自动化RAG项目评估测试:TruLens的应用与实践
大语言模型知识问答的应用背景
随着人工智能的发展,大语言模型(LLM)在问答系统、聊天机器人、文档摘要和内容生成等领域展现出巨大的潜力。然而,在实际应用中,这些模型需要面对复杂多变的用户需求和庞大的知识库,这就需要一套系统化的评估和优化工具来提升其性能和准确性。这篇文章将深入探讨如何使用TruLens进行自动化RAG(检索-生成)项目的评估测试,以确保LLM应用的质量和可靠性。
TruLens框架的核心原理
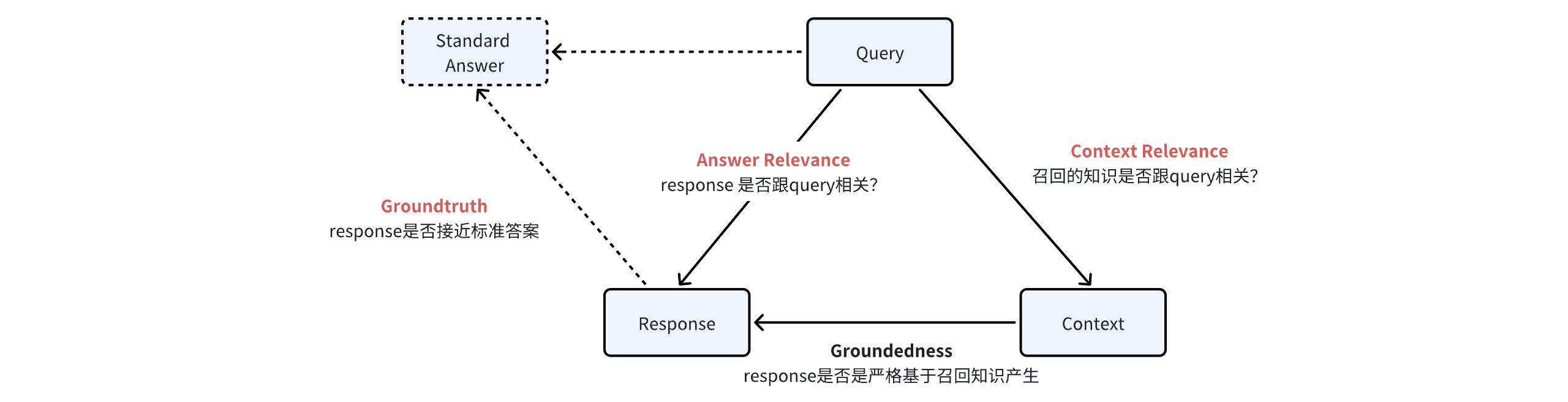
TruLens通过引入反馈函数(Feedback Function),以编程方式评估LLM应用的输入、输出和中间结果的质量。反馈函数就像是一个个的打分器,帮助我们判断应用在哪些方面表现良好,哪些方面需要改进。以Groundedness评估为例,它通过对比Response和Context,判断答案是否基于知识库生成,实现更为准确的评价。
反馈函数的作用机制
- 连接应用:通过API将TrulensApp连接到LLM应用,开始追踪并记录Query、Response和Context。
- 打分机制:使用Groundedness Feedback函数,将Context和Response加载到提示词模板中,通过模型打分来评估。
- 结果展示:打分结果可以在TruLens的仪表板中查看,便于后续分析和优化。
主要评估方式的详细介绍
在RAG知识问答项目中,TruLens提供了四种主要的评估方式:
基于知识的评估(Groundedness)
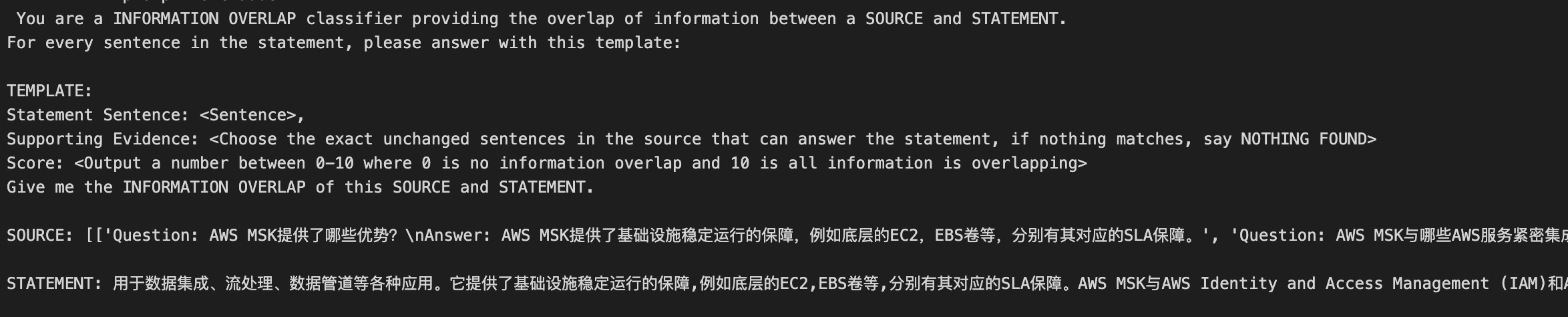
Groundedness评估主要用于检测LLM的“幻觉”现象,即生成的回答是否真的基于知识库中的信息。通过分析Response中的句子在Context中的存在证据,TruLens可以判断回答的可靠性。
回答相关性评估(Answer Relevance)
Answer Relevance评估侧重于判断Response与Query的相关性。即便答案较长或较短,评估标准都应保持一致,确保答案的相关性和准确性。与问题相关的回答可获得更高的得分。
知识召回相关性评估(Context Relevance)
Context Relevance评估用于判断召回的知识是否与Query相关。通过对比召回内容与问题的匹配程度,TruLens能有效识别知识库中的冗余信息,提升召回效率。
回答准确性评估(Groundtruth)
Groundtruth评估通过将Response与标准答案进行对比,评估答案的准确性。评分标准为1到10之间的整数,越接近正确答案得分越高。
实际使用方法与环境准备
使用TruLens进行评估测试非常简单,只需按照以下步骤进行操作:
环境配置与工具安装
- 在AWS海外region部署RAG项目,确保环境中安装aws cli和jupyter notebook。
- 配置AWS IAM用户的权限,确保能够调用lambda和bedrock。
- 下载测试脚本并运行,准备好测试集列表。
代码实现和测试步骤
通过定义RAG_from_scratch类,连接RAG应用,并为函数添加装饰器@instrument,以便记录输入输出。使用Claude作为评估模型,定义反馈函数进行评估。
class RAG_from_scratch:
@instrument
def retrieve(self, query: str) -> list:
results = self.call_remote_service(query, retrieve_only=True)
return [result['doc'] for result in results]启动TruLens仪表盘
运行测试后,通过run_dashboard()生成链接,查看测试结果和详细分数。
应用案例分析
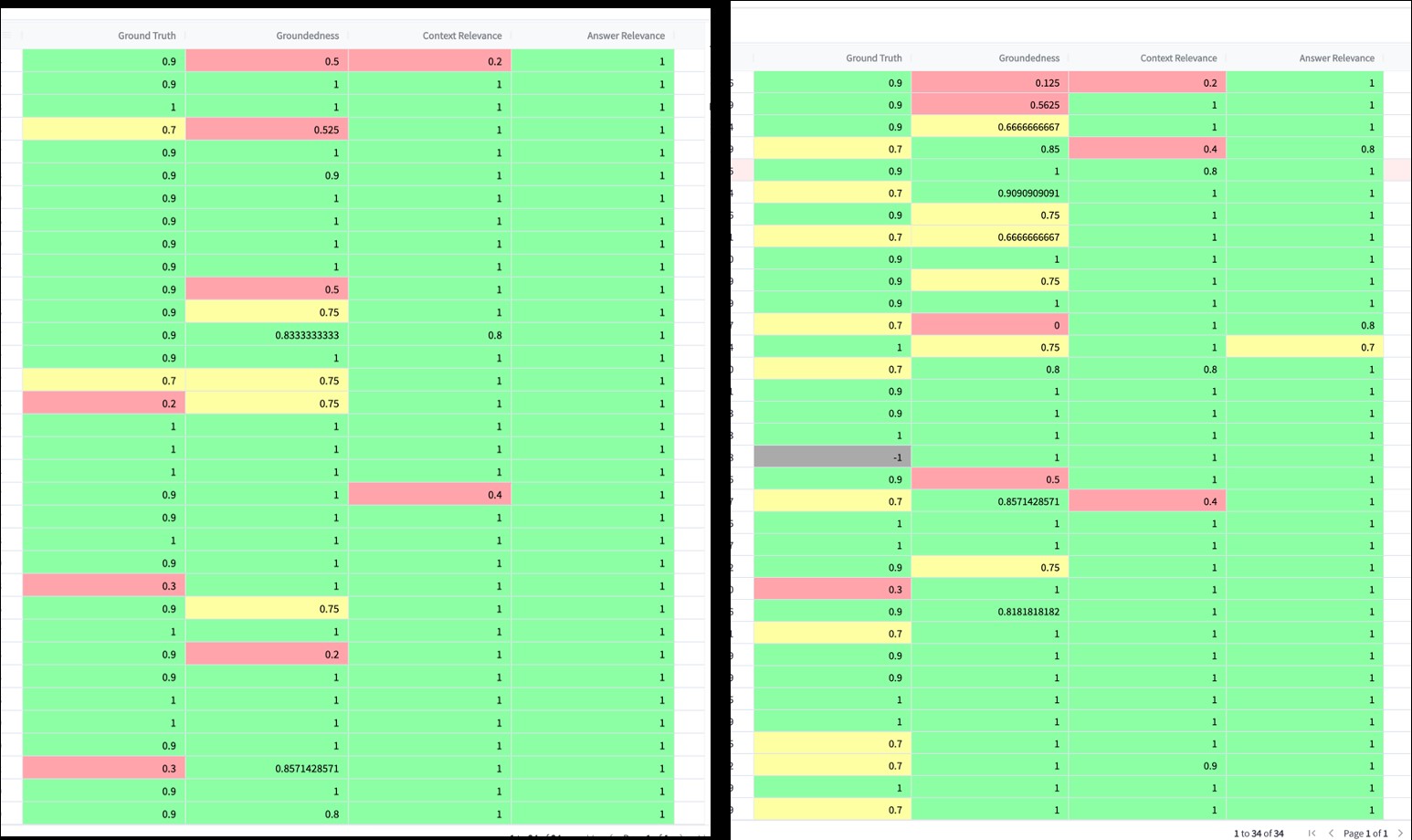
在实际应用中,我们可以使用TruLens对不同版本的提示词模板进行效果测试。例如,在对比Template v1和Template v2时,通过TruLens的得分明细,我们可以清晰地看到哪个版本的模板效果更佳。
总结与未来展望
TruLens为LLM应用提供了一种系统化的评估方法,能够有效衡量应用的性能和质量,并跟踪每次迭代后的改善情况。尽管在实验中发现Claude v2模型在评估模型中的表现更加稳定,但TruLens仍需依赖LLM进行结果评估,因此可能存在个别评估结果偏差的情况。
未来,随着TruLens的不断发展和完善,我们将能够更好地为LLM应用提供高效的评估和优化方案,推动人工智能技术的进一步落地。
FAQ
-
问:TruLens主要适用于哪些场景?
- 答:TruLens主要应用于LLM问答系统、聊天机器人、文档摘要等场景,帮助开发者评估和优化模型的性能和质量。
-
问:如何提升RAG项目的评估效果?
- 答:可以通过增加测试集的丰富性,以及结合TruLens提供的多种评估方式,提升RAG项目的评估效果。
-
问:TruLens是否支持本地化部署?
- 答:TruLens主要依赖于云端服务,目前不支持在本地化环境中独立部署。
-
问:Claude v2和v2.1在评估中的差异在哪里?
- 答:Claude v2在评估中更加稳定,而v2.1由于合规和安全性限制可能导致评估结果的不一致。
-
问:如何确保评估结果的准确性?
- 答:通过使用足够丰富的测试集(>=30个问题),并结合多种评估方式,可以确保评估结果的准确性。