

NG是什么意思:深度解析与应用

大语言模型(LLM)在人工智能领域的应用日益广泛,推动了对推理优化技术的深入研究。本文将探讨LLM推理的优化策略及其在不同平台上的应用。
在大规模语言模型的训练中,32位浮点数是常见的选择。然而,这种精度的模型通常需要大量的显存,导致推理速度缓慢且资源消耗大。模型量化技术通过将高精度参数转换为低精度参数(如从32位浮点数转换为8位整数),有效减少了内存占用并提升了推理速度。
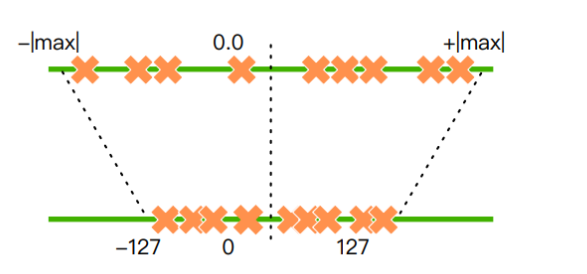
量化方法主要包括量化训练(QAT)、动态离线量化(PTQ Dynamic)和静态离线量化(PTQ Static)。这些方法各有优劣,通常根据具体应用场景选择。
llama.cpp是GGML开发者推出的纯C/C++推理引擎,支持多种设备和操作系统,能够在低配硬件上运行量化后的模型。其高效的硬件利用率使得推理速度显著提升。
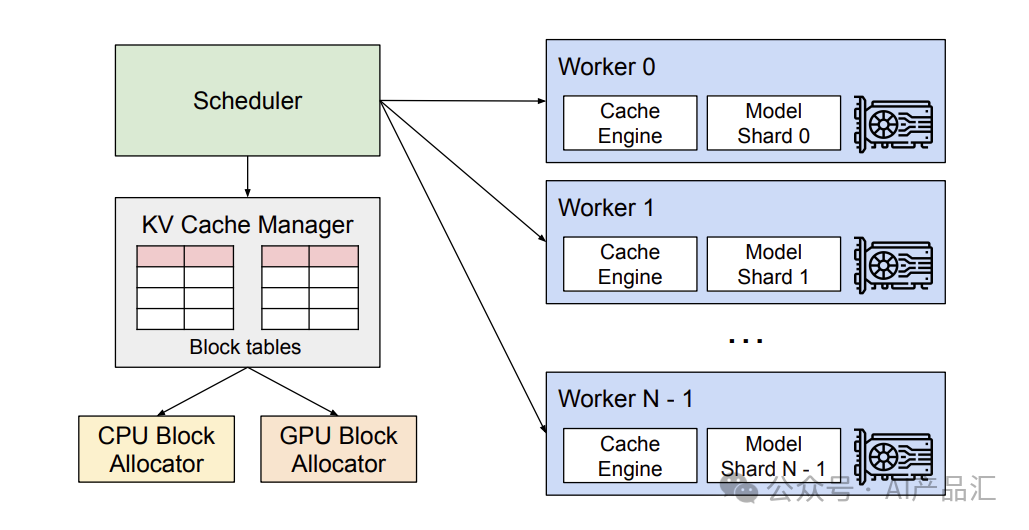
vLLM是加州大学伯克利分校开发的GPU推理框架,采用PagedAttention管理KV缓存,有效提升了大模型的运行速度。支持多种量化方法,适用于NVIDIA和AMD GPUs。
Xorbits Inference提供了一键部署的能力,支持多模态模型的推理。通过该平台,可以利用最前沿的AI模型进行创新应用的开发。
Dify.AI是一个开源的LLM应用开发平台,支持多种大型语言模型。其强大的Prompt IDE和RAG引擎帮助用户快速构建AI应用。
随着LLM的快速发展,推理优化将成为提升模型性能的关键。未来的优化将更多地依赖于硬件的创新和算法的改进,以满足更高效、更节能的需求。






