5 大最佳开源语音识别引擎与api
作者:API传播员 · 2025-05-26 · 阅读时间:5分钟
在语音识别技术快速发展的今天,开源语音识别引擎和 API 为开发者提供了灵活且高效的解决方案。本文将深入分析五大最佳开源语音识别引擎及其特点,帮助您选择最适合的工具。
1. Mozilla DeepSpeech
优点
- 预训练模型:提供了经过预训练的英语模型,用户无需额外数据即可直接使用。同时支持迁移学习,用户可以基于自己的数据微调模型。
- 高度定制化:DeepSpeech是一个代号解决方案,而非API,允许用户根据需求进行调整,提供极高的灵活性。
- **Python、Java、JavaScript、C 和 .NET 框架。此外,DeepSpeech 可编译至 Raspberry Pi,适合嵌入式应用开发。
缺点
- 开发支持减少:由于 Mozilla 的战略调整,DeepSpeech 的开发已逐步减少,未来的支持可能会受到限制。
- 集成复杂:DeepSpeech 仅以 Git 仓库形式提供,用户需自行开发 API 和相关工具来实现与模型的接口。
2. Wav2Letter++
优点
- 创新架构:作为第一个完全基于卷积层的语音识别系统,Wav2Letter++ 不依赖循环层,展现了高效的语言建模能力。
- 性能优化:基于 C++ 编写,支持 CPU 和 GPU 的快速计算,且包含 Flashlight 机器学习库,提供灵活的模型训练和优化选项。
- 研究支持:提供多种研究配方,用户可根据需求调整模型组件,适配不同应用场景。
缺点
- 复杂性高:需要开发者具备深厚的编程和基础设施知识,才能有效部署和使用。
3. Kaldi
优点
- 经典模型支持:专注于传统语音识别方法(如 HMM、FST 和高斯混合模型),适合不依赖深度学习的项目。
- 轻量便携:代码经过多年优化,运行高效且可靠。
- 社区支持:拥有活跃的论坛、邮件列表和 GitHub 问题跟踪器,提供良好的技术支持。
- 多平台兼容:支持编译至 Android 等设备,扩展性强。
缺点
- 准确性限制:由于不以深度学习为核心,Kaldi 的识别精度可能不及现代深度学习模型。
4. Open Seq2Seq
优点
- 多模型支持:支持 Jasper DR 10×5、百度 DeepSpeech2 和 Facebook Wav2Letter++ 等多种语音识别模型。
- 高性能功能:支持多 GPU 分布式训练、混合精度训练等,适合高计算需求的场景。
- 低错误率:Jasper DR 10×5 的单词错误率仅为 3.61%。
缺点
- 开发停止:项目已在 GitHub 上标记为存档,意味着不再维护,用户需自行解决潜在问题。
5. TensorFlow ASR
TensorFlow 提供了多种语音识别模型,包括 DeepSpeech2、Conformer Transducer、Context Net 和 Jasper。这些模型支持使用 TFLite 部署,并可与现有 TensorFlow 系统无缝集成。此外,还提供了多种语言的预训练模型,如越南语和德语。
开源与付费服务的对比
尽管开源语音识别引擎提供了灵活的选择,但其复杂性也不可忽视。开发者需要投入大量时间和资源来微调模型、编写接口 API 并维护系统运行。而像 Rev AI 这样的付费服务则提供了更便捷的解决方案:
- 高可用性:通过 API 提供 99.9% 的正常运行时间,确保系统稳定。
- 技术支持:直接访问开发团队和客户支持,快速解决问题。
- 准确性领先:在多项基准测试中,Rev 的系统表现优异,单词错误率始终最低。
- 快速部署:无需开发团队或复杂配置,简单 API 调用即可快速上线。
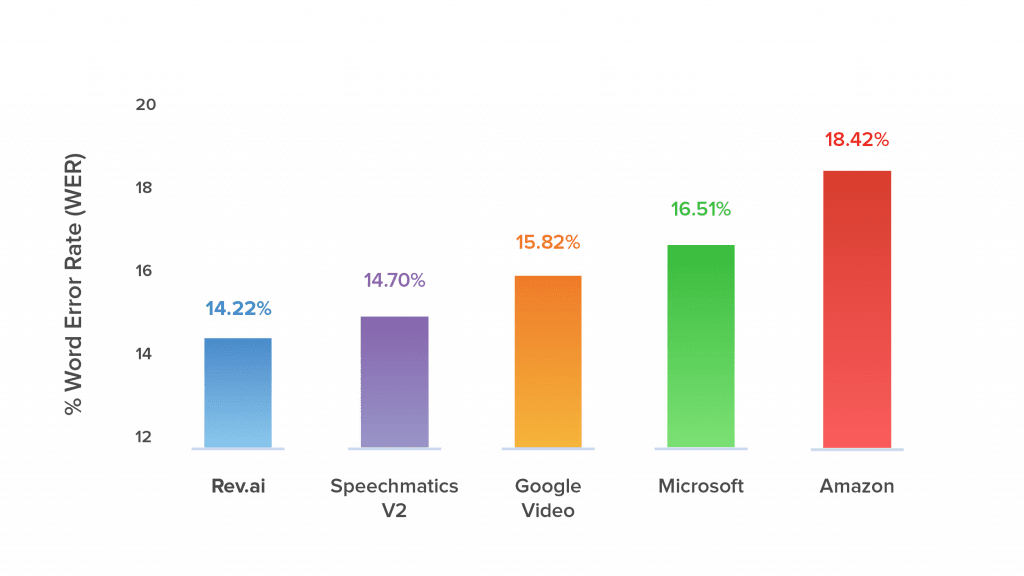
付费服务虽然需要一定成本,但在节省时间和资源的同时,也能提供更高的稳定性和准确性。
原文链接: https://www.rev.com/resources/the-5-best-open-source-speech-recognition-engines-apis热门推荐
一个账号试用1000+ API
助力AI无缝链接物理世界 · 无需多次注册
3000+提示词助力AI大模型
和专业工程师共享工作效率翻倍的秘密