EasyAnimate 应用代码和优化详解
学习前言
EasyAnimate 是一个强大的视频生成工具,它基于 Transformer 架构,结合了扩散模型技术(Diffusion Transformer,简称 DiT),为用户提供了从文本生成视频的功能。与传统的图像生成模型不同,EasyAnimate 通过整合多种先进技术,如 Stable Diffusion 和 CogVideoX,进一步扩展了模型的规模和能力。EasyAnimate V5 版本不仅提升了模型的生成质量,还支持多种控制输入,提高了用户在视频生成上的灵活性。

相关地址汇总
源码下载地址
如果您希望深入了解 EasyAnimate 的实现,可以从下方链接下载源码:GitHub – EasyAnimate
HF测试链接
为了方便用户测试,我们提供了 Hugging Face 的在线测试链接:Hugging Face – EasyAnimate
测试效果
Image to Video
EasyAnimate 可以将静态图像转化为动态视频。以下是一些转换效果的示例:


Text to Video
通过简单的文本描述,EasyAnimate 可以生成对应的视频内容。以下是一些转换效果的示例:


EasyAnimate详解
技术储备
Diffusion Transformer (DiT)
DiT 是一种基于扩散模型的技术,其核心是通过不断去噪的过程生成图像或视频。与传统的生成对抗网络(GAN)不同,扩散模型通过逐步反向去噪来生成高质量的样本。此过程中使用了更快的采样器和更高的分辨率,保证了生成视频的质量。

Stable Diffusion 3
Stable Diffusion 3 在生成图像的过程中引入了多种创新,如使用 Self-Attention 替代 Cross-Attention 来引入文本信息,提高了模型的生图质量和效率。此外,引入了 RMS-Norm 和更大的 VQGAN 提升了模型的稳定性和特征维度。

CogVideoX
CogVideoX 是智谱开源的视频生成模型,其主要特点是通过 3D VAE 和 3D RoPE 位置编码模块提升了视频生成的水准。它能够在时间维度上更好地捕捉帧间关系,使视频生成更加流畅。

算法细节
EasyAnimateV5特点
EasyAnimate V5 在大规模数据集上进行了从零开始的训练,支持中文和英文的双语预测。与之前的版本相比,V5 版本不仅支持文生视频、图生视频和视频生视频,还在模型规模和控制能力上有了显著提升。
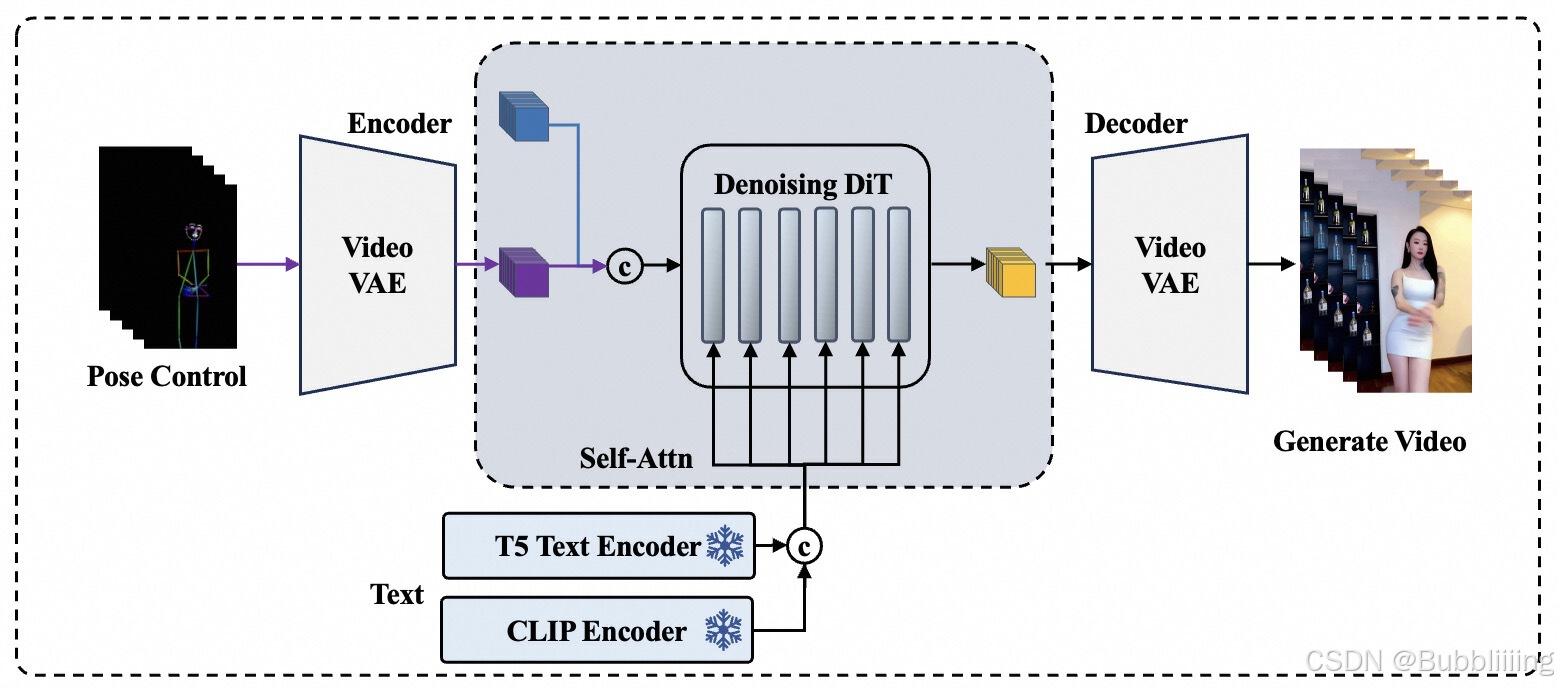
应用MMDIT结构,拓展模型规模到12B
通过参考 Stable Diffusion 3 和 CogVideoX,EasyAnimate 采用 MMDiT 架构,以实现更好的模态对齐。为了提高模型的理解能力,EasyAnimate V5 的参数量扩展到了 12B。
添加控制信号的EasyAnimateV5
在 EasyAnimate V5 中,我们使用控制信号取代了原本的 mask 信号,以提高模型对输入的响应能力。通过 VAE 编码的控制信号在训练中发挥了重要作用。
参考图片添加Noise
参考 CogVideoX 的实践,EasyAnimate V5 在生成视频时引入了噪声,以提高视频的动态性和生成效果。噪声的添加使得生成的视频更加自然和流畅。

基于Token长度的模型训练
EasyAnimate V5 的训练过程被分为多个阶段,每个阶段对应不同的 Token 长度,以适应不同的视频分辨率和帧数。通过多阶段训练,模型能够生成从 512 到 1024 像素的视频。
项目使用
项目启动
EasyAnimate V5 推荐通过 docker 启动,以保证环境的兼容性和稳定性。
docker pull mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
docker run -it -p 7860:7860 --network host --gpus all --security-opt seccomp:unconfined --shm-size 200g mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
git clone https://github.com/aigc-apps/EasyAnimate.git
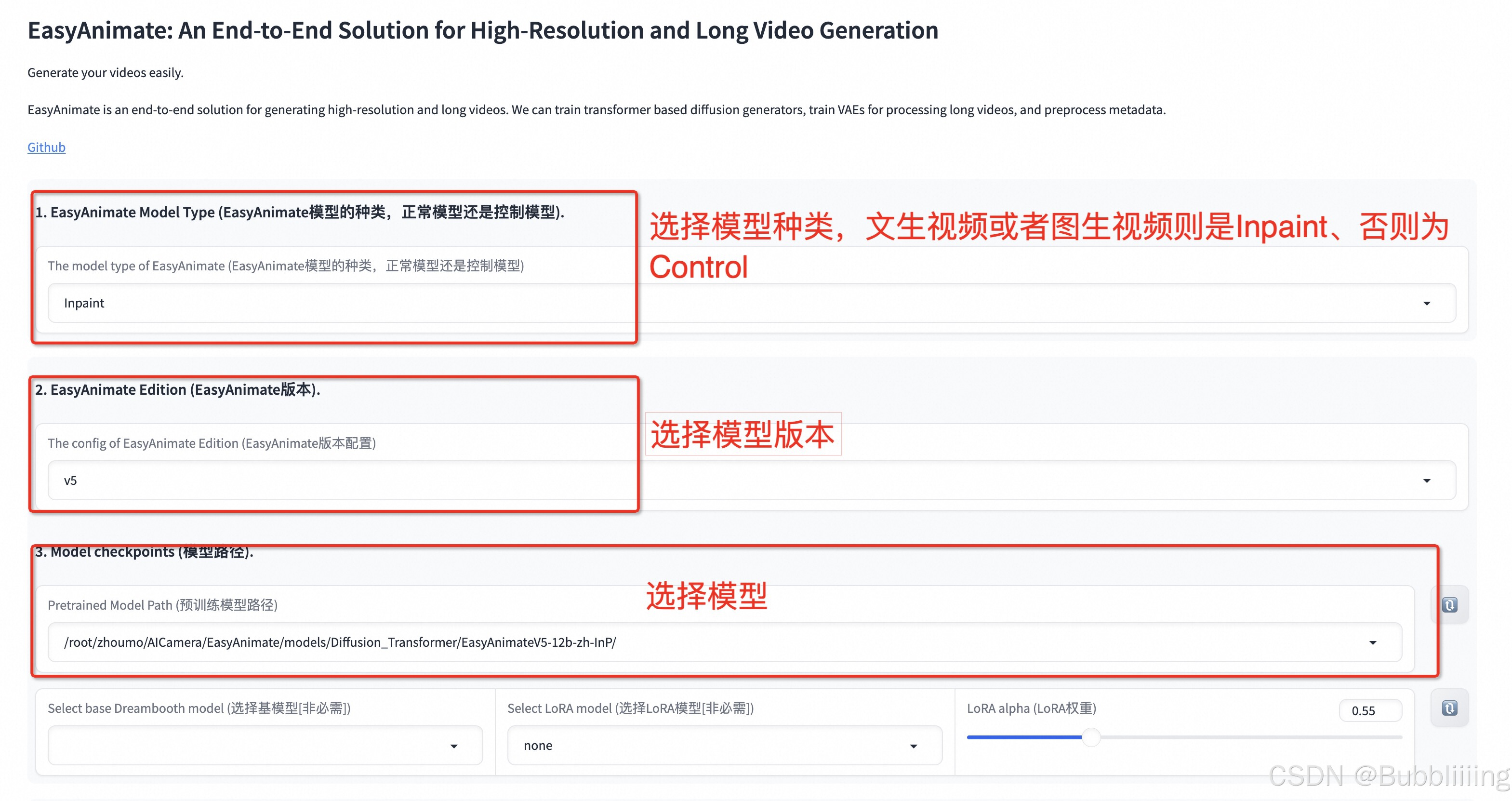
cd EasyAnimate文生视频
在 Gradio 界面中选择预训练模型并填写提示词,即可生成视频。界面提供了调整视频分辨率和帧数的选项,方便用户根据需求调整生成结果。
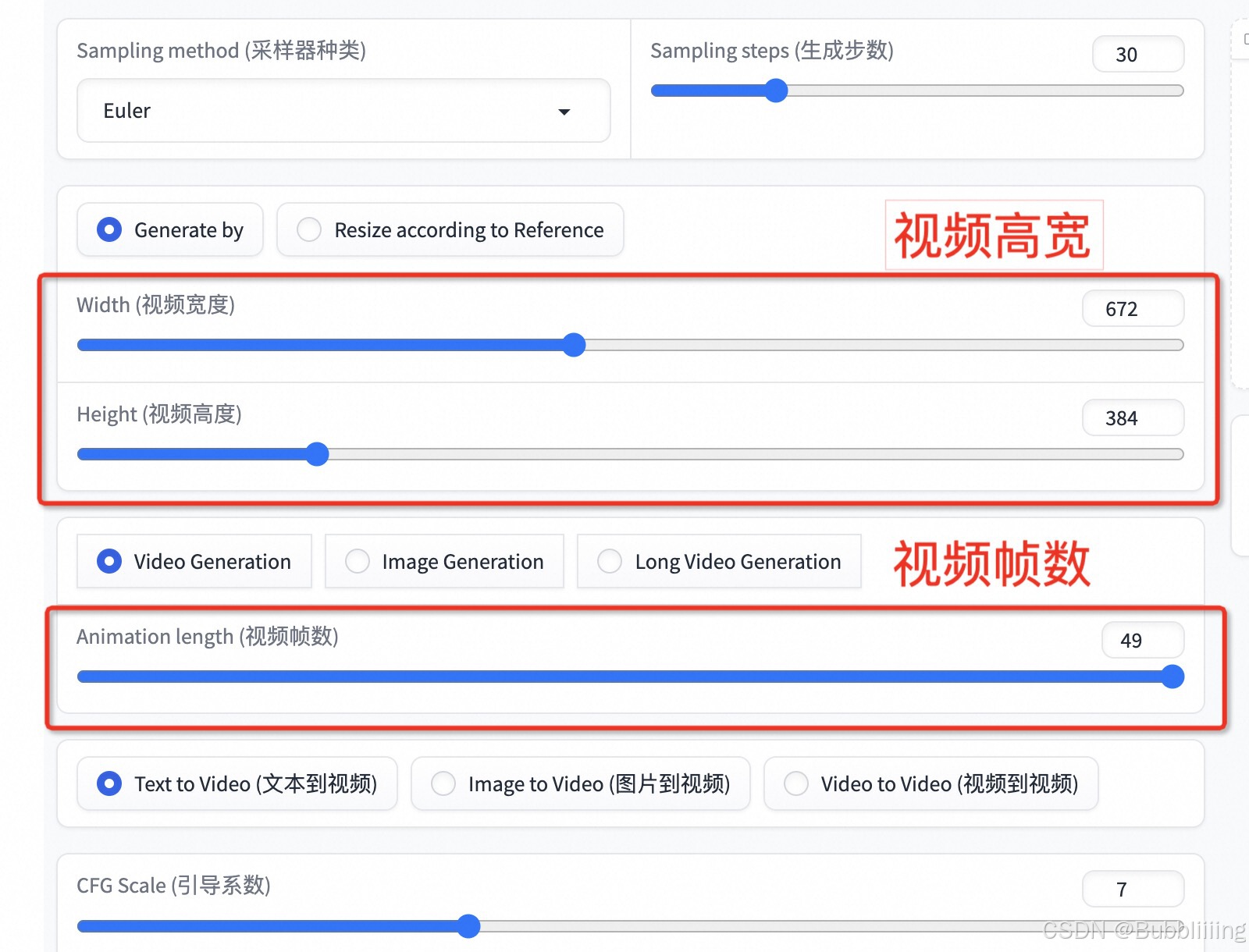
图生视频
图生视频生成需要指定参考图,并根据图像的分辨率进行调整。界面中提供了自动调整按钮,方便用户快速设置。
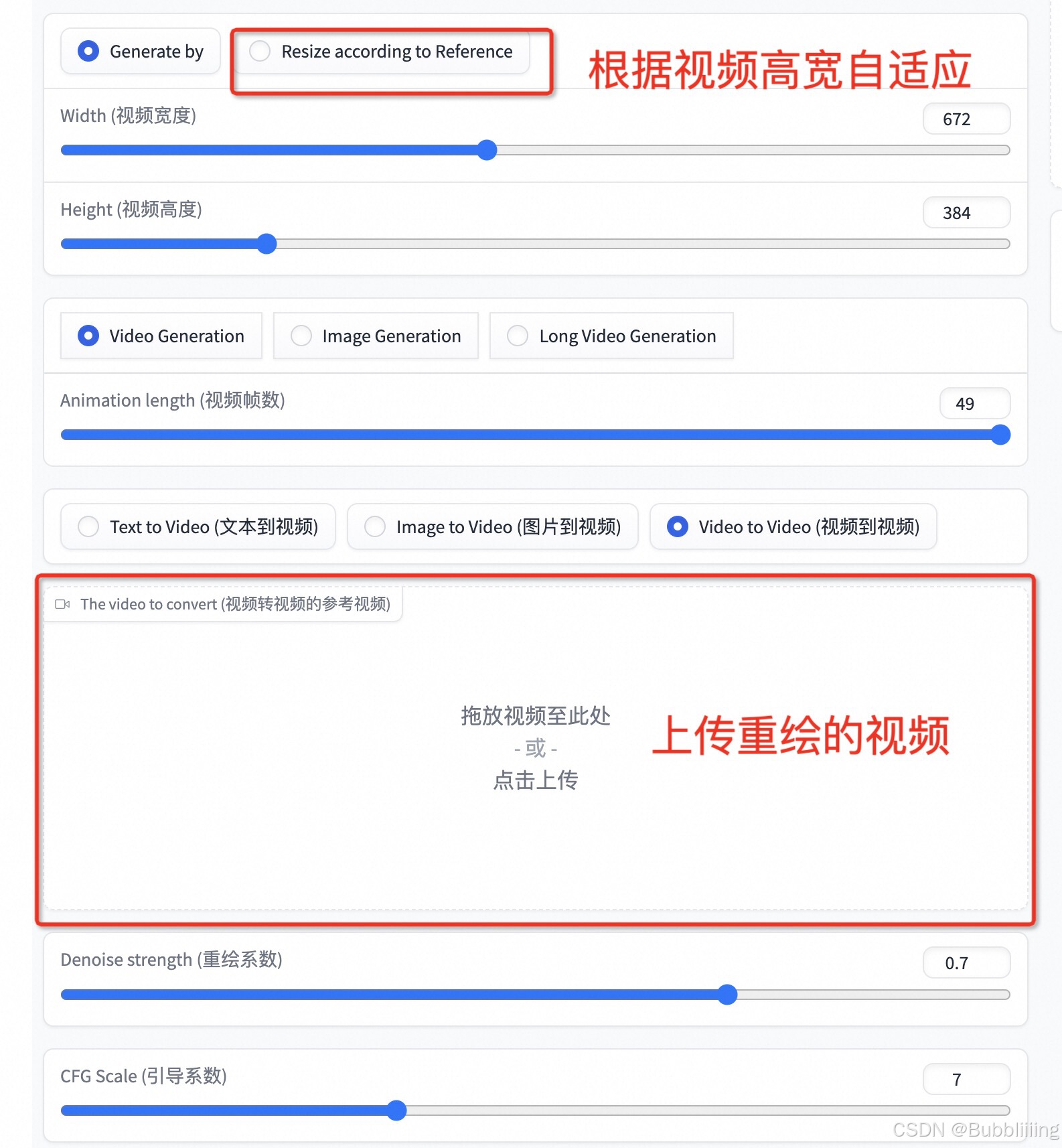
视频生视频
视频生视频允许用户通过指定参考视频生成相似风格的视频。用户可以根据参考视频的分辨率进行调整,确保生成效果的一致性。
控制生视频
控制生视频提供了更多的自定义选项,用户可以通过控制信号调整生成结果,提升视频的个性化和多样性。
FAQ
常见问题
-
问:EasyAnimate 的主要应用场景有哪些?
- 答:EasyAnimate 主要应用于视频生成、影视制作、广告设计等领域,帮助用户快速生成高质量的视频内容。
-
问:如何提高生成视频的质量?
- 答:可以通过调整输入文本描述的详细程度、选择合适的模型和参数设置来提高视频生成质量。
-
问:EasyAnimate 是否支持自定义模型训练?
- 答:是的,EasyAnimate 支持用户根据自己的需求进行自定义模型训练,包括基础模型和 Lora 模型的训练。
-
问:生成视频的格式和分辨率有哪些?
- 答:EasyAnimate 支持多种格式和分辨率的视频生成,用户可以根据需要调整设置。
-
问:如何在本地安装和使用 EasyAnimate?
- 答:用户可以通过下载源码和模型权重,在本地配置环境后运行 EasyAnimate,具体步骤可参考项目的 GitHub 页面。