四款AI大模型API价格对比:DeepSeek R1、ChatGPT o3-mini、Grok3、通义千问 Max
作者:zhilong · 2025-06-02 · 阅读时间:7分钟
面对众多API价格对比(含隐藏成本提示) – 28项参数实测数据与性能排名 – 不同需求下的选型建议(企业/个人开发者)
Deepseek ### 1.服务商优势 • 全天候在线客服支持:提供24小时在线服务。 • 强劲市场表现:月活跃用户达73.2M。 ## xAI
### 1.服务商优势 • 全天候在线客服支持:提供24小时在线服务。 • 强劲市场表现:月活跃用户达73.2M。 ## xAI ### 1.服务商优势 • 强劲的市场表现:印度流量占比31.5%。 • 客服支持有待提升:电话联系渠道有限。 ## OpenAI
### 1.服务商优势 • 强劲的市场表现:印度流量占比31.5%。 • 客服支持有待提升:电话联系渠道有限。 ## OpenAI ### 1.服务商优势 • SEM评分100分,市场排名第112。 • 全天候客户服务支持:提供在线客服和电话支持。 • 美国流量份额12.85%,市场表现良好。 • 网站流量462M,全球覆盖广泛。 ## 通义千问
### 1.服务商优势 • SEM评分100分,市场排名第112。 • 全天候客户服务支持:提供在线客服和电话支持。 • 美国流量份额12.85%,市场表现良好。 • 网站流量462M,全球覆盖广泛。 ## 通义千问 ### 1.服务商优势 • 市场表现良好:网站流量月访问量达12.6M。 • 全球市场覆盖:主要市场为中国,占比88.4%。
### 1.服务商优势 • 市场表现良好:网站流量月访问量达12.6M。 • 全球市场覆盖:主要市场为中国,占比88.4%。
以上仅列举了这几家服务商的部分优势数据。若想获取更多关于网站流量、排名及权重的完整详细信息。请点此查看报表详情👇

DeepSeek R1DeepSeek-R1 在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版 ### Grok-3Grok-3 是 xAI 开发的先进 AI 模型,具有卓越的逻辑推理和语言生成能力。它支持 131072 tokens 的超长上下文窗口,能处理复杂任务。其推理速度快,成本低,适合多种应用场景,如数学解题、代码生成和文本创作。Grok-3 还引入人类反馈机制,使输出更精准,是高效智能的 AI 选择。 ### o3 miniOpenAI 的 O3 Mini 模型是一款轻量级的 AI 模型,专为高效处理简单任务而设计。它具备快速的推理能力和较低的计算成本,适合处理短文本生成、基础问答和逻辑推理等任务。O3 Mini 支持多语言交互,能够灵活应用于多种场景。其优化的架构使其在资源受限的环境中表现出色,是入门级用户和轻量级应用的理想选择。 ### 通义千问 Max通义千问-Max,即Qwen2.5-Max,是阿里云通义千问旗舰版模型,于2025年1月29日正式发布。该模型预训练数据超过20万亿tokens,在多项公开主流模型评测基准上录得高分,位列全球第七名,是非推理类的中国大模型冠军。它展现出极强劲的综合性能,特别是在数学和编程等单项能力上排名第一。 了解服务商的整体实力只是第一步,真正影响使用体验的,是API本身的性价比与性能表现。接下来,我们将通过实际数据,回答开发者最关心的两个问题: – 1️⃣ "哪款模型的API价格更划算?" – 2️⃣ "在真实场景中,谁的响应速度和处理能力更强?" 对比重点: – 四款模型(DeepSeek R1/Grok-3/o3 mini/通义千问 Max)的价格方案对比 – 在文本生成、代码推理等任务中的性能实测结果 ## AI大模型多维度对比分析 ### 1.API模型价格对比 | API模型名称 | 免费试用额度 | 输入价格(缓存命中) | 输入价格(缓存未命中) | 输出价格 | |:———–|:—————–:|:———-:|:—————:|:—————-:| | DeepSeek R1 | N/A | ¥0.001/千Tokens (¥1.00/1M Tokens) | ¥0.004/千Tokens (¥4.00/1M Tokens) | ¥0.016/千Tokens (¥16.00/1M Tokens) | | Grok-3 | 注册后赠送25美元的免费额度 | ¥0.003/千tokens (¥3.00/1M Tokens) | ¥0.003/千tokens (¥3.00/1M Tokens) | ¥0.015/千tokens (¥15.00/1M Tokens) | | o3 mini | 新用户提供 $5 的试用额度 | ¥0.00055/千tokens (¥0.55/1M Tokens) | ¥0.0011/千tokens (¥1.10/1M Tokens) | ¥0.0044/千tokens (¥4.40/1M Tokens) | | 通义千问 Max | 赠送100万Tokens额度
有效期:百炼开通后180天内 | ¥0.0024/千tokens (¥2.40/1M Tokens) | ¥0.0024/千tokens (¥2.40/1M Tokens) | ¥0.0096/千tokens (¥9.60/1M Tokens) | DeepSeek R1以价格灵活为优势,适合大数据处理;Grok-3提供免费额度且输入输出价格统一,适合稳定预算的开发者;o3 mini价格最低,适合个人或小型项目;通义千问 Max赠送大量Tokens,适合试用广泛功能。整体来看,各模型在成本和功能上各有特色,用户可根据预算和功能需求选择适合的AI模型。
2.性能基准测试对比 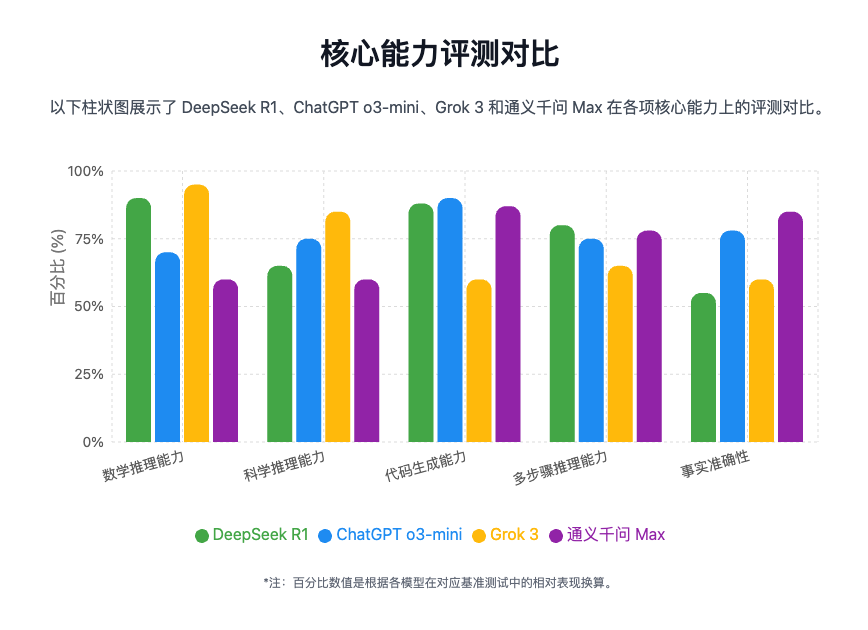 #### 数学推理能力 – DeepSeek R1 – 在GSM8K(小学数学)和MATH-500(高阶数学)测试中分别取得77.23分和97.3分,表现优于通义千问Max(92分)。 – 采用MoE架构优化计算效率,擅长代数计算和符号推理。 – Grok-3 – AIME 2025评测中得分93%,数学竞赛类题目表现最佳,超越DeepSeek R1(80%+)。 – 但基础算术稳定性较弱,长上下文数学问题解析受限。 – o3 mini – GSM8K准确率约70%,适合基础数学任务,复杂问题表现一般。 – 通义千问 Max – MATH-500得分92分,数学单项能力排名国内第一,但低于DeepSeek R1。 #### 科学推理能力 – DeepSeek R1 – MMLU(本科水平知识)得分90.8,与通义千问Max持平,但在物理建模和实验模拟中更优。 – Grok-3 – AGI Eval科学子集跨学科得分比Claude 3.7高5%,生物学和地球科学领域优势明显。 – o3 mini – 科学知识库丰富,适合科研辅助,但实验模拟能力较弱。 – 通义千问 Max – 在医疗问答(如PubMedQA)等文本解析任务中表现稳定,多模态科学理解稍逊。 #### 代码生成能力 – DeepSeek R1 – HumanEval编程测试得分96.3%,略优于通义千问Max(96%),支持长代码生成(32K上下文)。 – Grok-3 – 代码可读性优但逻辑易错(如Rubik’s Cube求解器颜色混乱),SWE Bench通过率较低。 – o3 mini – HumanEval表现优异,专为代码补全优化,适合Python/JavaScript开发。 – 通义千问 Max – 编程能力全球排名第七,但复杂项目生成稳定性不足。 #### 多步骤推理能力 – DeepSeek R1 – AGI Eval多跳问答答案连贯性高,可自动修正中间推理错误,法律/医学案例分析能力强。 – Grok-3 – 128K上下文窗口支持超长文本推理,但多步骤逻辑易断裂。 – o3 mini – 多轮对话优化最佳,适合企业知识管理,但动态数学模拟能力有限。 – 通义千问 Max – 32K上下文窗口限制多公式推导,长文本推理得分低于DeepSeek R1。 #### 事实准确性 – DeepSeek R1 – 知识截至2024年底,联网搜索功能可补充实时信息,第三方平台测试稳定性高。 – Grok-3 – 整合Twitter/X实时数据,但社交数据可能引入噪声。 – o3 mini – 依赖预训练数据(截至2024年中),无联网搜索能力。 – 通义千问 Max – 中文事实准确性高,但多模态生成可能产生幻觉。 #### 综合测试表现 – 总榜排名: – o3 mini(high)以76.01分居首,DeepSeek R1(70.34分)国内第一,领先通义千问Max(66.38分)。 – 性价比: – DeepSeek R1和通义千问Max成本效益最优,Grok-3因高性能定价较高。 – 开源优势: – DeepSeek R1支持私有化部署,适合边缘计算;o3 mini和Grok-3仅限云端。 ## 总结 上面重点对比了4家服务商的API,若要查看其他2025国内AI大模型对比情况包括xAI,Deepseek,OpenAI,通义千问等主流供应商。请点此查看完整报告或可以自己选择期望的服务商制作比较报告
#### 数学推理能力 – DeepSeek R1 – 在GSM8K(小学数学)和MATH-500(高阶数学)测试中分别取得77.23分和97.3分,表现优于通义千问Max(92分)。 – 采用MoE架构优化计算效率,擅长代数计算和符号推理。 – Grok-3 – AIME 2025评测中得分93%,数学竞赛类题目表现最佳,超越DeepSeek R1(80%+)。 – 但基础算术稳定性较弱,长上下文数学问题解析受限。 – o3 mini – GSM8K准确率约70%,适合基础数学任务,复杂问题表现一般。 – 通义千问 Max – MATH-500得分92分,数学单项能力排名国内第一,但低于DeepSeek R1。 #### 科学推理能力 – DeepSeek R1 – MMLU(本科水平知识)得分90.8,与通义千问Max持平,但在物理建模和实验模拟中更优。 – Grok-3 – AGI Eval科学子集跨学科得分比Claude 3.7高5%,生物学和地球科学领域优势明显。 – o3 mini – 科学知识库丰富,适合科研辅助,但实验模拟能力较弱。 – 通义千问 Max – 在医疗问答(如PubMedQA)等文本解析任务中表现稳定,多模态科学理解稍逊。 #### 代码生成能力 – DeepSeek R1 – HumanEval编程测试得分96.3%,略优于通义千问Max(96%),支持长代码生成(32K上下文)。 – Grok-3 – 代码可读性优但逻辑易错(如Rubik’s Cube求解器颜色混乱),SWE Bench通过率较低。 – o3 mini – HumanEval表现优异,专为代码补全优化,适合Python/JavaScript开发。 – 通义千问 Max – 编程能力全球排名第七,但复杂项目生成稳定性不足。 #### 多步骤推理能力 – DeepSeek R1 – AGI Eval多跳问答答案连贯性高,可自动修正中间推理错误,法律/医学案例分析能力强。 – Grok-3 – 128K上下文窗口支持超长文本推理,但多步骤逻辑易断裂。 – o3 mini – 多轮对话优化最佳,适合企业知识管理,但动态数学模拟能力有限。 – 通义千问 Max – 32K上下文窗口限制多公式推导,长文本推理得分低于DeepSeek R1。 #### 事实准确性 – DeepSeek R1 – 知识截至2024年底,联网搜索功能可补充实时信息,第三方平台测试稳定性高。 – Grok-3 – 整合Twitter/X实时数据,但社交数据可能引入噪声。 – o3 mini – 依赖预训练数据(截至2024年中),无联网搜索能力。 – 通义千问 Max – 中文事实准确性高,但多模态生成可能产生幻觉。 #### 综合测试表现 – 总榜排名: – o3 mini(high)以76.01分居首,DeepSeek R1(70.34分)国内第一,领先通义千问Max(66.38分)。 – 性价比: – DeepSeek R1和通义千问Max成本效益最优,Grok-3因高性能定价较高。 – 开源优势: – DeepSeek R1支持私有化部署,适合边缘计算;o3 mini和Grok-3仅限云端。 ## 总结 上面重点对比了4家服务商的API,若要查看其他2025国内AI大模型对比情况包括xAI,Deepseek,OpenAI,通义千问等主流供应商。请点此查看完整报告或可以自己选择期望的服务商制作比较报告
热门推荐
一个账号试用1000+ API
助力AI无缝链接物理世界 · 无需多次注册
3000+提示词助力AI大模型
和专业工程师共享工作效率翻倍的秘密
热门推荐
一个账号试用1000+ API
助力AI无缝链接物理世界 · 无需多次注册