MiniMax微调方法:突破传统,创新未来
文章目录
MiniMax-01系列的革命性突破
MiniMax于2025年1月15日宣布开源其全新系列模型MiniMax-01,该系列包括基础语言大模型MiniMax-Text-01和视觉多模态大模型MiniMax-VL-01。这一系列在架构上实现了大胆的创新,首次大规模应用了线性注意力机制,打破了传统Transformer架构的局限。其参数量高达4560亿,并且能够处理长达400万token的上下文。
随着AI Agent的兴起,2025年被视为Agent快速发展的关键年份。无论是单Agent还是多Agent系统,都需要更长的上下文来支持持续记忆和大量通信。MiniMax-01系列模型的推出正是为了满足这一需求,为复杂Agent基础能力的建立迈出重要一步。
MiniMax模型的创新亮点
MiniMax-01系列模型的创新体现在多个方面。首先是其高达4560亿的参数量和线性注意力机制的首次大规模应用。这使得MiniMax在处理长输入时的效率极高,接近线性复杂度,能够高效处理长达400万token的上下文,是GPT-4o的32倍、Claude-3.5-Sonnet的20倍。
为了实现这一突破,MiniMax在Scaling Law、与MoE结合、结构设计、训练优化和推理优化等方面进行了综合考量,并重构了训练和推理系统,包括更高效的MoE All-to-all通讯优化、更长序列优化以及推理层面的线性注意力的高效Kernel实现。
MiniMax-Text-01的性能表现
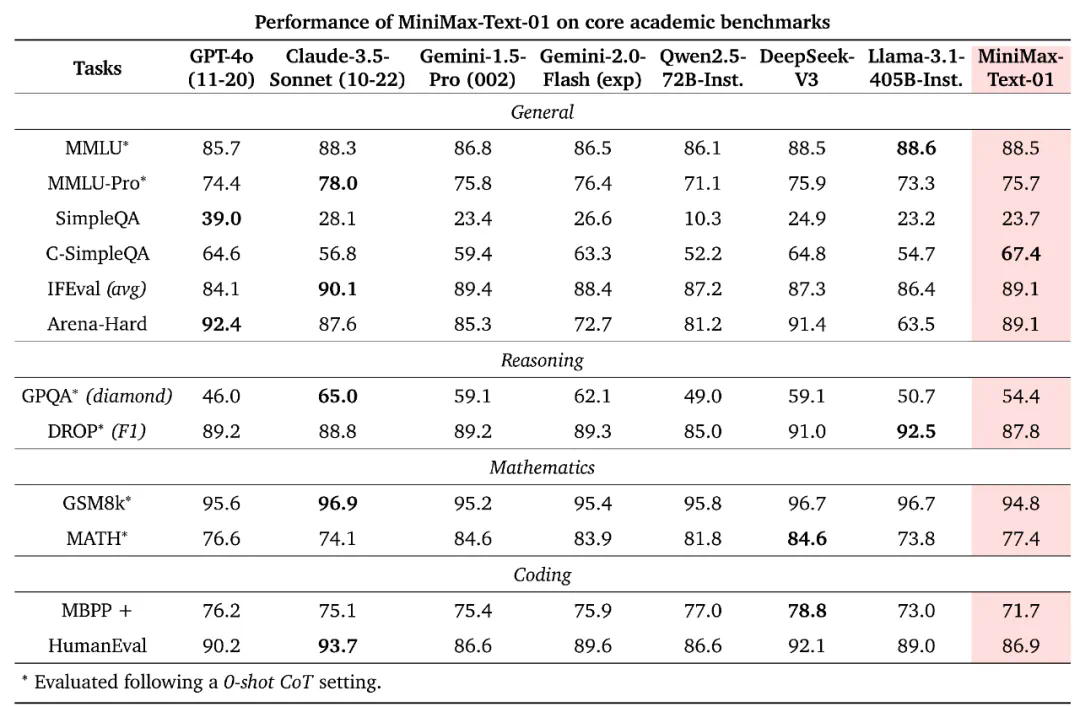
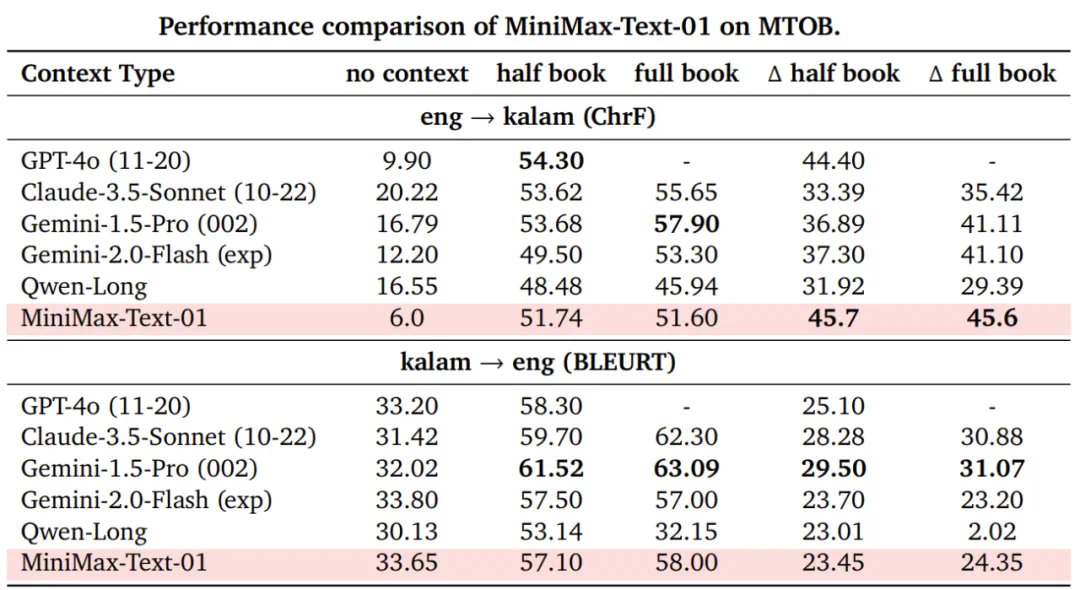
在业界主流的文本和多模态理解测评中,MiniMax-01系列在多数任务上追平了海外公认的先进模型,如GPT-4o-1120和Claude-3.5-Sonnet-1022。尤其是在长文任务上,MiniMax-Text-01随着输入长度增加,性能衰减最慢,显著优于Google的Gemini模型。
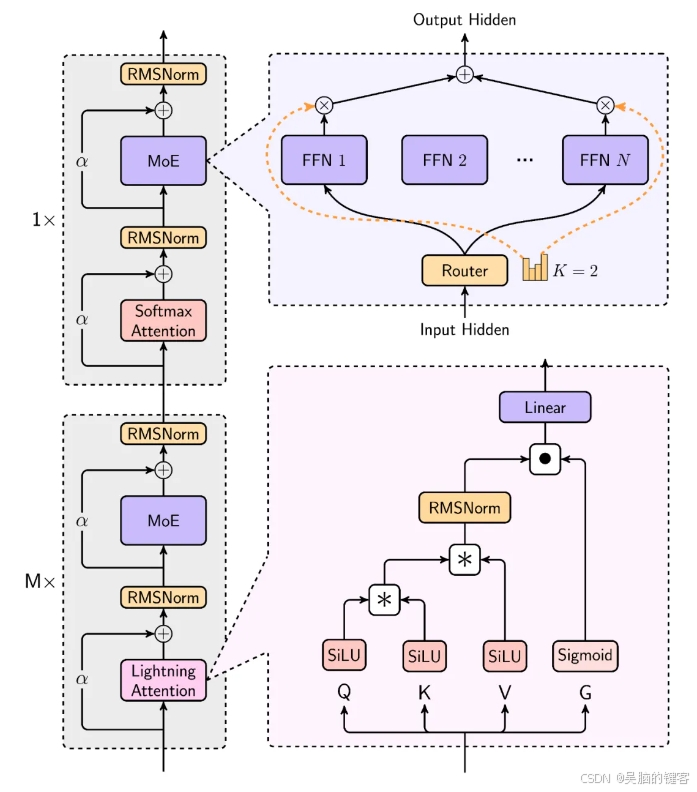
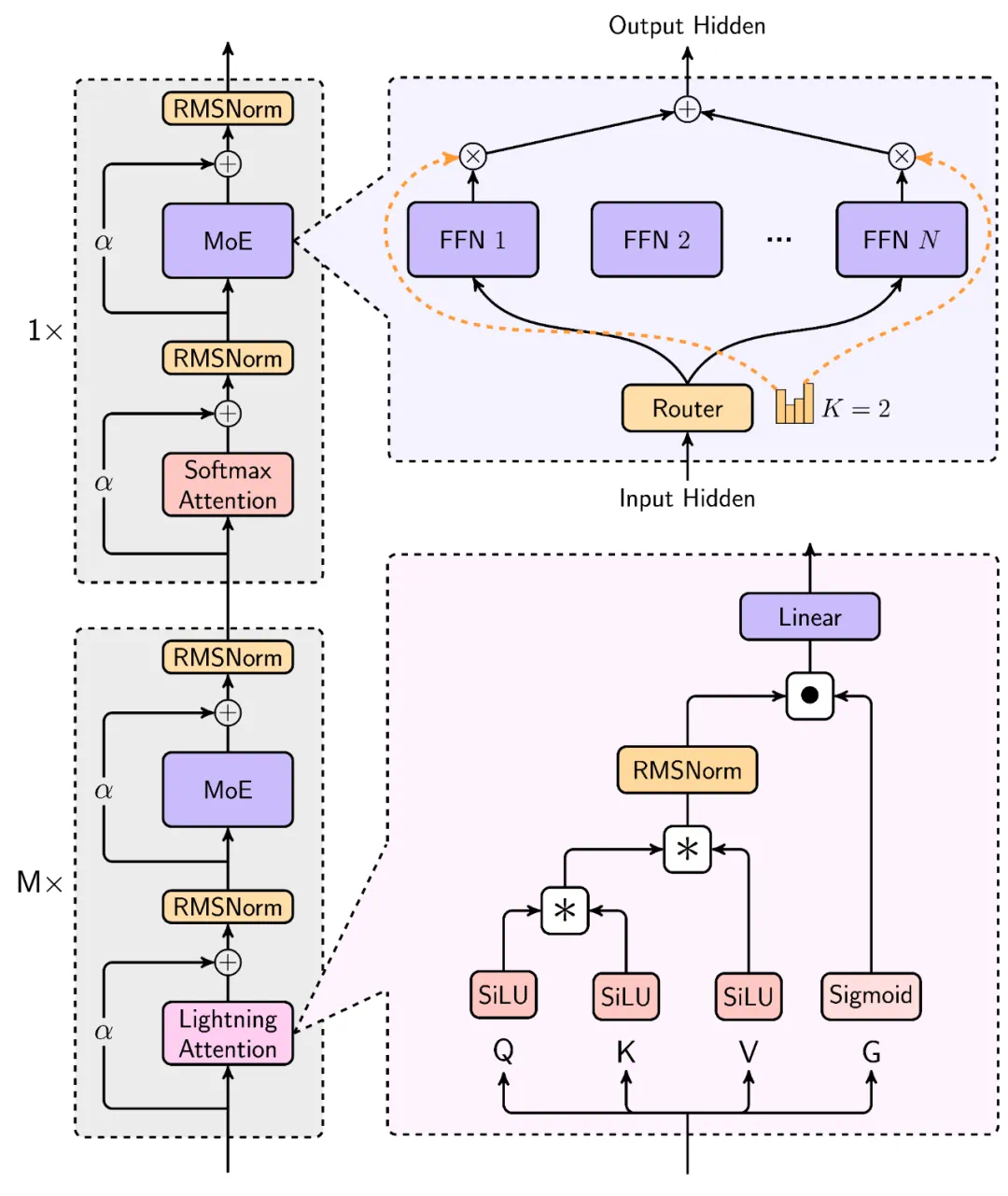
MiniMax的模型在处理长输入时效率极高,接近线性复杂度。其结构设计中,每8层中有7层采用基于Lightning Attention的线性注意力,1层采用传统SoftMax注意力。这是业内首次将线性注意力机制扩展到商用模型级别。
MiniMax-VL-01的多模态理解能力
MiniMax还开发了一个多模态版本:MiniMax-VL-01,其整体架构符合比较常见的ViT-MLP-LLM范式。在文本模型的基础上整合了一个图像编码器和一个图像适配器,以将图像转换成LLM能够理解的token形式。
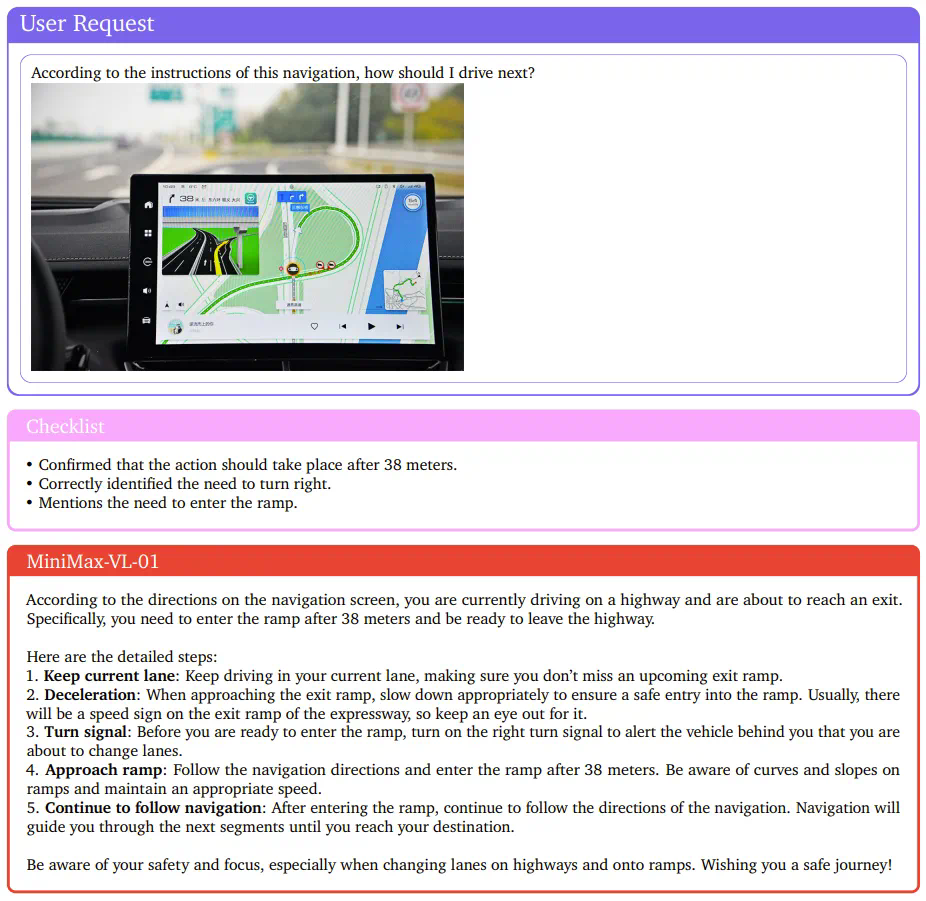
为了确保MiniMax-VL-01的视觉理解能力,MiniMax设计了一个专有数据集,并实现了一个多阶段训练策略。最终,MiniMax-VL-01在各个基准上表现出色,在某些指标上达到最佳。
MiniMax的经济性与开放性
得益于架构创新、效率优化和集群训推一体设计,MiniMax能够以业内最低的价格区间提供文本和多模态理解的API服务。标准定价为输入token1元/百万token,输出token8元/百万token。MiniMax开放平台及海外版已上线,供开发者体验使用。

MiniMax-01系列模型已在GitHub开源,并将持续更新。开发者可以通过GitHub访问开源代码:MiniMax开源地址。
MiniMax的未来发展
MiniMax团队表示,他们正在研究更高效的架构,以完全消除SoftMax注意力,这可能使模型能够支持无限的上下文窗口,而不会带来计算开销。除此之外,MiniMax还在LLM的基础上训练的视觉语言模型,同样拥有超长的上下文窗口。这也是由Agent所面临的任务所决定的。
MiniMax创始人在去年的一次活动中提到:「我们认为下一代人工智能是无限接近通过图灵测试的智能体,交互自然,触手可及,无处不在。」
MiniMax微调方法的应用
Lightning Attention的技术细节
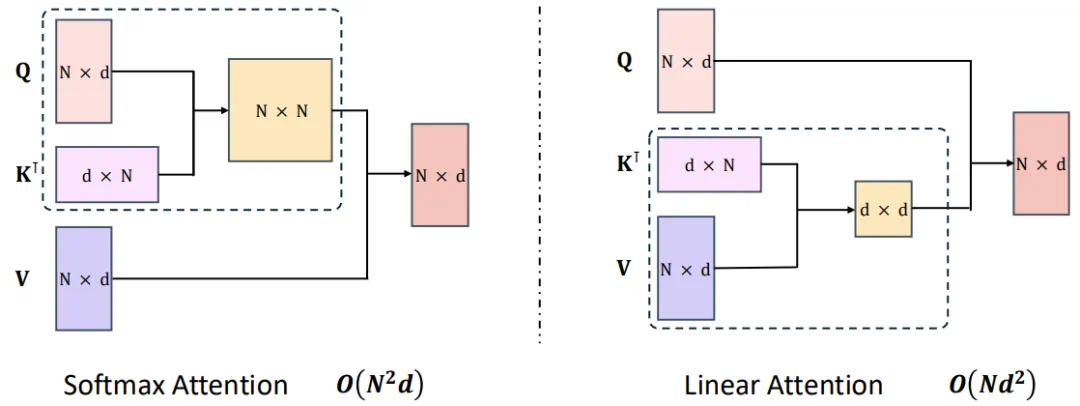
Lightning Attention是MiniMax在优化Transformer自注意力机制方面的重大突破。通过使用这种线性注意力,原生Transformer的计算复杂度从二次复杂度大幅下降到线性复杂度,这主要得益于一种右边积核技巧(right product kernel trick)。
混合专家架构的优势
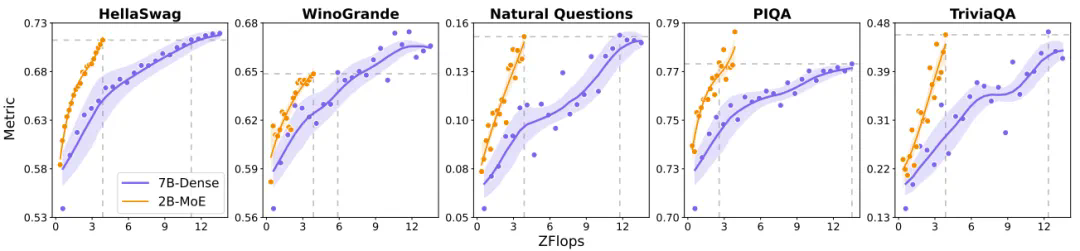
混合专家(MoE)相对于密集模型的效率优势已经得到了大量研究证明。MiniMax团队同样通过实验验证了这一点,其MoE架构在多种基准上表现优于密集模型。
长上下文处理的优化
为了更好地处理长上下文,MiniMax采用了数据格式化技术,即将不同样本沿序列的维度首尾相连,减少计算浪费。这种方法被称为data-packing,是优化长上下文训练的关键所在。
跨步分批矩阵乘法扩展
MiniMax在实践中应用了包括分批核融合、分离式的预填充与解码执行、多级填充、跨步分批矩阵乘法扩展等四项优化策略,以将Lightning Attention投入实际应用。

FAQ
问:MiniMax-01系列模型的主要创新点是什么?
答:MiniMax-01系列模型在架构上首次大规模应用了线性注意力机制,能够处理长达400万token的上下文,是其他模型的20-32倍。
问:MiniMax如何优化长上下文处理?
答:MiniMax采用了数据格式化技术,将不同样本沿序列的维度首尾相连,减少计算浪费,并使用Lightning Attention降低计算复杂度。
问:MiniMax开放平台的定价如何?
答:MiniMax提供业内最低的价格区间,输入token1元/百万token,输出token8元/百万token。
问:MiniMax-VL-01的多模态理解能力如何?
答:MiniMax-VL-01在各个基准上表现出色,其整体架构符合ViT-MLP-LLM范式,能够处理多模态任务。
问:未来MiniMax的研究方向是什么?
答:MiniMax正在研究更高效的架构,以完全消除SoftMax注意力,实现支持无限上下文窗口的模型。