R语言相关性分析及可视化详解
作者:zhilong · 2025-01-26 · 阅读时间:3分钟
本文详细介绍了在数据分析中,如何使用R语言进行相关性分析及可视化。相关性分析有助于理解变量间关系强度和方向。文章首先介绍了相关系数的类型,包括皮尔森、斯皮尔曼和肯德尔相关系数,以及相关性强度的判断标准。接着,展示了在R语言中进行相关性分析的方法,包括数据准备、使用Hmisc包的rcorr()函数计算相关系数和显著性水平。最后,介绍了如何使用corrplot包可视化相关系数矩阵,帮助直观理解变量间关系。
R语言相关性分析及可视化详解
在数据分析领域,尤其是生物信息学和金融分析中,相关性分析是一个非常重要的步骤。它可以帮助我们了解变量之间的关系强度及方向。本文将详细介绍如何使用R语言进行相关性分析以及如何将分析结果进行可视化展示。
一、相关性分析基础
相关性分析是一种统计方法,用于衡量两个或多个变量之间的相互关系程度。在进行相关性分析前,了解不同相关系数的定义和用途是至关重要的。
1.1 相关系数的类型
- 皮尔森相关系数(Pearson):衡量两个变量之间线性关系的强度和方向。值的范围从-1到+1,其中1表示完全正相关,-1表示完全负相关,0表示没有线性相关。
- 斯皮尔曼相关系数(Spearman):一种非参数的相关系数,用于衡量两个变量的等级顺序之间的相关性,不要求数据服从正态分布。
- 肯德尔相关系数(Kendall):也是一种非参数的相关系数,用于衡量两个变量的序之间的相关性。
1.2 相关性强度判断标准
- 极弱或无相关(0.0-0.2)
- 弱相关(0.2-0.4)
- 中等程度相关(0.4-0.6)
- 强相关(0.6-0.8)
- 极强相关(0.8-1.0)
二、R语言中的相关性分析
R语言提供了多种包和函数来进行相关性分析,下面我们将介绍几个常用的包和它们的功能。
2.1 数据准备与加载
在进行相关性分析之前,我们需要准备数据集。以下是一个简单的示例,展示如何在R中加载和查看数据集的前几行。
data(mtcars)
# 加载数据集
mydata <- mtcars[, c(1,3,4,5,6,7)]
head(mydata, 6)# 查看数据前6行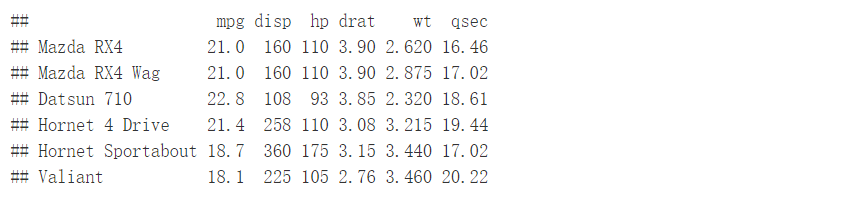
2.2 Hmisc包的rcorr()函数
Hmisc包中的rcorr()函数可以同时计算相关系数和显著性水平p-value。这个函数非常适用于大数据集的相关性分析。
library(Hmisc)
# 加载包
res2 <- rcorr(as.matrix(mydata))
res2
三、可视化相关系数矩阵
对相关系数矩阵的可视化可以帮助我们直观地理解变量之间的关系。corrplot包提供了多种方式来展示相关性矩阵。
3.1 使用corrplot()函数
library(corrplot)# 加载包
corrplot(res, type =热门推荐
一个账号试用1000+ API
助力AI无缝链接物理世界 · 无需多次注册
3000+提示词助力AI大模型
和专业工程师共享工作效率翻倍的秘密
热门推荐
一个账号试用1000+ API
助力AI无缝链接物理世界 · 无需多次注册