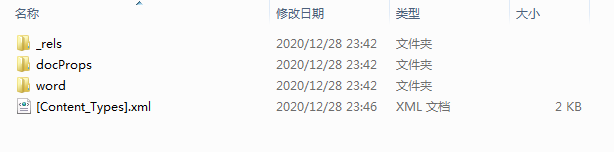
如何解析document.xml文件
解析document.xml文件可以获取到Word文档中的文字内容。文本可能存在于正文、表格、文本框等位置。对于正文中的内容,可以直接读取XMLStreamConstants.CHARACTERS类型的内容。但如果文档中包含表格和文本框,直接解析可能会导致格式错误,如表格失去形状或文本框内容重复。解决这些问题的方法是在解析时根据结束标签的不同,执行相应的动作。例如,表格中单元格结束时追加制表符,行结束时追加换行符等。
import javax.xml.stream.XMLStreamConstants;
import javax.xml.stream.events.XMLEvent;
// 示例代码:读取XML中的字符内容
XMLEvent event = ...; // 获取事件
if (event.getEventType() == XMLStreamConstants.CHARACTERS) {
Characters characters = event.asCharacters();
String data = characters.getData();
// 处理文字数据
}pywordform模块的使用
pywordform是一个用于解析Word文档的Python模块,能够提取文档中的标签及其对应的值,并以Python字典的形式返回。安装pywordform非常简单,只需在命令行中运行pip install pywordform即可。使用该模块,可以快速加载Word文档,并通过extract_tags()方法获取到所有标签信息。以下是一个简单的代码示例:
import pywordform
file_path = 'example.docx'
doc = pywordform.load(file_path)
tags = doc.extract_tags()
print(tags)批量处理Word文档
在需要处理大量Word文档的场景下,pywordform支持批量处理功能。可以编写一个循环,遍历指定目录下的所有Word文件,并调用pywordform的相关方法进行解析。这种批处理方式能够大幅提高效率,特别是在需要定期更新大量报告的企业环境中。
处理Word文档中的图片
现代Word文档中常常包含图片和图表,pywordform提供了对这些非文本组件的支持。通过API接口,开发者可以访问文档中的图片元素,进一步增强了文档处理的灵活性。这对于需要综合分析多种类型数据的应用场景而言,具有重要意义。

文档解析中的常见问题
在Word文档解析过程中,可能会遇到格式复杂或非标准标签导致的解析失败。pywordform提供了一系列调试工具和选项,帮助用户诊断并解决问题。良好的错误处理机制和灵活的配置选项是克服这些障碍的关键。此外,用户可以自定义标签提取规则,以应对特定的业务需求。
总结
通过本文的介绍,我们了解了Word文档的结构及其解析方法,并掌握了如何使用pywordform模块来提高处理效率。无论是法律、财务,还是医疗行业,pywordform都能提供有效的解决方案。随着模块的不断更新,未来将支持更多类型的文档元素,拓展其应用场景。
FAQ
-
问:如何安装pywordform模块?
- 答:可以通过运行命令
pip install pywordform来安装该模块。
- 答:可以通过运行命令
-
问:pywordform可以处理哪些类型的Word文档?
- 答:pywordform主要用于解析.docx格式的Word文档。
-
问:如何提取Word文档中的图片?
- 答:pywordform提供了API接口,可以通过该接口访问Word文档中的图片元素。
-
问:pywordform支持批量处理吗?
- 答:是的,pywordform支持批量处理多个Word文档。
-
问:遇到解析失败时如何解决?
- 答:可以使用pywordform提供的调试工具和选项来诊断和解决问题。