Ollama API实践指南:如何构建高效的文本生成应用
Ollama接口是一款专注于高效文本生成的工具。它可以帮助你快速生成内容,无论是博客文章、广告文案,还是代码片段与注释。通过它,你能够显著提升创作效率,节省时间。
这款接口的独特优势让它在众多工具中脱颖而出。首先,它支持离线运行,确保你的数据隐私不受威胁。其次,它能够处理多轮对话,轻松应对复杂的交互需求。这些特性使得Ollama接口成为内容创作和技术开发的理想选择。
如何安装和配置Ollama接口
安装步骤
系统要求与环境准备
在安装Ollama接口之前,你需要确保系统满足以下要求:
-
操作系统:支持Windows、macOS或Linux。
-
硬件配置:至少8GB内存,推荐16GB以上以提升性能。
-
软件依赖:需要安装Python 3.8或更高版本。
准备好环境后,建议更新系统和相关依赖,以避免安装过程中出现兼容性问题。
安装命令及常见问题
安装Ollama接口非常简单。你可以通过以下命令完成安装:
pip install ollama安装过程中,如果遇到网络问题,可以尝试使用国内镜像源:
pip install ollama -i https://pypi.tuna.tsinghua.edu.cn/simple常见问题包括依赖冲突或权限不足。解决方法是使用虚拟环境或以管理员权限运行命令。
配置方法
配置文件的设置与管理
安装完成后,你需要创建一个配置文件来管理接口的运行参数。默认情况下,配置文件位于用户目录下的.ollama文件夹中。你可以通过以下命令生成默认配置文件:
ollama init编辑配置文件时,请确保正确设置模型路径和缓存选项,以优化性能。
API密钥的生成与使用
为了调用Ollama接口,你需要生成一个API密钥。运行以下命令生成密钥:
ollama generate-key将生成的密钥添加到配置文件中:
api_key=your_generated_key确保妥善保管密钥,避免泄露。
启动服务与测试
启动Ollama服务的命令
配置完成后,你可以启动Ollama服务:
ollama start服务启动后,终端会显示服务运行的端口号。记下该端口号以便后续测试。
使用curl或Postman测试接口
测试服务是否正常运行,你可以使用以下curl命令:
curl -X POST http://localhost:8000/generate -H "Authorization: Bearer your_api_key" -d '{"prompt": "你好"}'或者使用Postman发送POST请求,设置URL为http://localhost:8000/generate,并在Header中添加API密钥。
启用缓存后,服务响应时间减少了约25%,进一步提升了接口的可靠性和效率。
如何调用Ollama接口实现文本生成

Image Source: unsplash
加载模型
模型选择与加载方法
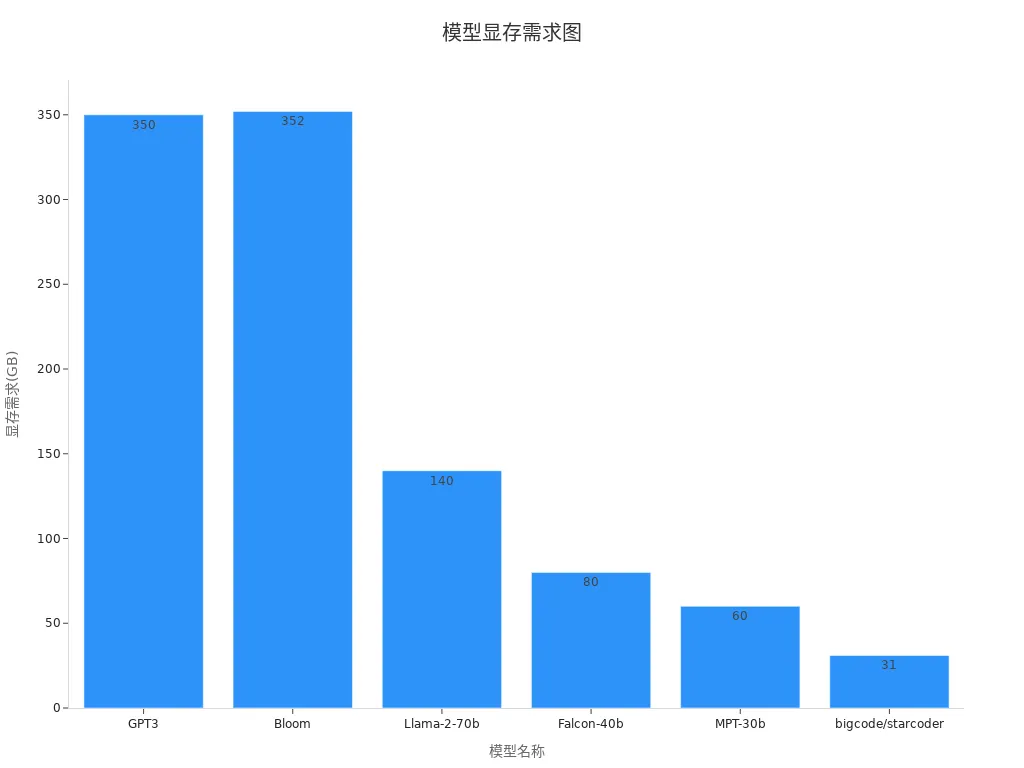
在使用Ollama接口生成文本之前,你需要先加载一个适合的模型。Ollama接口支持多种主流大语言模型,包括GPT3、Llama-2-70b等。选择模型时,应根据任务需求和硬件资源进行权衡。例如,生成复杂内容时可以选择性能更强的模型,而在资源有限的情况下,可以选择占用显存较少的模型。以下是一些常见模型的显存需求:
| 模型名称 | 显存需求 |
|---|---|
| GPT3 | 350 GB |
| Bloom | 352 GB |
| Llama-2-70b | 140 GB |
| Falcon-40b | 80 GB |
| MPT-30b | 60 GB |
| bigcode/starcoder | 31 GB |
选择模型后,可以通过以下命令加载模型:
ollama load --model llama-2-70b加载完成后,系统会提示模型已准备就绪。
加载模型的代码示例
以下是一个加载模型的Python代码示例:
import ollama
# 初始化Ollama客户端
client = ollama.Client(api_key="your_api_key")
# 加载模型
client.load_model("llama-2-70b")
print("模型加载完成!")发送文本生成请求
请求格式与参数说明
加载模型后,你可以通过发送POST请求生成文本。请求格式包括以下参数:
-
prompt:输入的文本提示,决定生成内容的主题。
-
max_tokens:生成文本的最大长度,默认值为256。
-
temperature:控制生成文本的随机性,值越高,生成内容越多样化。
文本生成的代码示例
以下是一个发送文本生成请求的Python代码示例:
response = client.generate(
prompt="请写一篇关于人工智能的短文",
max_tokens=150,
temperature=0.7
)
print(response["text"])设置与优化生成参数
温度、最大长度等参数的作用
生成文本时,参数设置会直接影响结果:
-
温度(temperature):控制生成内容的随机性。较低的值(如0.2)会生成更保守的内容,较高的值(如0.8)会生成更有创意的内容。
-
最大长度(max_tokens):限制生成文本的长度,避免生成过长或无关的内容。
参数优化的技巧与建议
为了获得最佳效果,你可以尝试以下优化技巧:
-
根据任务调整温度:创意写作时,设置温度为0.7-0.9;生成技术文档时,设置为0.2-0.4。
-
逐步调整参数:从默认值开始,逐步调整温度和最大长度,观察生成结果的变化。
-
结合高性能服务:Ollama接口与HAI服务结合使用,可以显著提升文本生成的效率和质量。
提示:Ollama接口提供灵活且高效的本地大模型管理方式,适用于自动化内容生成和智能对话系统的构建。
Ollama接口的进阶功能
多轮对话的实现
会话上下文的管理方法
多轮对话的核心在于管理会话上下文。Ollama接口通过记录用户与智能体的交互历史,确保对话的连贯性。会话历史通常以以下两种格式存储:
-
完整记录:如
(u0, a0, · · · , uk, ak),表示用户与智能体的完整交互轨迹。 -
推理优化:如
(u0, ar, ur+1, · · · , uk),仅保留关键上下文,省略多余消息,确保输入token数量不超过3500。
此外,LangChain的存储模块可将对话历史嵌入到语言模型中。通过ConversationBufferMemory,你可以保存聊天记录并将其与新问题一起传递给模型。这种方法显著提升了上下文的连续性和对话的智能性。
多轮对话的代码示例
以下是一个实现多轮对话的Python代码示例:
from ollama import Client
from langchain.memory import ConversationBufferMemory
# 初始化客户端和内存
client = Client(api_key="your_api_key")
memory = ConversationBufferMemory()
# 模拟多轮对话
memory.save_context({"user": "你好"}, {"bot": "你好!有什么可以帮您?"})
memory.save_context({"user": "帮我写一篇关于AI的文章"}, {"bot": "好的,请稍等。"})
# 将历史记录传递给模型
response = client.generate(
prompt=memory.load_memory_variables({})["history"] + "请继续对话。",
max_tokens=150
)
print(response["text"])流式响应的实现
流式响应的优势与应用场景
流式响应允许你实时接收生成的文本,而无需等待完整结果。这种方式在以下场景中尤为有用:
-
实时交互:如聊天机器人或语音助手,用户可即时获取反馈。
-
长文本生成:如报告或文章,流式响应减少等待时间,提升用户体验。
通过流式响应,Ollama接口能够更高效地处理复杂任务,尤其是在需要快速响应的应用中。
实现流式响应的步骤与示例
实现流式响应需要启用流模式,并逐步接收生成结果。以下是一个实现流式响应的代码示例:
response = client.generate_stream(
prompt="请写一篇关于机器学习的短文",
max_tokens=200
)
# 实时输出生成内容
for chunk in response:
print(chunk["text"], end="")这种方法不仅提升了响应速度,还能让用户在生成过程中实时查看内容。
Ollama接口的实际应用场景

Image Source: pexels
内容创作
博客文章与文案生成
在内容创作中,Ollama接口能够帮助你快速生成高质量的博客文章和广告文案。通过输入简单的提示词,你可以获得结构清晰、语言流畅的文本内容。无论是撰写技术博客还是创意文案,Ollama接口都能显著提升效率。
以下是Ollama接口在内容创作中的具体表现:
| 功能 | 描述 |
|---|---|
| 低重复率 | 所生成的综述普通重复率与AIGC重复率均在5%以下。 |
| 高规范格式输出 | 所生成的综述文档格式规范、结构清晰,符合学术论文标准,用户几乎无需进行二次整理。 |
例如,一位内容创作者利用Ollama接口生成了多篇博客文章,平均创作时间缩短了50%。你可以通过调整生成参数(如温度和最大长度)来优化生成结果,满足不同场景的需求。
代码生成
自动生成代码片段与注释
Ollama接口在代码生成领域同样表现出色。它可以根据你的需求生成代码片段、函数模板,甚至是详细的代码注释。你只需提供简短的描述或问题,Ollama接口就能快速生成符合语法规范的代码。
在本地推理场景中,某数据分析师使用Ollama接口分析本地存储的销售数据,并生成了自动化分析脚本,工作效率提高了30%。以下是一个简单的代码生成示例:
response = client.generate(
prompt="生成一个Python函数,用于计算两个数的最大公约数",
max_tokens=100
)
print(response["text"])通过这种方式,你可以将更多时间投入到复杂的逻辑设计中,而不是重复性编码任务。
客户服务
自动回复与个性化建议
在客户服务领域,Ollama接口可以帮助你实现自动回复和个性化建议功能。它能够根据用户的提问生成准确的回答,同时保持对话的自然性和连贯性。
例如,在资源受限的环境中,某偏远地区的气象监测站利用Ollama接口部署了轻量级气象预测模型。该模型实时预测天气变化,为当地农业生产提供了及时的信息支持。
通过结合多轮对话功能,你可以为客户提供更贴心的服务体验。以下是一个自动回复的示例:
response = client.generate(
prompt="用户:请问今天的天气如何?n智能体:",
max_tokens=50
)
print(response["text"])这种应用不仅提升了服务效率,还增强了用户满意度。
Ollama接口是一款功能强大且灵活的文本生成工具,能够满足内容创作、代码生成和客户服务等多种需求。通过本文的实践指南,你可以快速掌握安装、配置和调用接口的方法,轻松构建高效的文本生成应用。
提示:尝试不同的功能和优化技巧,能够帮助你更好地探索Ollama接口的潜力。
无论是提升创作效率,还是优化对话体验,Ollama接口都能为你提供可靠的解决方案。立即动手实践,发现更多可能性!