揭秘DeepSeek R1 核心算法GRPO的奥秘
文章目录
DeepSeek简介
DeepSeek是一种旨在优化深度学习模型性能的创新算法。其设计初衷是通过对模型的深度学习过程进行精细化调整,提升模型的学习效率和推理能力。DeepSeek的诞生标志着AI领域在解决大规模数据处理和复杂任务推理上的又一次突破。如今,Hugging Face等社区正在积极推动DeepSeek的开源进程,让更多的开发者能够接触并利用这一先进技术。
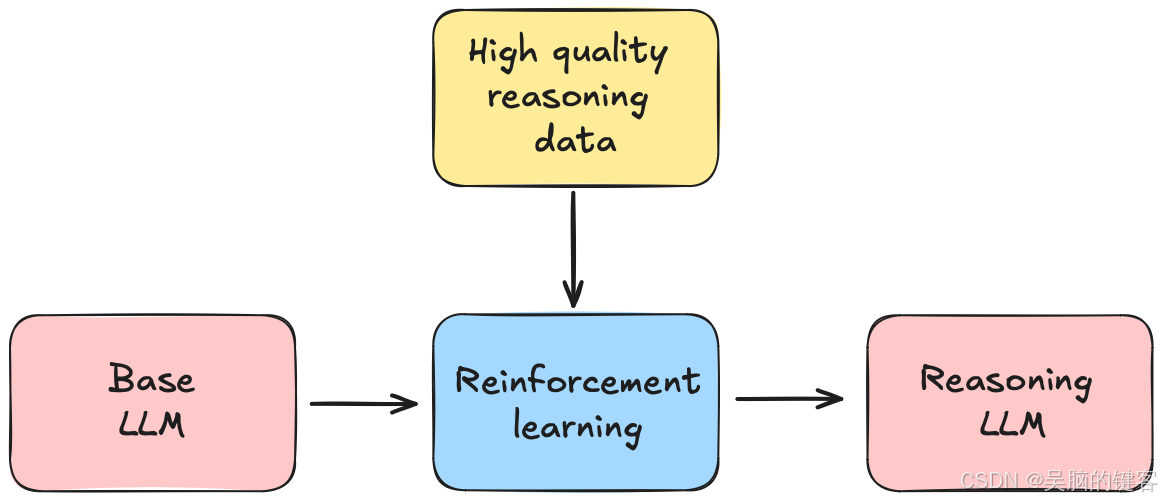
DeepSeek的核心算法:GRPO
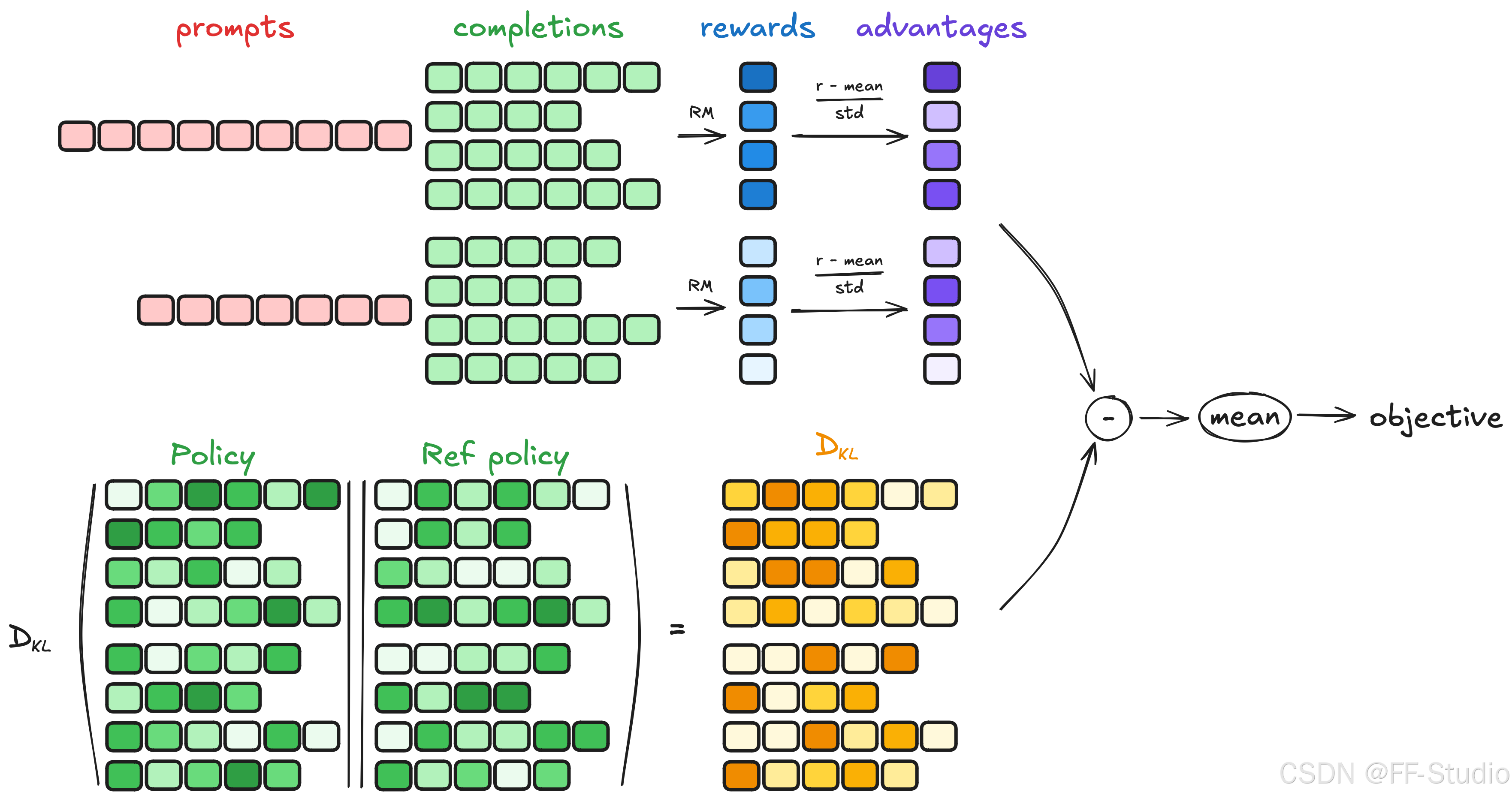
GRPO(Gradient-based Reward Policy Optimization)是一种专门为强化学习设计的在线学习算法,旨在提高模型在复杂推理任务中的表现。它通过分阶段的反馈机制,不断优化模型的策略。
GRPO的四个步骤
- 生成补全:模型通过自身生成的数据进行自我训练。
- 计算优势:评估生成的响应相对于群体的表现。
- 估计KL散度:确保模型的输出不会偏离参考策略。
- 计算损失:根据偏差调整模型的参数。
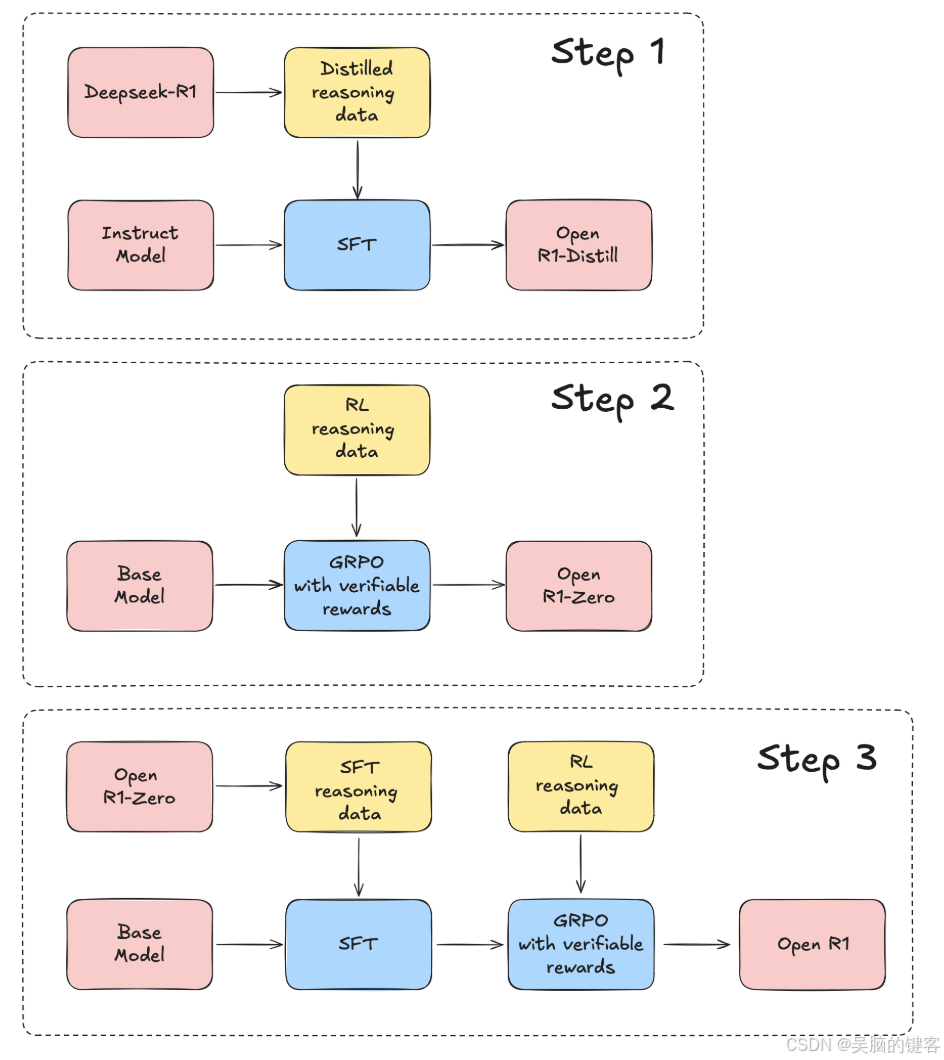
Open R1项目的愿景
Hugging Face宣布的Open R1项目旨在填补DeepSeek未开源组件的空白。通过开源数据集和代码,Open R1为全球开发者提供了复制和构建DeepSeek模型的机会。
项目目标与步骤
- 提炼推理数据集:从DeepSeek-R1中提取高质量数据。
- 复制强化学习管道:创建用于推理的RL管道。
- 多阶段训练验证:从基础模型到RL的完整训练流程。

GRPO算法的实现细节
在Open R1中,GRPO算法的实现是通过配置文件和脚本的结合来完成的。
配置文件解析
配置文件confg_full.yaml中定义了模型参数和训练设置,包括模型路径、数据集名称和训练器参数等。
model_name_or_path: deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
model_revision: main
torch_dtype: bfloat16
dataset_name: AI-MO/NuminaMath-TIR
num_processes: 7脚本执行流程
使用accelerate工具执行GRPO训练脚本,通过配置文件指定相关参数,实现模型的训练和评估。
ACCELERATE_LOG_LEVEL=info accelerate launch --config_file recipes/accelerate_configs/zero3.yaml --num_processes=7 src/open_r1/grpo.py --config recipes/qwen/Qwen2.5-1.5B-Instruct/grpo/confg_full.yamlDeepSeek在Duckdb-Extension中的应用
DeepSeek不仅限于AI模型训练,其灵活性和高效性使得它在数据库扩展中也获得了应用。
Duckdb-Extension源码分析
Duckdb-Extension是一个为DuckDB数据库系统开发的扩展模块,利用DeepSeek的推理能力来处理复杂的查询操作。
头文件
头文件quack_extension.hpp定义了扩展类,继承自DuckDB的核心类。
class QuackExtension : public Extension {
public:
void Load(DuckDB &db) override;
std::string Name() override;
std::string Version() const override;
};源文件
源文件中实现了具体的扩展功能,如字符串处理函数和函数注册。
inline void QuackScalarFun(DataChunk &args, ExpressionState &state, Vector &result) {
UnaryExecutor::Execute(
name_vector, result, args.size(), [&](string_t name) {
return StringVector::AddString(result, "Quack " + name.GetString() + " 🐥");
}
);
}DeepSeek的未来发展
随着开源社区的推动,DeepSeek有望在更多领域发挥其潜力。从数据处理到AI推理,DeepSeek正在成为一种通用的解决方案。
未来的研究方向
- 多领域应用:扩展至科学研究、工程设计等领域。
- 优化算法性能:进一步提高模型的推理速度和精度。
结论
DeepSeek作为一种新兴的AI推理模型,正在通过开源和社区合作不断发展。其核心算法GRPO的应用不仅限于学术研究,还在实际工程中展现出巨大的价值。未来,随着更多数据和技术的融入,DeepSeek将继续引领AI领域的创新。
FAQ
-
问:DeepSeek的核心算法是什么?
- 答:DeepSeek的核心算法是GRPO,它是一种基于梯度的奖励策略优化算法,旨在提高模型的推理能力。
-
问:Open R1项目的目标是什么?
- 答:Open R1项目的目标是填补DeepSeek未开源部分的空白,通过开源数据集和代码,让更多开发者能够复制和使用DeepSeek模型。
-
问:如何在Duckdb中应用DeepSeek技术?
- 答:通过开发Duckdb-Extension扩展模块,可以利用DeepSeek的推理能力来优化数据库查询和数据处理过程。
-
问:DeepSeek未来的发展方向是什么?
- 答:未来DeepSeek将拓展到更多领域,提升算法性能,并在科学研究、工程设计等领域发挥更大的作用。
-
问:如何获取DeepSeek的源码和文档?
- 答:可以通过访问Hugging Face的GitHub仓库获取DeepSeek的源码和相关文档,了解更多实现细节。