基于 MidJourney 的 RAG 系统:洞悉核心技术与应用
随着技术与应用。
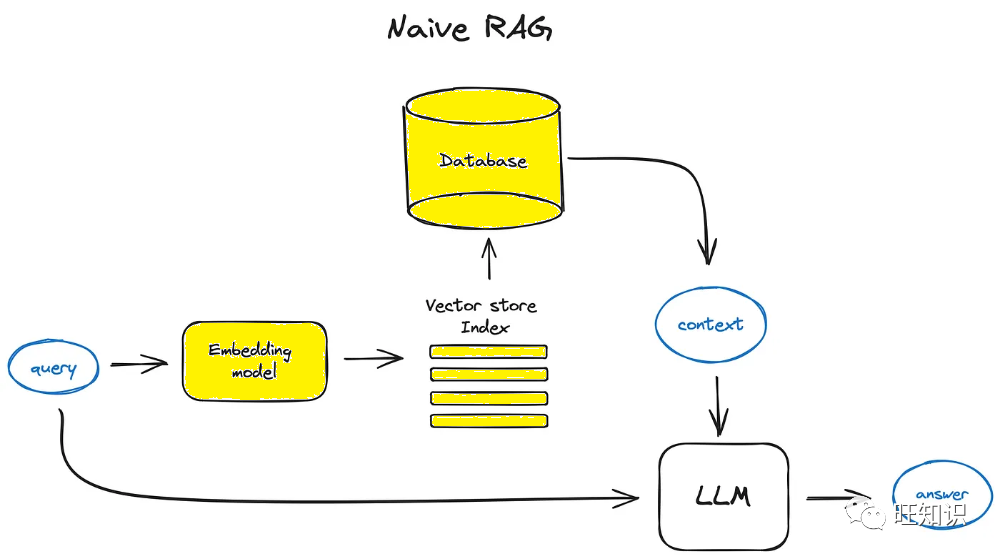
RAG 技术的基本原理
RAG 技术通过结合检索和生成的过程,提供更加准确和事实可靠的生成内容。一般来说,RAG 包括两个主要阶段:
检索上下文相关信息
在这个阶段,系统会通过检索算法从庞大的数据源中获取与用户查询相关的信息。这些信息将作为上下文,为生成模型提供基础。
使用检索到的知识指导生成过程
在生成阶段,检索到的上下文信息被注入到生成模型中,指导其生成更加符合事实的内容。这一过程有效地减少了生成模型的幻觉倾向,提高了其生成内容的准确性和合理性。
基于 MidJourney 的图像生成与 RAG 的结合
MidJourney 是一种先进的图像生成工具,它能够将文本描述转化为视觉图像。在结合 RAG 后,MidJourney 的图像生成能力得到了进一步提升。
图像生成的基础原理
MidJourney 利用深度学习模型,特别是生成对抗网络(GAN),将输入的文本描述转化为高质量的图像。通过解析文本中的关键元素,MidJourney 可以创建出符合用户期望的图像。
RAG 在图像生成中的作用
通过引入 RAG 技术,MidJourney 能够从外部数据源中获取更多上下文信息,从而生成更加准确和多样化的图像。这种结合不仅提高了图像生成的质量,还拓展了其在不同场景中的应用。

深入探讨 RAG 的高级技术
RAG 的高级技术包括分块、矢量化、搜索索引等,这些技术的结合使得 RAG 系统在处理复杂任务时更加高效。
分块与矢量化
在分块过程中,文本被分割成若干小块,以便于后续的矢量化处理。矢量化的目的是将文本块转化为数学向量,从而便于计算机处理和检索。
分块技术的关键因素
分块的策略直接影响到系统的检索性能。在实施分块时,需要考虑文本的性质、嵌入模型的特点和用户查询的复杂性。
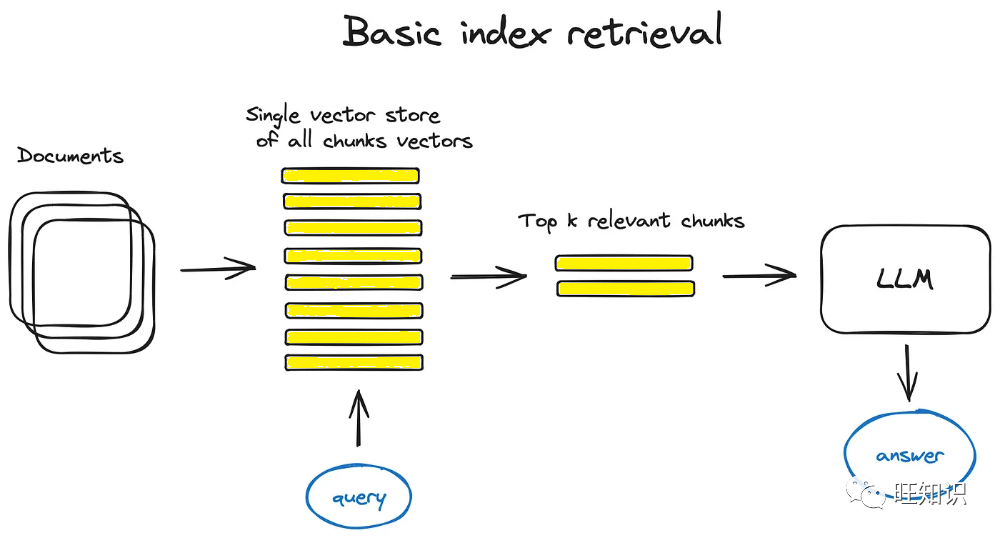
搜索索引的构建
搜索索引是 RAG 系统的重要组成部分,它负责存储和管理矢量化后的文本块。通过高效的索引结构,系统能够快速检索到相关信息。
向量存储索引
向量存储索引是一个用于存储矢量化数据的数据库。它支持高效的相似度搜索,使得系统能够快速响应用户查询。
层次索引的应用
对于大型数据集,层次索引可以提高检索效率。通过多级索引结构,系统能够在更少的时间内检索到更加准确的结果。
混合检索技术在 RAG 中的应用
混合检索技术结合了关键词检索和语义检索的优势,通过多种策略提高检索的准确性和全面性。
混合检索的基本概念
混合检索是一种结合多种检索方法的策略,旨在克服单一检索方法的局限性。通过同时考虑关键字匹配和语义相似性,混合检索可以提供更为全面的检索结果。
实现混合检索的步骤
实现混合检索需要多个步骤,包括文本分块、向量化、关键词提取和相似度计算等。通过这些步骤,系统可以有效地结合不同的检索方法,提升检索效果。
import dashscope
from http import HTTPStatus
import numpy as np
import jieba
from jieba.analyse import extract_tags
import math
dashscope.api_key = 'sk-xxxx'def embed_text(text):
resp = dashscope.TextEmbedding.call(
model=dashscope.TextEmbedding.Models.text_embedding_v2,
input=text)
if resp.status_code == HTTPStatus.OK:
return resp.output['embeddings'][0]['embedding']
else:
print(f"Failed to get embedding: {resp.status_code}")
return None```
## RAG 系统的优势与挑战
### 优势
RAG 系统通过结合检索与生成的技术,显著提高了生成内容的准确性和可信度。此外,RAG 系统具有高度的灵活性,可以适应各种应用场景。
### 挑战
尽管 RAG 系统具有诸多优势,但其实施也面临一些挑战。例如,如何平衡检索和生成之间的效率,以及如何处理大规模数据等问题。
## 结论与展望
RAG 技术作为一种有效的生成增强方法,在提升模型生成质量方面具有显著优势。随着技术的不断进步,RAG 系统将在更多领域中发挥重要作用,推动[生成式 AI](https://www.explinks.com/blog/ai-large-model-class-api-the-core-engine-driving-ai-innovation) 的进一步发展。
### FAQ
1. __问:什么是 RAG 技术?__
- 答:检索增强生成(RAG)技术通过结合信息检索和生成的过程,提高生成内容的准确性和事实性。
2. __问:RAG 如何提高生成模型的准确性?__
- 答:[RAG 通过检索](https://www.explinks.com/blog/wx-comprehensive-explanation-of-large-models-rag-retrieval-augmentation-generation)相关的上下文信息,并将其注入到生成模型中,指导模型生成更加符合事实的内容。
3. __问:MidJourney 如何利用 RAG 技术生成图像?__
- 答:MidJourney 通过结合 RAG 技术,从外部数据源中获取更多上下文信息,生成更加准确和多样化的图像。
4. __问:混合检索技术的作用是什么?__
- 答:混合检索技术通过结合关键词检索和语义检索,提高了检索结果的准确性和全面性。
5. __问:RAG 系统面临的主要挑战有哪些?__
- 答:RAG 系统面临的挑战包括检索和生成之间的效率平衡以及大规模数据处理等问题。