ChatGPT 内存项目解析:Redis 向量数据库在 LLM 上下文管理中的应用
ChatGPT内存响应AI(人工智能)应用程序中使用的大型语言模型(LLM)中的上下文长度限制。ChatGPT包使用Redis(NoSQL数据库)作为向量数据库来缓存每个会话的历史用户交互,这提供了基于当前上下文的自适应提示创建机制。
为什么上下文长度很重要
ChatGPT自推出以来,其强大的对话能力和智能化表现吸引了全球关注。然而,尽管GPT-3.5和GPT-4等大型语言模型(LLM)在生成类似人类的对话方面表现出色,但它们在技术上仍存在一些局限性,其中一个关键问题就是上下文长度的限制。
上下文长度指的是模型在对话中能够记住和处理的历史信息量。以GPT-4为例,其上下文长度从4096个令牌提升到了32768个令牌。然而,随着上下文长度的增加,使用API的成本也会随之上升。开发者在构建基于LLM的应用时,必须在处理更长文档和控制成本之间找到平衡。
此外,简单的内存管理方法可能无法应对复杂的对话场景。例如,当用户在对话中切换主题后又返回原主题时,传统方法可能无法提供相关的历史上下文。这种局限性主要源于令牌溢出问题,即历史交互超出了模型输入限制,导致无法被纳入当前对话。
ChatGPT内存项目的解决方案
为了解决上述问题,ChatGPT内存项目引入了一种基于Redis的自适应聊天机器人的历史交互存储为嵌入式向量,系统能够在嵌入空间中执行向量搜索,从而智能地检索与当前消息相关的历史记录。这种方法具有以下优势:
- 自适应性强:只检索与当前消息相关的历史记录,避免了不必要的信息冗余。
- 优化上下文利用:通过合并最相关的历史交互,提升提示质量,同时避免令牌长度耗尽。
- 成本效益高:减少不必要的令牌使用,从而降低API调用成本。
这种自适应内存机制不仅克服了传统启发式缓冲内存的限制,还为开发者提供了构建高效、智能对话系统的可能性。
ChatGPT内存项目的架构
ChatGPT内存项目的核心架构基于Redis向量数据库,利用了以下技术:
- 向量索引算法:支持FLAT索引和分层导航小世界(HNSW)索引,确保高效的向量搜索。
- 实时嵌入CRUD操作:支持嵌入的创建、更新和删除,方便在生产环境中动态管理数据。
- 并发会话管理:为每个会话隔离历史记录,确保用户交互的独立性和隐私性。
具体流程如下:
- 用户发送消息后,系统会将消息与历史记录进行嵌入化处理。
- 嵌入向量存储在Redis数据库中,并通过向量搜索检索相关历史记录。
- 系统将检索到的历史信息与当前消息合并,生成优化的提示,最终返回给用户。
这种架构不仅提升了对话的个性化程度,还显著增强了系统的响应能力。
代码演练
以下是使用ChatGPT内存项目的基本步骤:
环境变量配置
首先,设置以下环境变量:
# OpenAI API密钥
EXPORT OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
# Redis数据库凭据
EXPORT REDIS_HOST=localhost
EXPORT REDIS_PORT=1234
EXPORT REDIS_PASSWORD=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx创建Redis数据存储连接
from chatgpt_memory.datastore import RedisDataStoreConfig, RedisDataStore
redis_datastore_config = RedisDataStoreConfig(
host=REDIS_HOST,
port=REDIS_PORT,
password=REDIS_PASSWORD,
)
redis_datastore = RedisDataStore(config=redis_datastore_config)实例化嵌入客户端
from chatgpt_memory.llm_client import EmbeddingConfig, EmbeddingClient
embedding_config = EmbeddingConfig(api_key=OPENAI_API_KEY)
embed_client = EmbeddingClient(config=embedding_config)创建内存管理器
from chatgpt_memory.memory.manager import MemoryManager
memory_manager = MemoryManager(
datastore=redis_datastore,
embed_client=embed_client,
topk=1
)连接ChatGPT API
from chatgpt_memory.llm_client import ChatGPTClient, ChatGPTConfig
chat_gpt_client = ChatGPTClient(
config=ChatGPTConfig(api_key=OPENAI_API_KEY, verbose=True),
memory_manager=memory_manager
)开始交互
conversation_id = None
while True:
user_message = input("n请输入您的消息: ")
response = chat_gpt_client.converse(
message=user_message,
conversation_id=conversation_id
)
conversation_id = response.conversation_id
print(response.chat_gpt_answer)交互示例
未启用ChatGPT内存
当内存功能未激活时,模型无法检索用户在之前交互中提供的信息,即使这些信息仅涉及几句话。
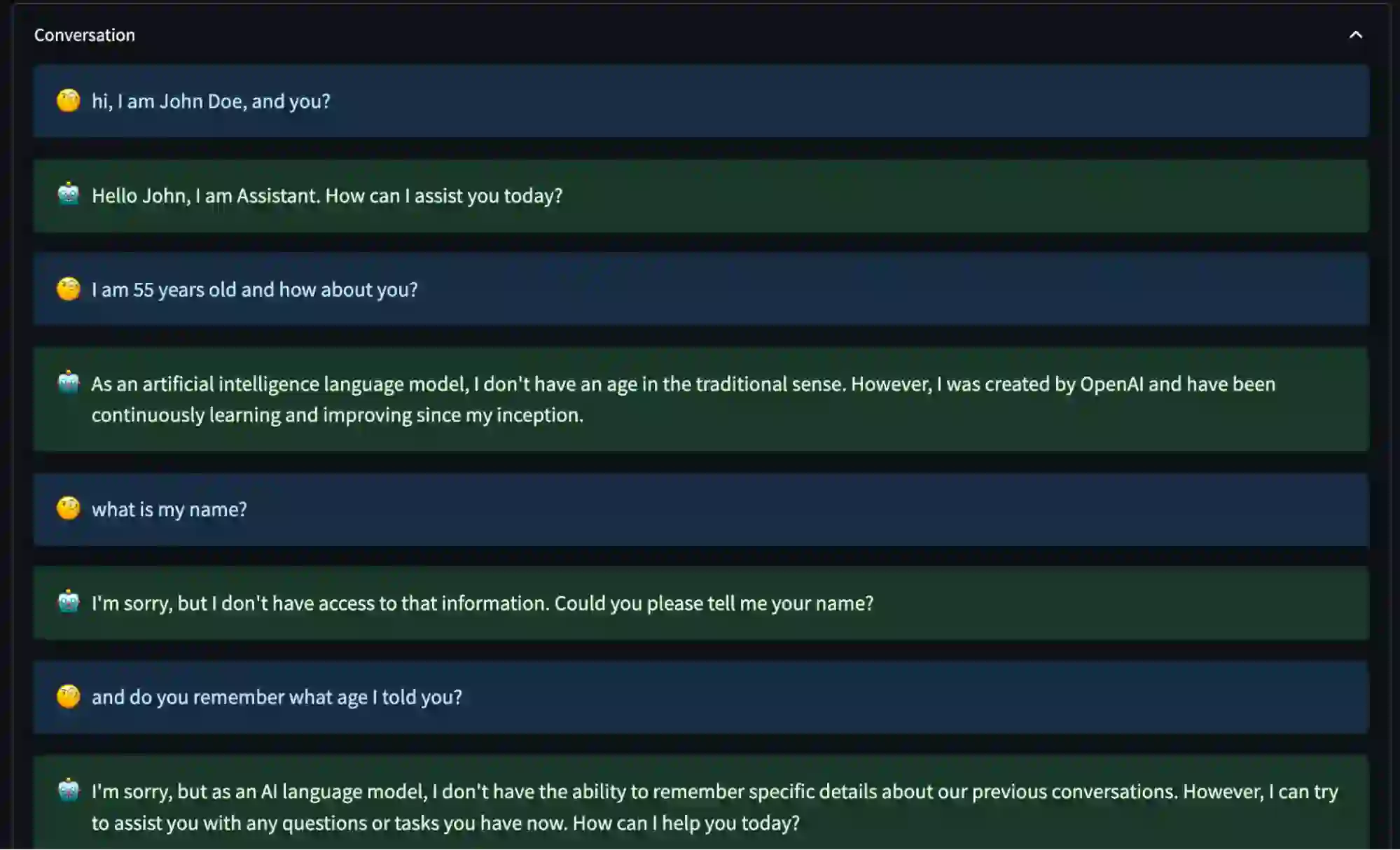
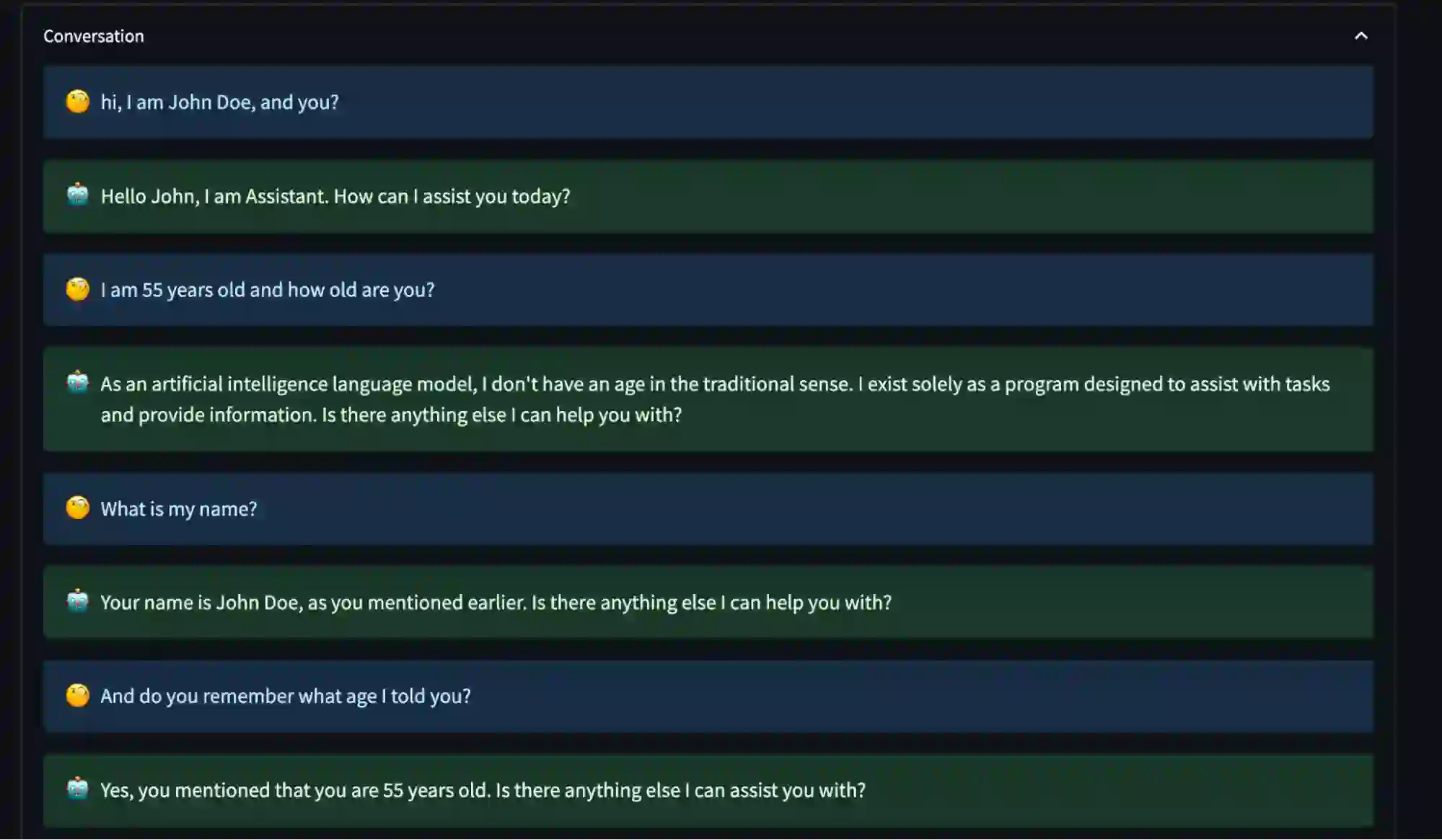
启用ChatGPT内存
启用内存功能后,模型能够记住用户的具体细节,从而提供更加个性化的对话体验。
下一步
ChatGPT内存项目是提升LLM功能的重要工具,为开发者提供了构建情境智能AI应用的全新可能性。通过Redis向量数据库的支持,该项目不仅解决了上下文长度限制问题,还为多种AI用例提供了高效的解决方案。
未来,ChatGPT内存有望成为AI开发生态系统中的关键组件,推动更智能、更高效的对话系统的发展。
原文链接: https://redis.io/blog/chatgpt-memory-project/