Linear层深度解析:PyTorch中的神经网络基础
文 | AI_study
在深度学习领域,Linear层作为构建神经网络的基石,扮演着不可或缺的角色。本文将深入探讨Linear层的工作原理、实现方式以及在PyTorch中的应用,旨在帮助读者全面理解这一核心组件。
Linear层的基本概念
Linear层,也称为全连接层(Fully Connected layer),是深度学习模型中最基本的组成部分之一。它执行线性变换,将输入数据映射到输出数据。线性变换意味着输出是输入的加权总和,即 y = b + wx,其中 b 是偏置(bias),w 是权重(weights),x 是输入。在线性层中,权重和偏置是模型需要学习的参数。通过反向传播和梯度下降等优化算法,模型会调整这些参数以最小化损失函数,从而改善模型的预测能力。
Linear层与矩阵乘法
当输入特征被一个Linear层接收时,它们以一个展平成一维张量的形式接收,然后乘以权重矩阵。这个矩阵乘法产生输出特征。
一、使用矩阵进行变换
让我们通过一个简单的代码示例来理解这一过程。
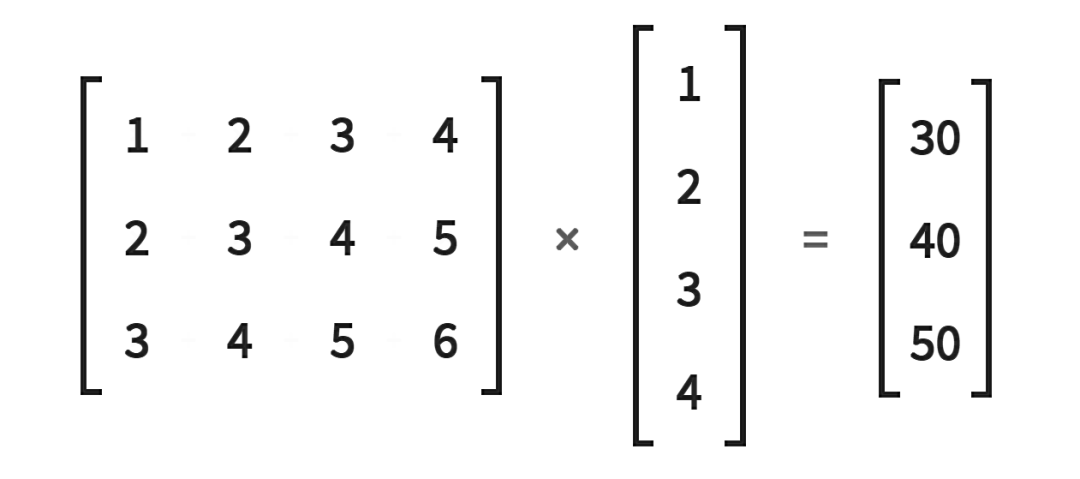
in_features = torch.tensor([1,2,3,4], dtype=torch.float32)
weight_matrix = torch.tensor([
[1,2,3,4],
[2,3,4,5],
[3,4,5,6]
], dtype=torch.float32)
> weight_matrix.matmul(in_features)
tensor([30., 40., 50.])在这里,我们创建了一个一维张量in_features和一个权重矩阵weight_matrix。使用matmul()函数来执行矩阵乘法运算。
二、使用PyTorch线性层进行变换
接下来,我们看看如何创建一个PyTorch的Linear层来完成相同的操作。
fc = nn.Linear(in_features=4, out_features=3, bias=False)这里,我们定义了一个线性层,它接受4个输入特征并把它们转换成3个输出特征,所以我们从4维空间转换到3维空间。

Linear层的内部实现
我们将权重矩阵放在PyTorch LinearLayer类中,是由PyTorch创建。PyTorch LinearLayer类使用传递给构造函数的数字4和3来创建一个3 x 4的权重矩阵。让我们通过查看PyTorch源代码来验证这一点。
def __init__(self, in_features, out_features, bias=True):
super(Linear, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.Tensor(out_features, in_features))
if bias:
self.bias = Parameter(torch.Tensor(out_features))
else:
self.register_parameter('bias', None)
self.reset_parameters()三、线性变换的数学符号
有时我们会看到Linear层操作被称为 y=Ax+b。在这个方程中,我们有:

可调用的层和神经网络
我们之前指出过,我们把层对象实例当作一个函数来调用是多么奇怪。
> fc(in_features)
tensor([-0.8877, 1.4250, 0.8370], grad_fn=)使这成为可能的是PyTorch模块类实现了另一个特殊的Python函数,称为__call__()。如果一个类实现了__call__()方法,那么只要对象实例被调用,这个特殊的调用方法就会被调用。
四、PyTorch中的call()方法
让我们在PyTorch源代码中看看这一点。
def __call__(self, *input, **kwargs):
for hook in self._forward_pre_hooks.values():
hook(self, input)
if torch._C._get_tracing_state():
result = self._slow_forward(*input, **kwargs)
else:
result = self.forward(*input, **kwargs)
for hook in self._forward_hooks.values():
hook_result = hook(self, input, result)
if hook_result is not None:
raise RuntimeError(
"forward hooks should never return any values, but '{}'"
"didn't return None".format(hook))
if len(self._backward_hooks) > 0:
var = result
while not isinstance(var, torch.Tensor):
if isinstance(var, dict):
var = next((v for v in var.values() if isinstance(v, torch.Tensor)))
else:
var = var[0]
grad_fn = var.grad_fn
if grad_fn is not None:
for hook in self._backward_hooks.values():
wrapper = functools.partial(hook, self)
functools.update_wrapper(wrapper, hook)
grad_fn.register_hook(wrapper)
return resultFAQ
1. 问:Linear层和Dense层有什么区别?
- 答:实际上,Linear层和Dense层是相同的。在PyTorch中,它们都指的是全连接层,负责实现输入到输出的线性映射。
2. 问:如何在PyTorch中创建Linear层?
- 答:在PyTorch中,可以通过
nn.Linear(in_features, out_features, bias=True)来创建Linear层,其中in_features是输入特征的数量,out_features是输出特征的数量,bias表示是否包含偏置项。
3. 问:Linear层的权重和偏置是如何学习的?
- 答:Linear层的权重和偏置通过反向传播算法进行学习。在训练过程中,模型计算每个样本的梯度,并将梯度传播回权重矩阵和偏置向量。然后,通过梯度下降算法更新这些参数的值,以减小预测错误。
4. 问:为什么需要在Linear层后应用激活函数?
- 答:激活函数用于引入非线性,使得神经网络可以学习和模拟更复杂的函数。没有激活函数,即使网络有很多层,本质上也只是在执行线性变换,无法解决非线性问题。
5. 问:Linear层在神经网络中的作用是什么?
- 答:Linear层在神经网络中主要负责将输入特征映射到输出特征,实现特征的线性组合。此外,它还可以通过引入偏置项和激活函数,增加模型的灵活性和表达能力。