基于LLM驱动的文本到图像提示生成与Milvus - Zilliz
背景故事
自从接触到第一个开源图像生成 AI 系统以来,我便被其从文本中生成视觉吸引力图像的潜力深深吸引。这项技术不仅让用户能够更专注于创意表达,还显著提升了提示生成的效率和质量。然而,我也发现,自己在快速独立生成高质量提示方面仍面临挑战。
为了改进这一过程,我开始在互联网上搜集优秀的图像及其生成提示,并尝试通过这些提示创建自己的图像。尽管这一方法帮助我提升了提示质量,但耗时较长,效率不高。于是,我决定寻找一种更高效的方式来生成提示。
最终,我下载了数百万条提示,并将它们存储在 Milvus 矢量数据库中。通过构建一个系统,用户可以通过简单的输入提示,从数据库中获取相似的提示结果。测试结果表明,这些提示生成的图像质量显著优于传统方法。一位用户甚至将负面提示与系统生成的提示结合,成功生成了符合预期的高质量图像。即使不使用负面提示,系统也能生成令人满意的图像。
以下是两张使用相同种子和负面提示生成的图像对比:


可以看到,左图在构图和姿态上更加稳定,而右图在质量、姿态和背景上都存在漂移。
系统构建与优化
为了实现这一系统,我编写了脚本,从多个来源获取并清理提示数据。起初,我尝试使用 pgvector 作为矢量数据库,但其性能不尽如人意。经过多次测试和优化,我最终选择了 Milvus。与 pgvector 相比,在几乎相同的代码基础上,Milvus 的运行速度提升了五倍。
当数据成功加载到 Milvus 矢量数据库后,我开始使用 LLM(大语言模型)生成高质量的提示。然而,初期的尝试并不顺利,因为 LLM 的上下文和输入不匹配。经过多次调整,我发现需要为 LLM 提供明确的指令,并加入一些示例对话历史,才能让其生成理想的提示。
更重要的是,这一系统可以在本地机器上运行,得益于 Milvus 的高效向量搜索能力。整个过程中,主要延迟来自嵌入模型和 LLM 的运行,而矢量搜索的速度非常快,GPU 几乎没有停顿。
以下是整个系统流程的示意图:
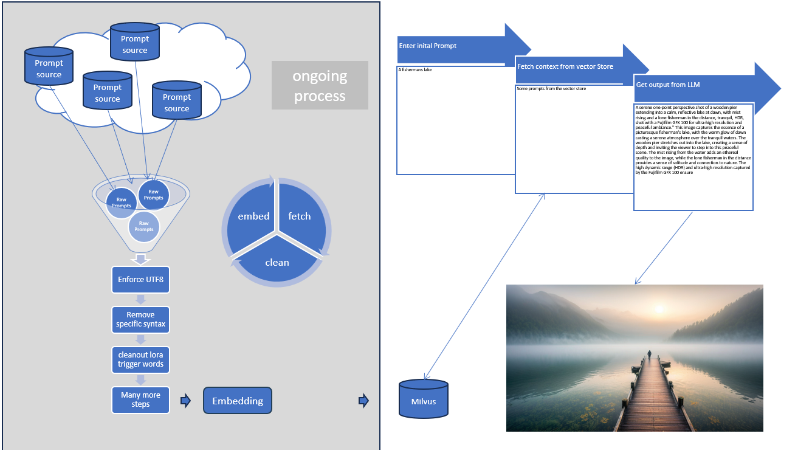
系统优势与未来展望
通过构建 Prompt Quill 系统,我能够在更短的时间内生成大量高质量提示。与手工制作的提示相比,系统生成的提示更强大,尤其是在处理特殊模型时表现尤为突出。尽管负面提示可以进一步增强图像质量,但系统生成的提示在没有负面提示的情况下,依然能达到较高的水准。
未来,我计划为系统添加负面提示生成功能。负面提示在图像生成过程中具有重要作用,通过与现有提示生成流程结合,可以进一步优化图像质量。此外,我还计划通过对比系统生成的提示与负面提示,进一步提升提示的多样性和适用性。
以下是系统生成的一些提示示例:
- 示例 1:…
- 示例 2:…
总结
基于 LLM 和 Milvus 的文本到图像提示生成系统,不仅提高了提示生成的效率,还显著提升了图像生成的质量。通过优化提示生成流程和引入负面提示功能,该系统为创作者提供了更强大的工具,帮助他们更轻松地实现创意表达。在未来,随着系统功能的不断完善,它将为更多用户带来便利和灵感。
原文链接: https://zilliz.com/blog/llm-powered-text-to-image-prompt-generation-with-milvus