Embedding是什么及其在机器学习中的应用
嵌入(Embedding)是一种技术,用于将高维向量映射到相对低维的空间中,以便更有效地表示和处理数据。它在机器学习和深度学习中扮演着重要角色,通过捕捉输入数据的语义相似性,使得语义相似的输入在嵌入空间中更加接近。这种技术被广泛应用于文本处理、自然语言处理等领域,能够降低特征维度和计算复杂度,同时增强模型的通用性和准确性。
Embedding的基本概念
什么是Embedding
Embedding是将高维向量转换到一个较低维的空间中,这使得机器学习可以在大规模输入上更高效地进行操作。Embedding的目标是将语义相似的输入紧密地放置在这个新空间中,以便更好地捕获输入的语义信息。
Embedding如何应用
在文本处理中,Embedding常用于将词语转换为可计算的向量形式。这种方法不仅可以节省空间,还能在向量空间中保留词语之间的语义关系,使得相似的词在向量空间中相邻。
谷歌的解释
根据谷歌的描述,Embedding是跨模型学习和重用的有力工具。这意味着一旦学得的Embedding可以在多个不同的任务中重复使用,提升模型的泛化能力。
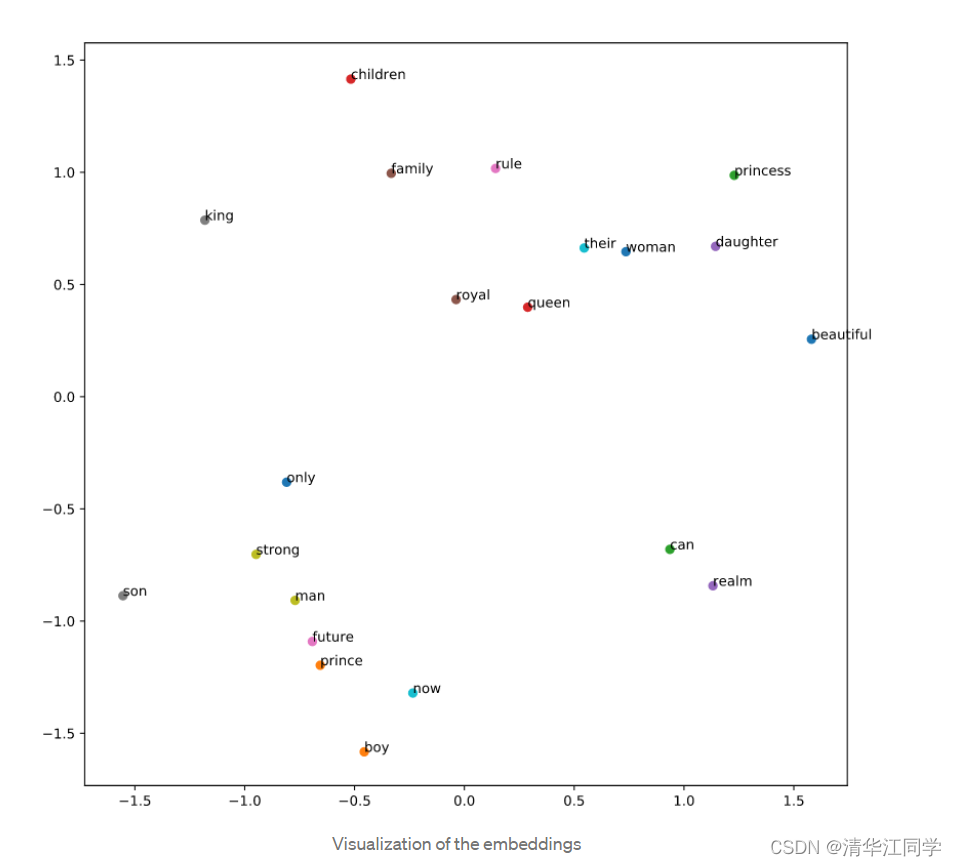
嵌入在文本处理中的应用
文本向量化
文本是非结构化的信息,要使机器理解文本,首先需要将其转换为结构化的数据。这通常通过索引化、独热编码和向量表示来实现。
索引化与独热编码
索引化用一个数字来代表一个词,而独热编码则用二进制位来表示词,尽管这些方法简单直观,但它们无法表达词语之间的关系,尤其在大语料下会显得稀疏且占用大量空间。
向量表示的优势
相比之下,Embedding提供了一种更加紧凑且语义表达能力更强的向量化方法,可以在不同任务中通用。
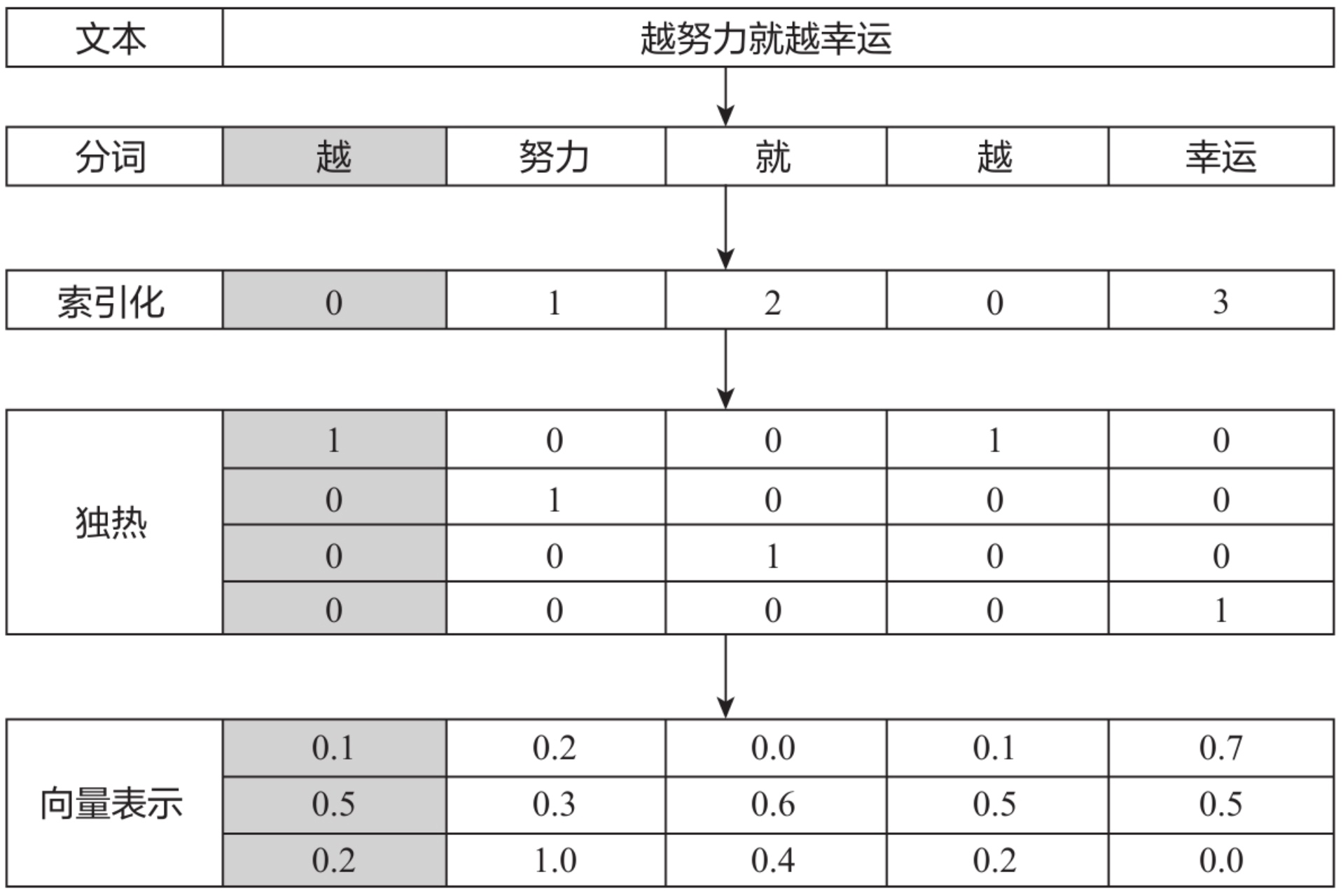
索引化独热编码与向量表示
索引化的特点
索引化的优点在于其直观性,因为每个词都有唯一的数字标识。但缺点在于无法捕获词语之间的关系,并且在大语料中会导致数据量巨大。
独热编码的优缺点
独热编码可以快速计算和表达能力强,但这种方法在大语料下空间占用大,计算效率低,无法捕捉词语关系。
向量表示的创新
相比传统方法,Embedding通过低维向量表达词语,不仅节约空间,还能更好地表达词语之间的关系。
词嵌入的主要特点
低维表示
词嵌入可以将文本通过低维向量来表达,避免了one-hot编码的高维度问题。这种低维表示使得计算更加高效。
语义相似性
在词嵌入的向量空间中,语义相似的词会更接近。这种相似性帮助模型在不同的任务中更好地理解文本。
通用性
词嵌入具有高度的通用性,可以在不同的自然语言处理任务中重复使用,节省了重新训练的时间和资源。
Embedding的压缩本质
数据压缩
Embedding的本质是数据压缩,用较低维度的特征来描述有冗余信息的高维特征。这种压缩不仅提高了计算效率,还减少了存储空间。
信息丢失
尽管Embedding通常会丢失一些信息,但这些信息大多是冗余的。例如,在描述智力时,某些身体信息可以被忽略。
冗余信息处理
Embedding在处理过程中,会舍弃与任务无关的冗余信息,保留关键特征以提高模型的性能。
语义相似性的向量空间表示
向量空间关系
Embedding在向量空间中能够保持样本的语义关系。即使是不同的语言,也能通过Embedding找到相似的词语和短语。
算术运算
在词嵌入中,可以通过简单的向量运算来推导出新的语义关系。例如,巴黎减去法国再加上英格兰,会接近伦敦的向量。
语义关系
这种向量关系帮助我们发现词汇之间的深层语义关系,从而提升机器学习模型的理解能力。
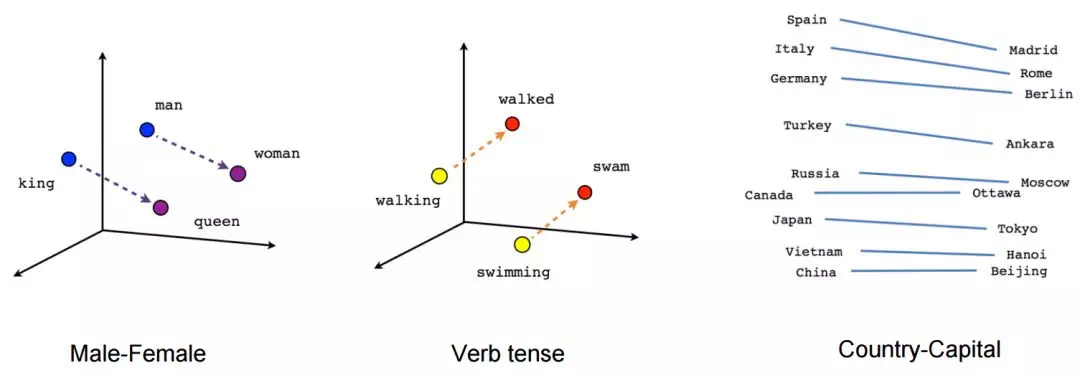
Embedding的意义与优势
自然语言计算
Embedding将自然语言转化为一串数字,使得文本数据可以被计算和分析。在自然语言处理中,Embedding大幅提升了模型的性能。
降低维度
Embedding替代了独热编码和协同矩阵,极大地降低了特征的维度和计算复杂度,提升了计算效率。
学习能力
在训练中,Embedding可以不断学习和更新,获取不同任务的语义信息,从而提升模型的表现。

# 简单的词嵌入示例
from gensim.models import Word2Vec
# 训练模型
sentences = [['吃饭', '喝水'], ['喝水', '健康']]
model = Word2Vec(sentences, min_count=1)
# 查看词嵌入
print(model.wv['吃饭'])FAQ
问:embedding是什么?
- 答:embedding是将高维向量转换到低维空间的过程,这使得机器学习能够更高效地处理大规模输入。embedding的目标是将语义相似的输入在新空间中紧密排列,以便更好地捕捉其语义信息。
问:embedding如何应用于文本处理中?
- 答:在文本处理中,embedding用于将词语转换为可计算的向量形式。这种方法节省空间并在向量空间中保留词语之间的语义关系,使得相似的词在向量空间中相邻。
问:embedding与索引化、独热编码有何不同?
- 答:embedding相比索引化和独热编码,提供了一种更紧凑且语义表达能力更强的向量化方法。索引化和独热编码在表达词语关系时较为有限,而embedding通过低维向量更好地捕获词语之间的关系。
问:embedding在自然语言处理中有哪些优势?
- 答:embedding在自然语言处理中将文本数据转化为可计算的数字串,大幅提升模型性能。它降低了特征维度和计算复杂度,并在训练中不断学习和更新,提升模型表现。
问:embedding是如何实现数据压缩的?
- 答:embedding通过低维度的特征来描述高维特征,压缩过程中舍弃与任务无关的冗余信息,保留关键特征。这种数据压缩提高了计算效率并减少了存储空间。