OpenAI GPT-4o 图像生成 (gpt-image-1) API - IMG.LY
简介
多模态的交互式工作流。过去,图像生成API通常采用简单的提示-输出模式,尽管实用但缺乏灵活性。而“gpt-image 1”通过GPT-4o多模态基础模型构建,支持在画布内完成提示、调整和细化等操作,为开发者提供了设计创新工具的新可能性。
本指南将全面介绍“gpt-image 1”API的功能及其在用户中心化产品中的应用潜力。我们不仅探讨如何生成图像,还将深入分析如何将该模型整合到创作周期中,使AI成为用户意图的延伸,而非单纯的工具。
gpt-image 1 概述
“gpt-image 1”于2025年4月发布,是OpenAI最新的图像生成模型,专为应用程序内的视觉创作设计。它基于GPT-4o的多模态架构,支持更高分辨率的图像生成和更复杂的交互式工作流。
模型架构与功能
“gpt-image 1”利用GPT-4o的跨模态理解能力,可根据自然语言提示生成高达4096×4096像素的高分辨率图像。相比以往版本,该模型在处理复杂场景和详细描述时表现更为出色,特别适合需要高可靠性的设计工具。
参数控制
开发者可通过以下关键参数控制图像生成:
- prompt:描述图像内容的主要文本输入。
- 大小:支持“1024×1024”、“1024×1536”(纵向)、“1536×1024”(横向)或“自动”(默认,基于提示)。
- n:生成图像的数量(默认值为1)。
- response_format:始终返回
b64_json格式,不支持URL输出。
与DALL·E 3不同,“gpt-image 1”不支持“样式”或“质量”修饰符,而是专注于通过文本提示和尺寸选择实现高保真图像生成。
风格与应用场景
“gpt-image 1”支持多种风格模板,适用于从营销宣传品到故事板工具等多种场景。无论是技术插图、概念艺术还是照片级真实感渲染,开发者都能根据品牌或产品需求调整输出。
局限性与未来方向
截至2025年4月,“gpt-image 1”每次请求仅支持生成一张图像,且不具备精细编辑或修复功能。然而,与GPT-4o的深度集成为未来功能(如持久上下文、会话细化以及图像与文本的交互)奠定了基础。
API 设置与使用
获取访问权限
开发者需在 OpenAI 平台 注册并申请API访问权限。访问需通过API密钥,该密钥与账户的计费层级相关。确保账户已获准使用图像生成功能,具体可用性可能因地区和订阅级别而异。
图像生成示例(Node.js)
以下是使用Node.js生成图像的示例代码:
const { OpenAI } = require("openai");
const fs = require("fs");
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY, // 确保安全存储
});async function generateImage() {
try {
const prompt = "一个赛博朋克女孩用手指抓蝴蝶的吉卜力工作室风格的插图。";
const result = await openai.images.generate({
model: "gpt-image 1",
prompt,
size: "1024x1024", // 可选 "1024x1536", "1536x1024" 或 "auto"
}); const imageBase64 = result.data[0].b64_json;
const imageBytes = Buffer.from(imageBase64, "base64");
fs.writeFileSync("butterfly.png", imageBytes);
console.log("图像已保存为 butterfly.png");
} catch (err) {
console.error("生成图像时出错:", err);
}
}generateImage();注意:所有输出均为Base64编码的JSON格式,需解码后才能显示或存储。
在创意编辑工作流中的集成
嵌入式图像生成
通过CreativeEditor SDK(CE SDK),“gpt-image 1”可内容生成图像。例如,用户可以通过提示“在日落时创建一个充满活力的节日场景”生成图像,并直接在画布上编辑。
上下文内编辑
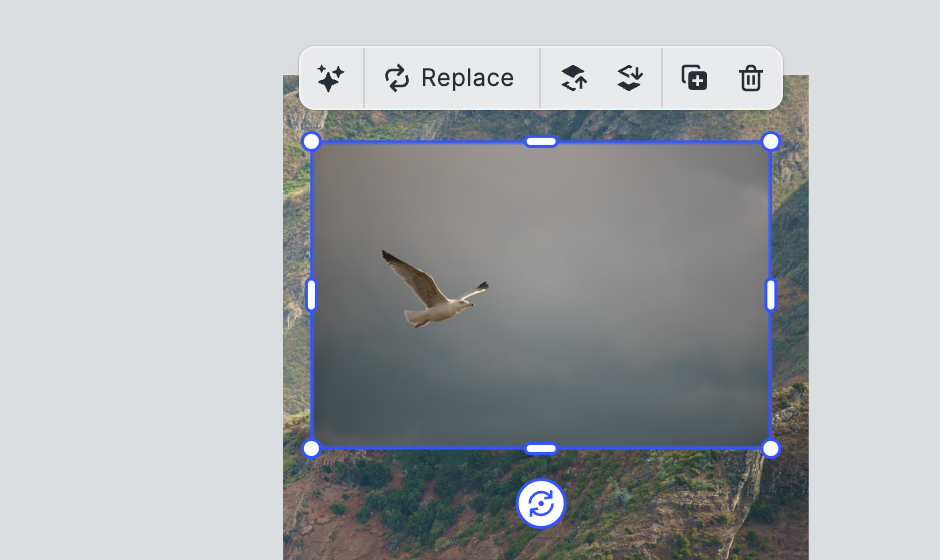
“gpt-image 1”在上下文内编辑中展现了强大潜力。用户可基于现有内容(如背景或产品图像)触发AI增强。例如,选择一只鸟的图像后,可以生成变体、替换背景或添加更多元素。
以下是一个示例场景:
- 用户定位一只鸟的图像,并通过API生成更多鸟类的变体。
- 生成的图像可进一步编辑、叠加滤镜或调整纹理。
工程提示
提示设计是成功生成高质量图像的关键。以下是一些优化提示的建议:
明确视觉意图
在提示中清晰表达图像的目的。例如,“夜晚的城市天际线”可以进一步细化为“从屋顶酒吧看到的夜景,有发光的霓虹灯和轻微的雾霾”。
利用艺术语言
通过引用艺术风格或媒介(如“水彩风格”、“80年代动漫美学”)优化输出,使其更符合特定品牌或产品需求。
保持品牌一致性
生成一组相关图像时,使用一致的提示结构和品牌元素(如调色板或图案)确保输出风格统一。
现实世界用例
“gpt-image 1”在多个行业中具有广泛应用潜力:
网络打印
用户可通过简单的关键词或主题选择生成个性化的营销材料、活动邀请或包装设计。
数字资产管理(DAM)
DAM系统可利用“gpt-image 1”动态扩展资产库,生成替代背景或本地化内容。
电子商务与电子学习
通过生成高质量的产品图像或教育内容,提升用户体验。
成本优化
图像生成通常伴随较高的API成本,以下是一些优化策略:
平衡分辨率与成本
为预览选择较低分辨率(如1024×1024),仅在最终输出时使用高分辨率设置。
图像重用与智能放大
通过动态裁剪或编辑高质量主图像,减少重复生成的需求。
批处理与速率限制
将多个提示合并为批量请求,或先生成低分辨率草稿以优化成本。
常见问题
gpt-image 1 与 DALL·E 3 的区别?
“gpt-image 1”基于GPT-4o多模态框架,支持更高分辨率和更广泛的样式,适合动态用户体验,而DALL·E 3更侧重于一次性生成任务。
是否支持离线使用?
目前,“gpt-image 1”仅支持通过OpenAI云API访问,不提供离线推理模式。
版权与许可?
根据OpenAI政策,生成的图像可用于商业用途,但开发者需确保符合品牌和内容标准。
结论
“gpt-image 1”不仅是一个图像生成工具,更是构建交互式设计工作流的基础。通过与CreativeEditor SDK结合,开发者可以为用户提供更强大的创意工具,推动多模态创意领域的潜力。
原文链接: https://img.ly/blog/openai-gpt-4o-image-generation-api-gpt-image-1-a-complete-guide-for-creative-workflows-for-2025/