Qwen2.5 写代码:探索智能编程新领域
文章目录
Qwen2.5-Coder 的革命性突破
Qwen2.5-Coder 是一款由阿里巴巴开发的开源大语言模型,专注于代码生成和编程任务的自动化处理。它的出现为开发人员提供了强大的工具,能够帮助他们更高效地完成复杂的编程任务。Qwen2.5-Coder 的设计不仅在于生成代码,还能进行代码推理、补全和修复,这使得它在自动化编程领域具有广泛的应用潜力。
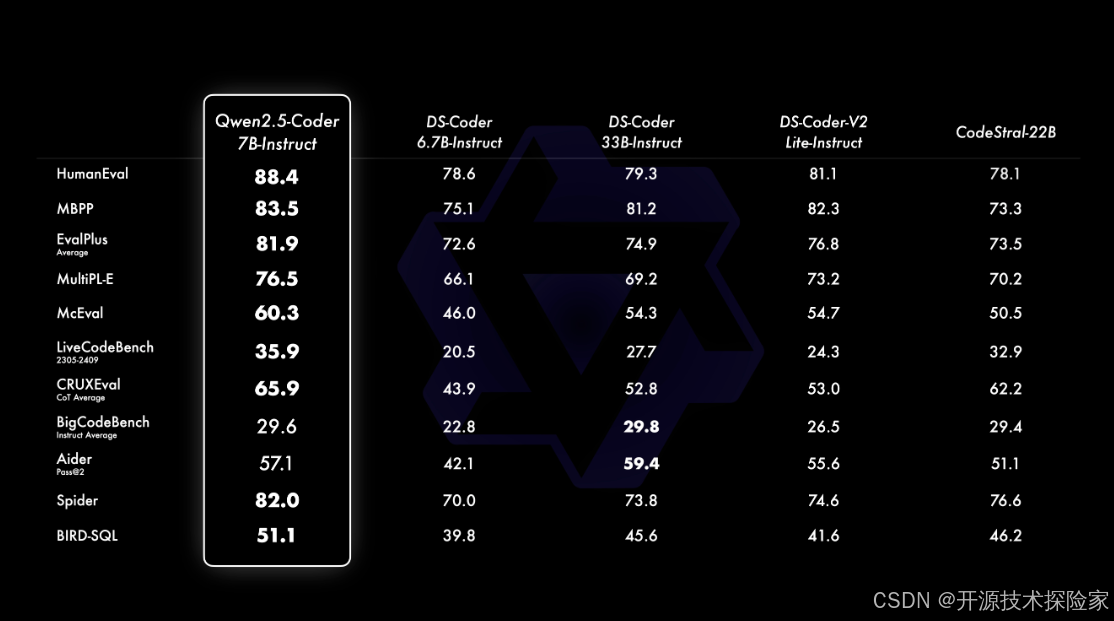
模型的核心特点
海量训练数据
Qwen2.5-Coder 利用超过 5.5 万亿个 token 的编程相关数据进行训练,这些数据涵盖了多种源代码、文本-代码关联数据和合成数据。这种大规模的数据使得模型能够从中学习到丰富的编程知识和模式,为开发者提供精确的代码建议。
多语言支持
该模型支持多达 92 种编程语言,能够在不同编程语言之间切换自如。这为开发者提供了极大的灵活性和方便性,尤其是在多语言项目中。
长上下文处理能力
Qwen2.5-Coder 的上下文处理能力可达 128K tokens,这使得它能够处理大规模的代码文本和复杂的编程逻辑。这种能力尤其适合大型项目和复杂代码库的处理。
不同参数规模的模型版本
模型提供了多种参数规模的版本,包括 1.5B、7B 和即将推出的 32B 版本,以满足不同用户和应用场景的需求。
Qwen2.5-Coder 的应用场景
代码生成和补全
Qwen2.5-Coder 可以根据特定需求生成完整的代码,同时支持代码补全功能。例如,在开发过程中,开发者只需输入部分代码,模型便可自动补全剩余部分,极大提高了开发效率。
代码修复
模型不仅可以生成代码,还能修复代码中的错误。例如,当冒泡排序算法出现错误时,Qwen2.5-Coder 可以自动发现并修正错误,使得代码能够正常运行。
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
def bubble_sort(nums):
n = len(nums)
for i in range(n):
for j in range(0, n-i-1):
if nums[j] < nums[j+1]:
nums[j], nums[j+1] = nums[j+1], nums[j]
return nums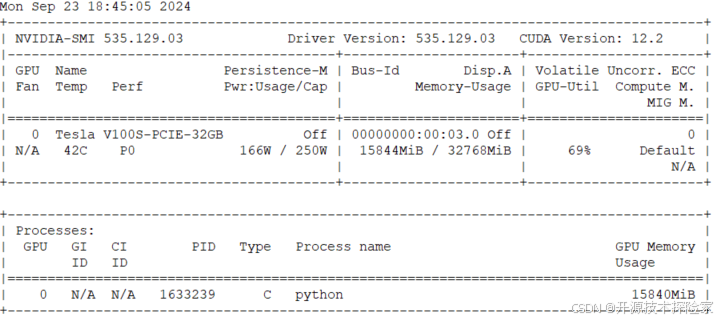
Qwen2.5-Coder 的安装与部署
基础环境准备
Qwen2.5-Coder 的安装需要一定的硬件支持,推荐的操作系统是 CentOS 7,GPU 需要支持 CUDA 12.2 版本,例如 Tesla V100-SXM2-32GB。
下载与安装
模型的下载可以通过 Hugging Face 平台进行,用户可以根据实际需求选择不同的模型规格。
git clone https://www.modelscope.cn/qwen/Qwen2.5-Coder-7B-Instruct.git安装完成后,通过以下命令激活虚拟环境并安装依赖库:
conda create --name qwen2.5 python=3.10
conda activate qwen2.5
pip install transformers torch accelerateQwen2.5-Coder 的使用指南
生成代码示例
Qwen2.5-Coder 可以根据用户输入的提示生成代码,以下是使用该模型生成 Python 冒泡排序算法的示例:
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
def loadTokenizer():
tokenizer = AutoTokenizer.from_pretrained('/data/model/qwen2.5-coder-7b-instruct')
return tokenizer
def loadModel(config):
model = AutoModelForCausalLM.from_pretrained(
'/data/model/qwen2.5-coder-7b-instruct',
torch_dtype="auto",
device_map="auto"
)
model.generation_config = config
return model代码修复功能
模型不仅可以生成代码,还能修复代码中的错误。例如,当冒泡排序算法出现错误时,Qwen2.5-Coder 可以自动发现并修正错误,使得代码能够正常运行。
from transformers import AutoModelForCausalLM, AutoTokenizer, GenerationConfig
def bubble_sort(nums):
n = len(nums)
for i in range(n):
for j in range(0, n-i-1):
if nums[j] < nums[j+1]:
nums[j], nums[j+1] = nums[j+1], nums[j]
return nums
Qwen2.5-Coder 的未来展望
随着人工智能技术的不断进步,Qwen2.5-Coder 的应用前景将更加广阔。未来,模型将不断优化和升级,以适应更为复杂的编程任务和应用场景。
FAQ
问:Qwen2.5-Coder 可以支持哪些编程语言?
答:Qwen2.5-Coder 支持多达 92 种编程语言,包括 Python、Java、C++、JavaScript 等主流编程语言。
问:如何安装 Qwen2.5-Coder?
答:您可以通过 Hugging Face 或 ModelScope 下载模型,并在符合要求的硬件环境下安装和运行。
问:Qwen2.5-Coder 的主要功能有哪些?
答:Qwen2.5-Coder 主要提供代码生成、补全、修复等功能,能够在多种编程任务中提供帮助。
问:Qwen2.5-Coder 的应用场景有哪些?
答:该模型适用于软件开发、代码审核、编程教学等多个领域,能够显著提升开发效率和代码质量。
问:模型支持长上下文是什么意思?
答:这意味着 Qwen2.5-Coder 可以处理较长的代码输入,支持高达 128K tokens 的上下文长度,有助于处理大型代码库和复杂逻辑。