PixArt-α 常用提示词:探索高效的文本到图像生成模型
PixArt-α 的训练策略分解
PixArt-α 是一种创新的文本到图像(T2I)生成模型,其核心设计之一是训练策略的分解。传统的 T2I 模型通常将复杂的生成任务视为一个整体,这往往导致训练效率低下。PixArt-α 则通过将任务拆解为三个独立的阶段来提高效率:
首先是像素依赖学习阶段,该阶段专注于捕捉图像中复杂的像素级依赖关系。通过使用类条件模型初始化 T2I 模型,PixArt-α 能够在较低的成本下实现自然图像的像素分布学习。
接下来是文本图像对齐阶段,这个阶段的挑战在于如何在文本和图像之间实现精确对齐。PixArt-α 使用高概念密度的数据集进行训练,以确保在每次迭代中模型都能有效地学习到更多的名词和概念。
最后是高美学质量图像生成阶段,PixArt-α 利用高质量的美学数据进行微调,以生成高分辨率的图像。这一阶段的训练收敛速度显著加快,主要得益于前几个阶段建立的强大先验知识。
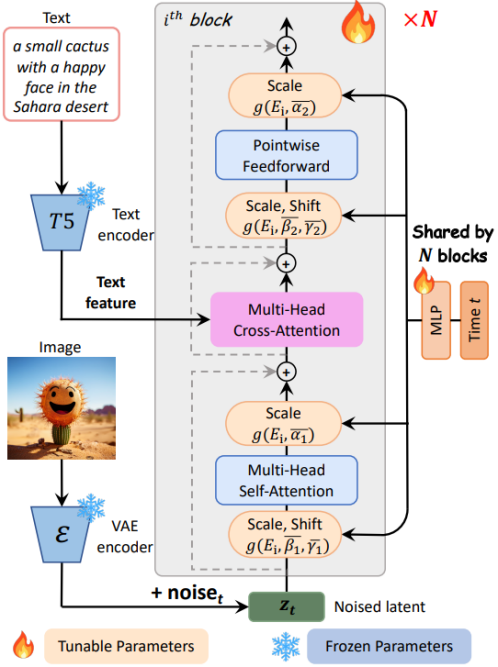
高效 T2I Transformer 架构
PixArt-α 的架构基于 Diffusion Transformer (DiT),并进行了创新性调整,以应对 T2I 任务的挑战。其主要改进在于引入了交叉注意力层(Cross-Attention Layer),该层位于自注意力层和前馈层之间,能够更灵活地与文本嵌入进行交互。
同时,PixArt-α 采用了一种名为 AdaLN-single 的模块,以降低模型的参数量。该模块在模型的第一层中独立控制时间特征嵌入,并在所有层中共享。为了保持与预训练权重的兼容性,PixArt-α 进行了重参数化设计,使其能够有效减少模型尺寸而不影响生成能力。
数据构建与自动化标注工具
PixArt-α 的成功离不开其高信息密度的数据集。为了提高文本图像对的质量,研究团队开发了一种自动化标注工具,利用先进的视觉语言模型(如 LLaVA)生成高质量的图像标题。
在数据集选择上,PixArt-α 使用了 SAM 数据集,该数据集以其复杂多样的对象组合而闻名。通过与 LLaVA 的结合,这些数据集为模型提供了丰富的信息密度,显著提升了文本图像对齐的效率。
量化指标验证
在图像生成质量和效率方面,PixArt-α 展现出了卓越的性能。在多项指标测试中,PixArt-α 均表现优异。在用户研究中,参与者对 PixArt-α 的图像质量和文本对齐度给予了高度评价。基于 T2I-CompBench 的对齐评估显示,PixArt-α 在属性绑定、对象关系和复杂组合方面均超越了其他模型。

方法可拓展性:ControlNet & Dreambooth
PixArt-α 的设计不仅限于当前的应用,还具有很强的拓展性。结合 ControlNet 和 Dreambooth,PixArt-α 能够生成高质量的个性化图像。通过简单的文本提示和样本图片,PixArt-α 可以生成与环境自然互动的图像,展示其强大的定制化能力。

结论
PixArt-α 的推出标志着 T2I 生成模型的又一飞跃。通过创新的训练策略分解、高效的 Transformer 架构以及高信息量的数据集,PixArt-α 不仅降低了训练成本,还显著提高了图像生成质量。对于 AIGC 社区和初创公司而言,PixArt-α 提供了一个高效、低成本的解决方案,促进了高质量生成模型的构建。
FAQ
问:PixArt-α 如何降低训练成本?
- 答:PixArt-α 通过将训练任务拆解为三个阶段,并使用高效的 T2I Transformer 架构,以及高信息密度的数据集,显著降低了训练成本。
问:PixArt-α 在图像生成质量上有何优势?
- 答:PixArt-α 通过高概念密度的数据集和高效的架构设计,能够生成高分辨率和高美学质量的图像,同时在文本对齐度上表现出色。
问:PixArt-α 可以应用于哪些领域?
- 答:PixArt-α 可广泛应用于图像编辑、视频生成、3D 资产创建等领域,其高效的生成能力和低成本使其适用于多种应用场景。
问:PixArt-α 如何实现个性化图像生成?
- 答:通过结合 ControlNet 和 Dreambooth,PixArt-α 能够根据用户提供的文本提示和样本图片生成个性化图像。
问:PixArt-α 的架构有哪些创新?
- 答:PixArt-α 引入了交叉注意力层和 AdaLN-single 模块,通过重参数化设计降低了模型参数量,同时保持了高效的生成能力。