掌握LLM推理技术:优化与应用
作者:zhilong · 2025-02-01 · 阅读时间:4分钟
大语言模型(LLM)在人工智能领域的应用日益广泛,推动了对推理优化技术的深入研究。本文将探讨LLM推理的优化策略及其在不同平台上的应用。
模型量化的必要性
在大规模语言模型的训练中,32位浮点数是常见的选择。然而,这种精度的模型通常需要大量的显存,导致推理速度缓慢且资源消耗大。模型量化技术通过将高精度参数转换为低精度参数(如从32位浮点数转换为8位整数),有效减少了内存占用并提升了推理速度。
模型量化的优点
- 保持精度:尽管量化会引入精度损失,但神经网络对噪声不太敏感,只要控制得当,可以维持任务精度。
- 加速计算:低比特位数的运算速度更快,INT8与FP32相比,速度可提升3倍以上。
- 节省内存:低精度类型占用空间更小,减少了存储和传输时间。
- 节能:减少了访存开销,降低了能耗,同时也减少了芯片面积。
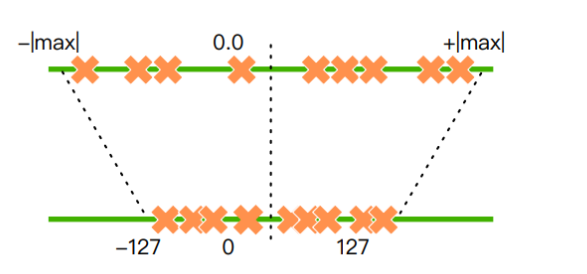
量化方法与原理
量化方法主要包括量化训练(QAT)、动态离线量化(PTQ Dynamic)和静态离线量化(PTQ Static)。这些方法各有优劣,通常根据具体应用场景选择。
推理框架介绍
llama.cpp
llama.cpp是GGML开发者推出的纯C/C++推理引擎,支持多种设备和操作系统,能够在低配硬件上运行量化后的模型。其高效的硬件利用率使得推理速度显著提升。
vLLM
vLLM是加州大学伯克利分校开发的GPU推理框架,采用PagedAttention管理KV缓存,有效提升了大模型的运行速度。支持多种量化方法,适用于NVIDIA和AMD GPUs。
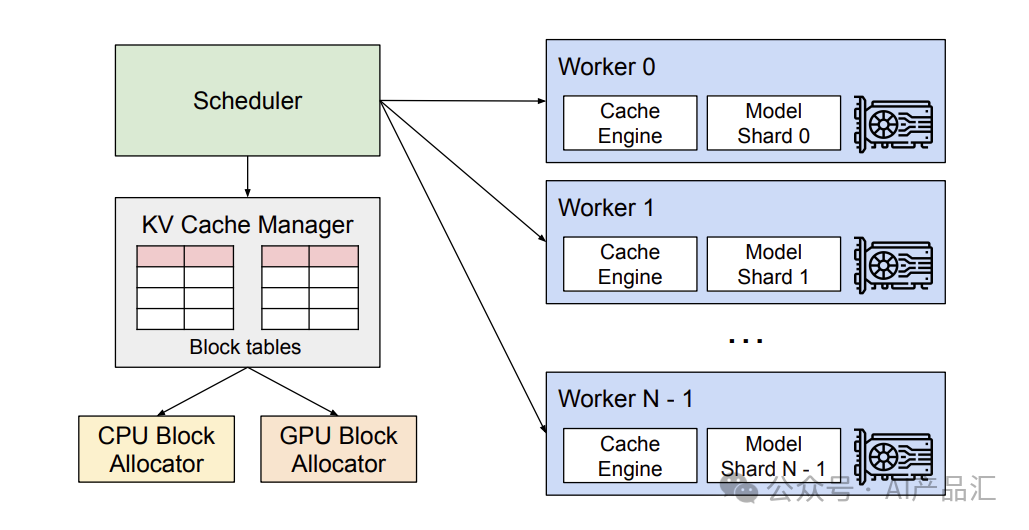
大模型应用开发平台
Xorbits Inference
Xorbits Inference提供了一键部署的能力,支持多模态模型的推理。通过该平台,可以利用最前沿的AI模型进行创新应用的开发。
dify
Dify.AI是一个开源的AI应用。
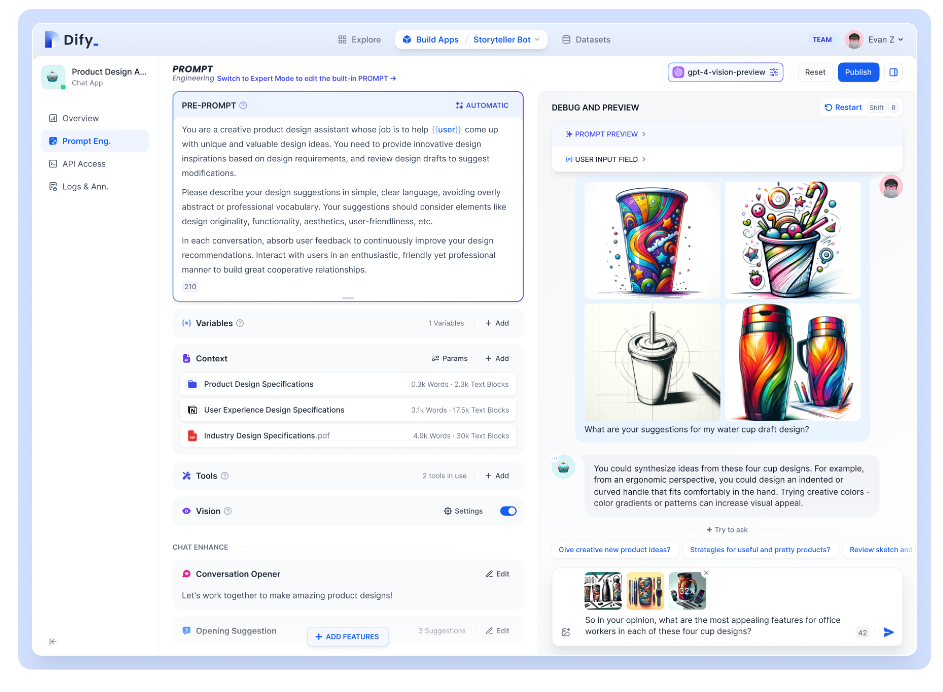
推理优化的未来展望
随着LLM的快速发展,推理优化将成为提升模型性能的关键。未来的优化将更多地依赖于硬件的创新和算法的改进,以满足更高效、更节能的需求。
FAQ
问:什么是模型量化?
- 答:模型量化是将浮点数计算转换为低比特位整数计算的过程,以降低模型的计算复杂度和内存占用。
问:模型量化会影响模型精度吗?
- 答:量化可能引入一些精度损失,但通过控制量化程度和方法,可以将精度损失降到最低。
问:如何选择合适的推理框架?
- 答:选择推理框架应根据应用场景、硬件条件和模型特性进行综合评估。CPU推理适合使用llama.cpp,而GPU推理可以选择DeepSpeed-FastGen。
问:Xorbits Inference如何支持多模态模型?
- 答:Xorbits Inference通过内置的资源调度器和多种接口,语音识别模型和多模态模型的部署和推理。
问:如何提高推理速度?
- 答:可以通过模型量化、优化CUDA kernels和使用高效的推理框架(如DeepSpeed)来提升推理速度。
热门推荐
一个账号试用1000+ API
助力AI无缝链接物理世界 · 无需多次注册
3000+提示词助力AI大模型
和专业工程师共享工作效率翻倍的秘密