基于 OpenAI GPT-4 的 RAG 系统:深度解析与优化策略
在当今的人工智能领域,长上下文生成与检索(RAG)技术已成为提升自然语言处理(NLP)模型性能的关键方法之一。随着数据规模的日益扩大,如何高效处理海量上下文信息成为了研究与应用的重点课题。本文将深入探讨OpenAI最新发布的O1-preview和O1-mini模型在长上下文RAG任务中的表现,比较其与其他先进模型如GPT-4o和Google Gemini 1.5的性能差异,并提供实用的优化建议,帮助开发者在构建大型语言模型(LLM)应用时实现更高效的性能表现。

长上下文RAG的技术背景
长上下文RAG技术通过在生成过程中引入检索机制,使模型能够处理更大规模的上下文信息,从而显著提升了回答的准确性与相关性。这项技术的核心在于其能够从海量数据中检索相关信息并进行生成,这对于当前复杂且多变的应用场景至关重要。
RAG的基本原理与实现
RAG系统通过将生成和检索过程紧密结合,既利用生成模型的强大表达能力,又依赖检索机制来提供上下文支持,从而提升整体性能。通过优化生成和检索的交互,RAG可以在较长的上下文中保持高效运作。
RAG的实际应用
在实际应用中,长上下文RAG技术被广泛应用于文本生成、问答系统和内容总结等领域。这些应用要求系统能够处理复杂的上下文信息,并在生成阶段调用相关的背景知识。这使得RAG技术成为AI开发者和研究人员关注的热点。
OpenAI O1模型概述
OpenAI的O1模型分为O1-preview和O1-mini两个版本。自2023年10月发布以来,O1模型凭借其卓越的长上下文处理能力迅速获得关注。该模型在多个长上下文RAG基准测试中表现出色,尤其是在处理超过百万级词元的超长文本时展现了显著优势。
O1-preview与O1-mini的区别
O1-preview在特定任务中超越了GPT-4o,显示出其强大的泛化能力和适应性。O1-mini则在性能上几乎与GPT-4o持平,但在处理超长上下文时表现出色。

O1模型在长上下文RAG基准测试中的表现
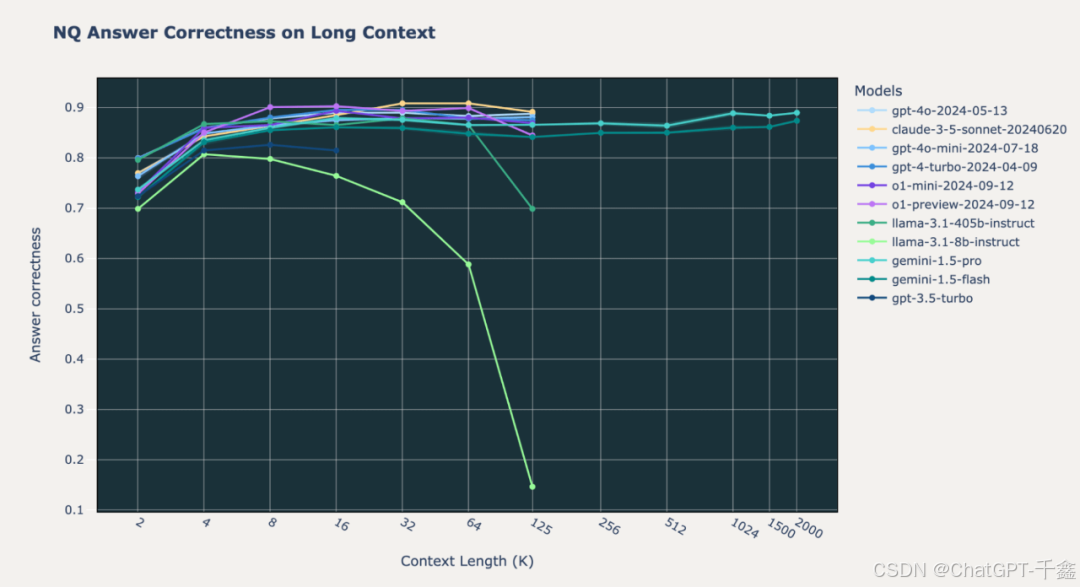
我们将O1模型在多个数据集上的表现进行详尽分析,包括Databricks DocsQA、FinanceBench和Natural Questions (NQ)。O1-preview和O1-mini在所有上下文长度下的表现显著优于GPT-4o和Google Gemini模型。
与Google Gemini 1.5模型的对比
Google Gemini 1.5 是市场上另一款领先的长上下文RAG模型,拥有Pro和Flash两个版本。Gemini 1.5在多个基准测试中展示了其独特的优势,尤其是在处理超长上下文时的稳定性。
Gemini 1.5在超长上下文下的稳定性
Gemini 1.5在超长上下文下能够维持一致的回答质量,并通过优化算法有效控制了资源消耗,使其在长文档处理上具有成本效益。
成本与开发便捷性的权衡
对于开发者而言,选择合适的模型需权衡性能与成本。Gemini 1.5在长上下文处理上的优势意味着在某些应用场景下可以简化开发流程,而O1模型则在需要高准确性和相关性的应用中表现优异。
LLM在长上下文RAG中的失败模式分析
尽管大型语言模型在长上下文RAG任务中表现强大,但在实际应用中仍然存在多种失败模式。这些模式的理解对于优化系统性能和提高稳定性至关重要。
OpenAI O1-preview与O1-mini的失败模式
O1模型的失败案例包括重复内容、随机内容、未遵循指令、空响应、错误答案和拒绝回答等问题。特别是在推理步骤的词元长度不可预测时,可能出现空响应。
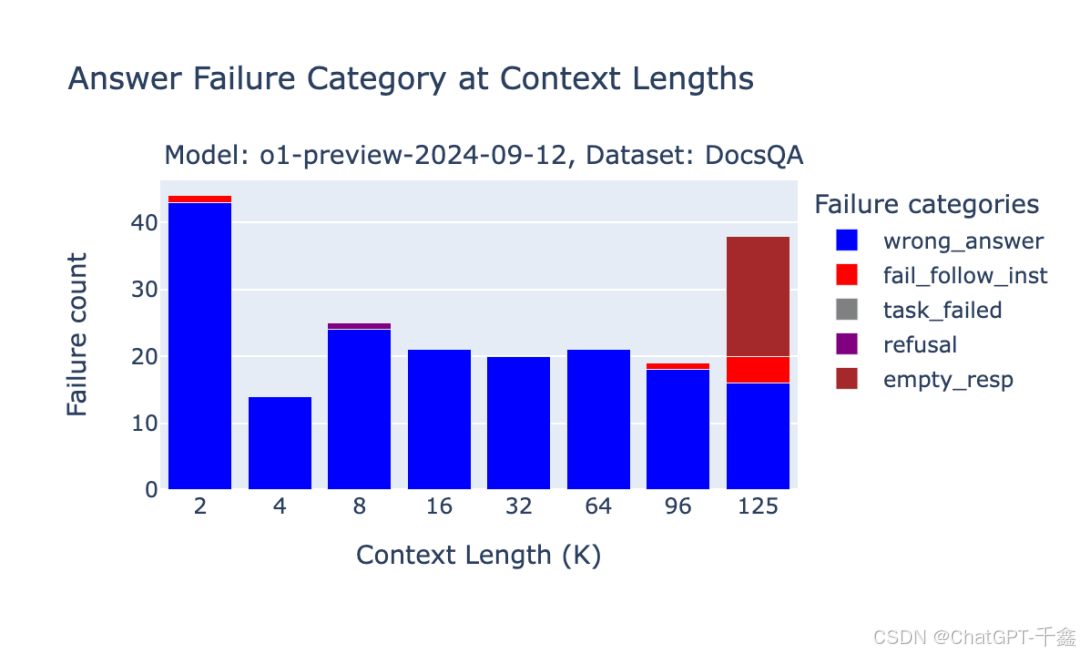
Google Gemini 1.5的失败模式
Gemini 1.5的失败模式包括主题敏感性、拒绝回答和BlockedPromptException错误。这些问题主要源于提示内容的过滤和上下文信息的不完整。
优化长上下文RAG性能的策略
针对上述模型的表现与失败模式,开发者可以采取以下策略来优化长上下文RAG的性能。
选择合适的模型与上下文长度
根据具体应用需求选择最合适的模型与上下文长度是提升RAG性能的关键。对于高准确性应用推荐使用O1-preview或O1-mini,而超长文本处理则选择Gemini 1.5。
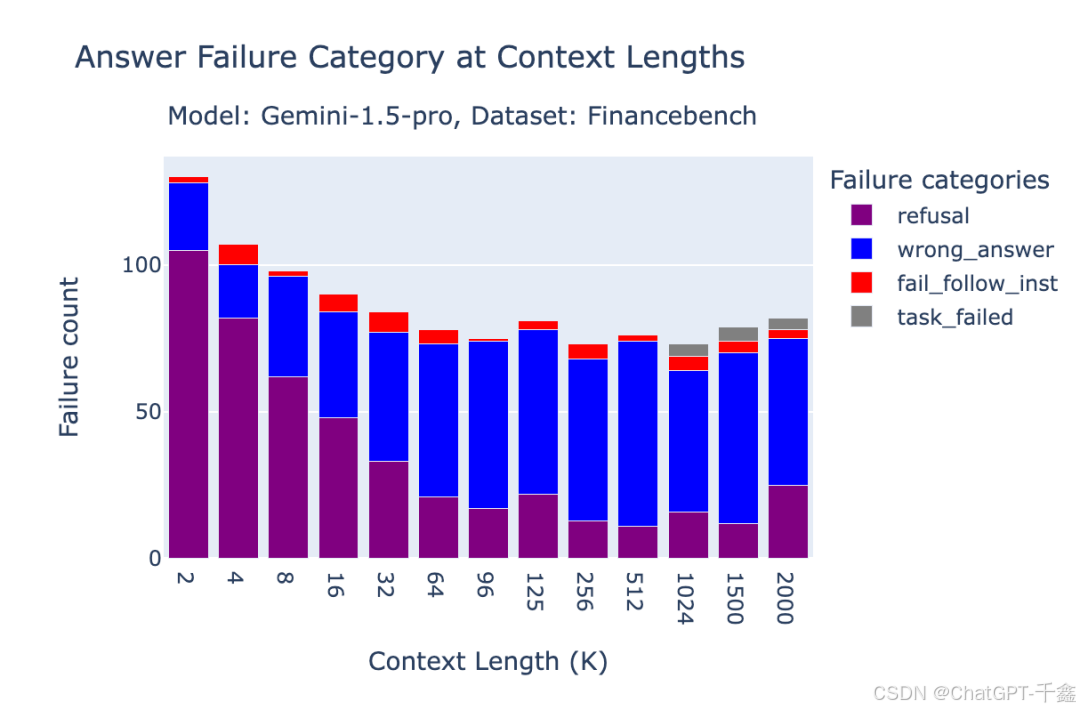
改进检索步骤以提升性能
优化检索算法能够确保检索到的文档与问题高度相关,从而提升模型的回答质量。动态调整输入的上下文长度也能帮助模型在不同任务中获得足够的信息支持。
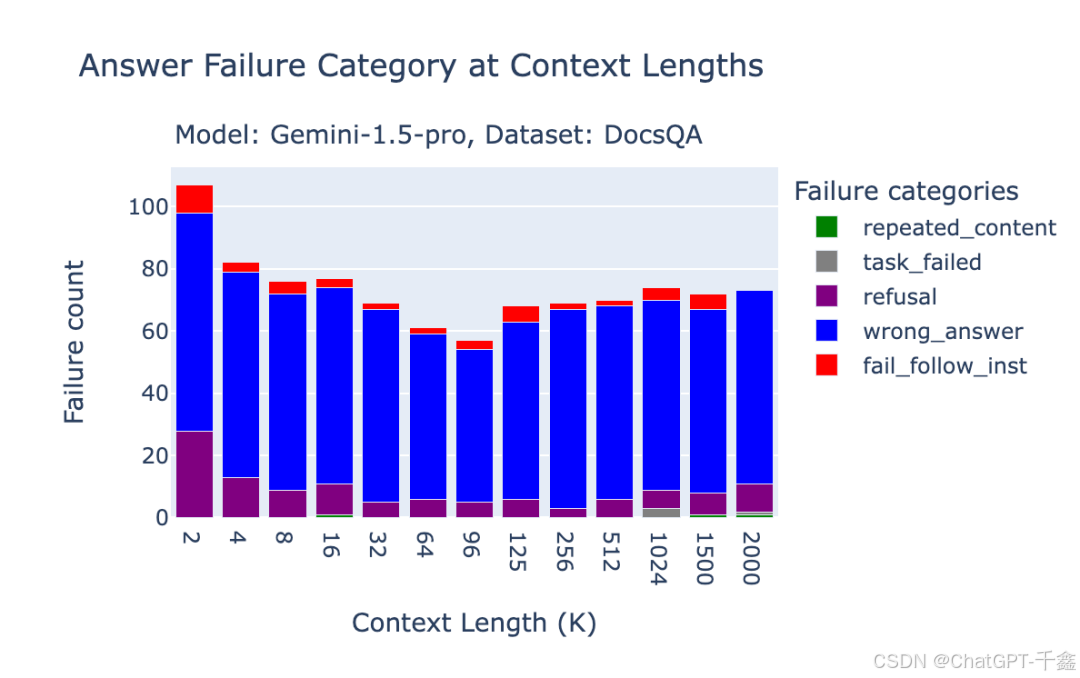
处理模型的失败模式
采取内容过滤与指令优化、多模型协同及错误监控与反馈机制等措施,能够显著提高系统的稳定性和用户体验。
结论:未来的发展与展望
随着AI技术的不断进步,长上下文RAG在各种应用场景中的重要性日益凸显。OpenAI O1模型的发布展示了其在处理长上下文任务上的强大能力,而Google Gemini 1.5在超长上下文处理上的独特优势提供了更多选择。
FAQ
-
问:什么是长上下文生成与检索(RAG)技术?
- 答:RAG技术通过在生成过程中引入检索机制,使模型能够处理更大规模的上下文信息,从而提升回答的准确性与相关性。
-
问:O1-preview和O1-mini模型的区别是什么?
- 答:O1-preview在一些特定任务中超越了GPT-4o,显示出其强大的泛化能力,而O1-mini在性能上几乎与GPT-4o持平。
-
问:如何选择合适的长上下文RAG模型?
- 答:根据具体应用需求选择最合适的模型与上下文长度。对于高准确性应用推荐使用O1-preview或O1-mini,而超长文本处理则选择Gemini 1.5。
-
问:如何优化长上下文RAG的性能?
- 答:通过选择合适的模型与上下文长度、改进检索步骤、处理模型的失败模式等方法,可以显著优化长上下文RAG的性能。
-
问:Google Gemini 1.5在RAG任务中的优势是什么?
- 答:Gemini 1.5在处理超长上下文时表现出色,能够维持一致的回答质量,并通过优化算法有效控制了资源消耗。