对比学习Loss在自监督学习中的应用与优化
自监督学习作为深度学习领域的一个重要分支,近年来得到了广泛的关注和研究。其中,对比学习Loss(Contrastive Learning Loss)作为一种有效的自监督学习方法,被广泛应用于特征学习、图像识别、自然语言处理等多个领域。本文将深入探讨对比学习Loss的原理、实现及其在自监督学习中的应用与优化。
对比学习Loss的原理
对比学习Loss的核心思想是通过拉近相似样本的特征表示,推开不相似样本的特征表示,从而学习到区分不同样本的特征空间。这种方法不需要外部的标签信息,而是通过样本之间的相似性来引导学习过程。
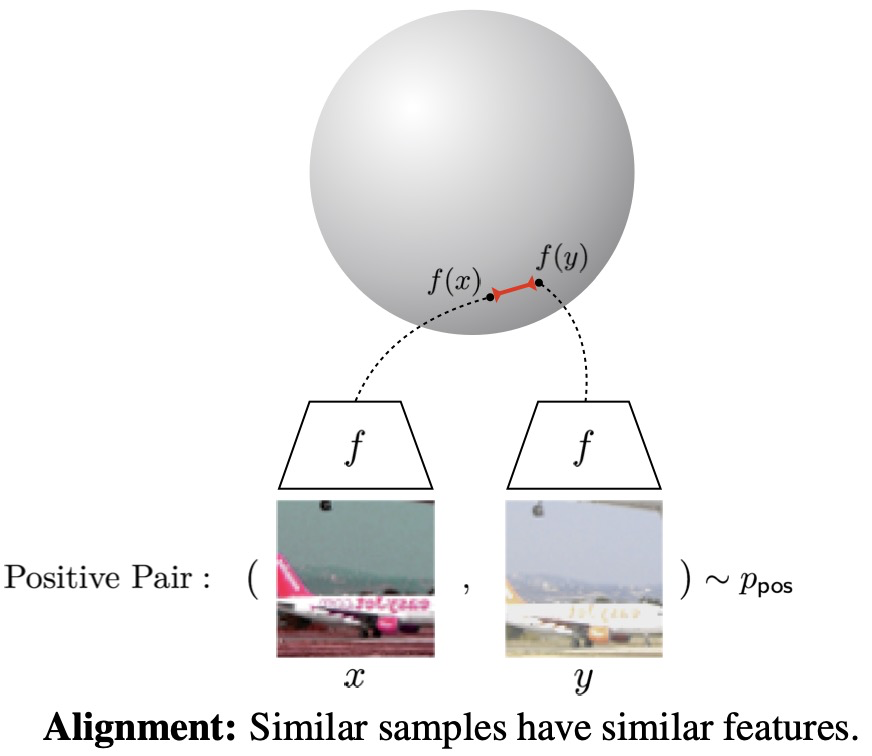
1.1 Alignment和Uniformity
Alignment和Uniformity是评估对比学习Loss性能的两个重要标准。Alignment指的是相似样本的特征应该尽可能接近,而Uniformity则要求不相似样本的特征应该均匀分布在特征空间中。这两个标准共同确保了学习到的特征具有良好的区分性和泛化能力。
1.2 InfoNCE Loss
InfoNCE Loss是对比学习Loss中常用的一种损失函数,它通过最大化正样本之间的相似度,并最小化负样本之间的相似度,从而实现特征空间的优化。InfoNCE Loss的计算公式如下:
L = -frac{1}{N}sum_{i=1}^N log frac{exp(sim(z_i, z_{i+})/tau)}{exp(sim(z_i, z_{i+})/tau) + sum_{j=1}^K exp(sim(z_i, z_{i-j})/tau)}其中,sim(x, y)表示样本x和y之间的相似度,τ是温度参数,用于控制损失函数的形状。
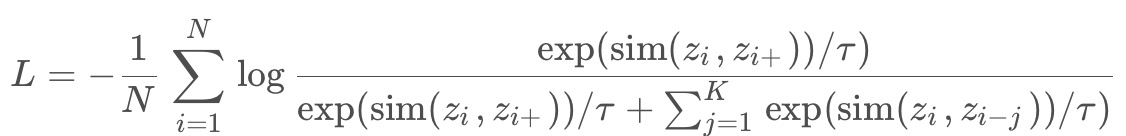
对比学习Loss在自监督学习中的应用
对比学习Loss在自监督学习中的应用非常广泛,尤其是在图像识别和自然语言处理领域。通过对比学习Loss,可以有效地学习到样本的特征表示,为后续的分类、聚类等任务提供有力的特征支持。
2.1 图像识别中的应用
在图像识别任务中,对比学习Loss可以用来学习图像的特征表示。通过拉近同一类别图像的特征表示,推开不同类别图像的特征表示,可以提高模型对图像的识别能力。
2.2 自然语言处理中的应用
在自然语言处理领域,对比学习Loss同样可以用于学习文本的特征表示。通过对比学习Loss,可以有效地捕捉到文本之间的语义关系,为文本分类、情感分析等任务提供重要的特征支持。
对比学习Loss的优化策略
为了进一步提升对比学习Loss的效果,可以采取一些优化策略,如负样本采样、温度参数的调整等。
3.1 负样本采样
负样本采样是对比学习Loss中常用的一种优化策略。通过合理选择负样本,可以有效地提高模型的区分能力。一般来说,负样本选取的越多,模型的效果就越好。
3.2 温度参数的调整
温度参数τ是对比学习Loss中的一个重要超参数,它控制了损失函数的平滑程度。通过调整τ的值,可以平衡模型对正样本和负样本的关注程度,从而优化模型的性能。
3.3 其他优化策略
除了负样本采样和温度参数的调整,还可以通过数据增强、正则化等方法进一步优化对比学习Loss。通过这些优化策略的综合运用,可以显著提高对比学习Loss的效果。
FAQ
- 问:对比学习Loss和传统监督学习有什么区别?
- 答:对比学习Loss是一种自监督学习方法,它不需要外部的标签信息,而是通过样本之间的相似性来引导学习过程。而传统监督学习需要大量的标签数据来指导模型的学习。
- 问:对比学习Loss在实际应用中的效果如何?
- 答:对比学习Loss在图像识别、自然语言处理等多个领域都有广泛的应用,并且取得了很好的效果。通过对比学习Loss,可以有效地学习到样本的特征表示,为后续的任务提供有力的特征支持。
- 问:如何选择合适的温度参数τ?
- 答:温度参数τ的选择需要根据具体的任务和数据进行调整。一般来说,可以通过交叉验证等方法来选择最佳的τ值。τ值过大或过小都会影响模型的性能,因此需要仔细调整。
- 问:对比学习Loss有哪些优化策略?
- 答:对比学习Loss的优化策略包括负样本采样、温度参数的调整、数据增强、正则化等。通过这些优化策略的综合运用,可以显著提高对比学习Loss的效果。
- 问:对比学习Loss在特征学习中的作用是什么?
- 答:对比学习Loss在特征学习中的作用是通过拉近相似样本的特征表示,推开不相似样本的特征表示,从而学习到区分不同样本的特征空间。这为后续的分类、聚类等任务提供了重要的特征支持。