RAG搜索增强:理论与实践
本篇文章深入探讨了RAG(生成式AI的幻觉倾向和专业力弱等缺陷。文章详细介绍了RAG的基础与高级技术,包括数据分块、矢量化、搜索索引、查询路由等核心步骤,以及如何在应用中实现这些技术。
检索增强生成技术简介
检索增强生成(RAG)是一种结合大语言模型(LLM)与外部知识源的技术,旨在提高生成内容的准确性和可靠性。通过使用检索算法从外部数据源获取相关信息,RAG 为 LLM 提供上下文支持,从而改善生成的精确性。
RAG 的基本概念
RAG 是通过将检索到的信息融入到生成过程中的一种方式,使得大语言模型能够以更贴合上下文的方式回答问题。这种方法在处理最新或专有信息时尤为重要。
RAG 的重要性
RAG 技术的出现解决了 LLM 在面对新信息或特定领域知识时可能产生的“幻觉”问题,通过引入外部知识来弥补 LLM 的不足。
应用领域
RAG 在问答服务、内容生成、客户支持等多个领域有广泛应用,尤其是在需要实时信息更新的场景中展现出其优势。

基础检索增强生成技术
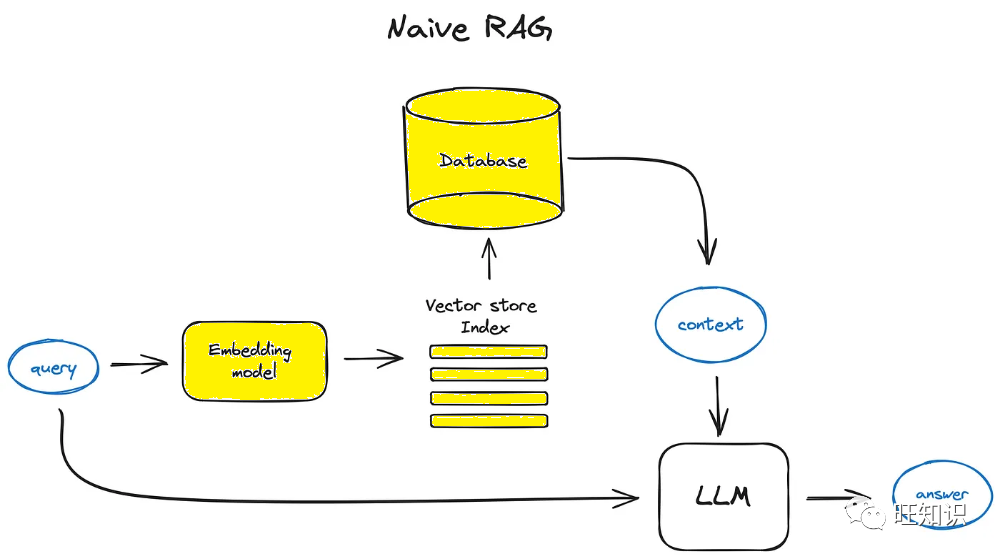
基础 RAG 技术包括检索上下文相关信息和结合生成过程两个阶段。通过将用户查询转换为向量进行匹配,RAG 能够从数据库中检索最相关的信息。
检索过程
在检索阶段,用户的查询被转化为向量形式,以便在向量数据库中进行匹配。这一步骤确保了检索到的信息与用户的需求高度相关。
增强过程
在增强阶段,检索来的信息与原始查询一起被嵌入到提示中,这种合成的提示能够提高生成的准确性。
生成过程
最终,增强的提示被输入到大语言模型中,以生成精确的回答,从而实现信息的有效传递。
高级检索增强生成技术
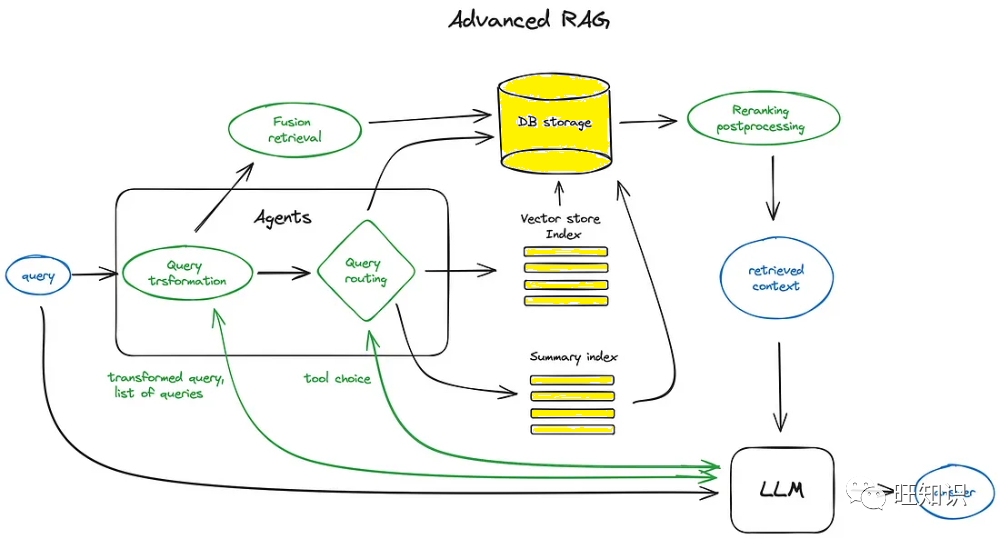
高级 RAG 技术在基础流程之上,增加了复杂的算法和优化步骤,以进一步提高信息检索和生成的质量。
分块和矢量化
分块是将文本分割成小块,以便嵌入到向量中进行处理。矢量化则是将文本块转化为向量,以便进行相似性搜索。
搜索索引和层次索引
搜索索引用于高效存储和检索向量化的内容,层次索引则通过分层次的方式提高检索效率,适用于大规模文档集。
查询转换和路由
查询转换涉及对用户输入进行修改,以提高检索质量。路由则是根据查询内容,决定使用哪个索引或数据源进行检索。
分块和矢量化
分块策略
分块是将文档分割成小块的过程,确保每个块都有足够的上下文以便于后续的矢量化和检索。
矢量化过程
矢量化是将文本块转化为向量的过程,使用预训练的嵌入模型来捕捉文本的语义信息,以便于后续的相似性搜索。
矢量数据库
矢量数据库用于存储和管理矢量化后的文本块,支持高效的相似性搜索和检索。
搜索索引和层次索引
向量存储索引
向量存储索引用于存储矢量化的文本块,通过近似最近邻算法实现高效检索。
层次索引
层次索引通过将文档分成多个层次来提高检索效率,适用于需要从大量文档中快速检索信息的场景。
假设问题和 HyDE
假设问题是为每个文本块生成可能的查询,以提高检索效率。HyDE 是一种逆向逻辑的方法,通过生成假设响应来增强检索。
查询转换和路由
查询转换
查询转换是使用大语言模型对用户输入进行修改,以提高检索质量和生成的准确性。
路由策略
路由策略决定了用户查询应该发送到哪个索引或数据源进行处理,以确保检索的效率和准确性。
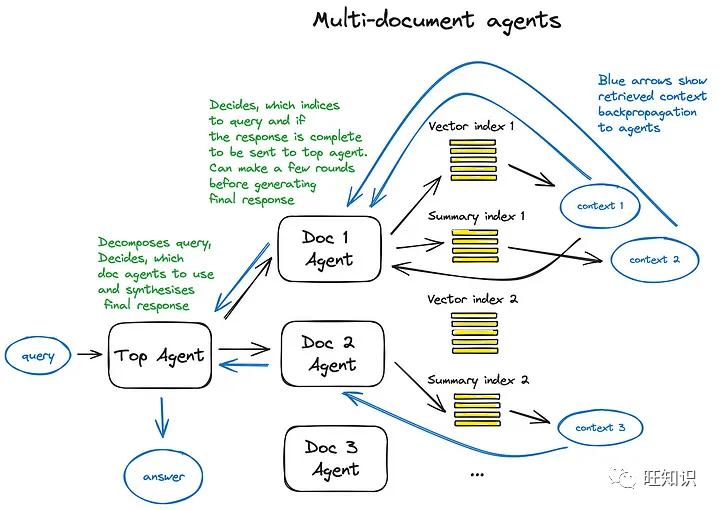
多文档检索
多文档检索涉及在多个文档中查找相关信息,并将其综合成一个完整的回答。
RAG 中的 Agent 和响应合成
Agent 的作用
在 RAG 中,Agent 负责执行复杂的逻辑操作,通过调用一系列工具和函数来完成指定任务。
响应合成
响应合成是根据检索到的上下文生成最终答案的过程,确保回答的准确性和相关性。
系统微调
微调涉及对编码器、排序器和大语言模型进行优化,以提高整个 RAG 系统的性能和生成质量。
FAQ
问:什么是检索增强生成(RAG)技术?
- 答:检索增强生成(RAG)是一种结合大语言模型(LLM)与外部知识源的技术,旨在提高生成内容的准确性和可靠性。通过使用检索算法从外部数据源获取相关信息,RAG 为 LLM 提供上下文支持,从而改善生成的精确性。
问:RAG 技术的基本流程是什么?
- 答:RAG 技术包括三个主要阶段:检索、增强和生成。在检索阶段,用户的查询被转化为向量形式,以便在向量数据库中进行匹配。在增强阶段,检索来的信息与原始查询一起被嵌入到提示中。最终,增强的提示被输入到大语言模型中,以生成精确的回答。
问:RAG 技术在哪些领域有应用?
- 答:RAG 技术在问答服务、内容生成、客户支持等多个领域有广泛应用,尤其是在需要实时信息更新的场景中展现出其优势。
问:高级 RAG 技术如何提高信息检索和生成的质量?
- 答:高级 RAG 技术通过增加复杂的算法和优化步骤来进一步提高信息检索和生成的质量。例如,分块和矢量化可以将文本分割并转化为向量,搜索索引和层次索引提高了检索效率,查询转换和路由策略优化了查询处理。
问:什么是分块和矢量化在 RAG 中的作用?
- 答:分块是将文档分割成小块的过程,确保每个块有足够的上下文以便于后续的矢量化和检索。矢量化是将文本块转化为向量的过程,以便进行相似性搜索。通过这些步骤,RAG 系统能够更高效地检索和处理信息。