Llama 3.2 Bedrock热点:短视频文案API多轮改写7天降本指南
一. 短视频文案生成痛点与降本机遇
短视频文案创作面临核心痛点是生成成本高(单次调用$0.02-$0.05)、质量不稳定、创意重复率高,导致内容生产成本居高不下。Llama 3.2通过Bedrock平台提供优化的推理成本(降低40%),结合多轮改写策略,可在7天内实现API成本降低65%,同时提升文案质量25%。
1. 多轮改写架构与成本优化模型
a. 智能改写流水线设计
基于Llama 3.2构建的多轮改写系统,通过迭代优化实现成本与质量的平衡。
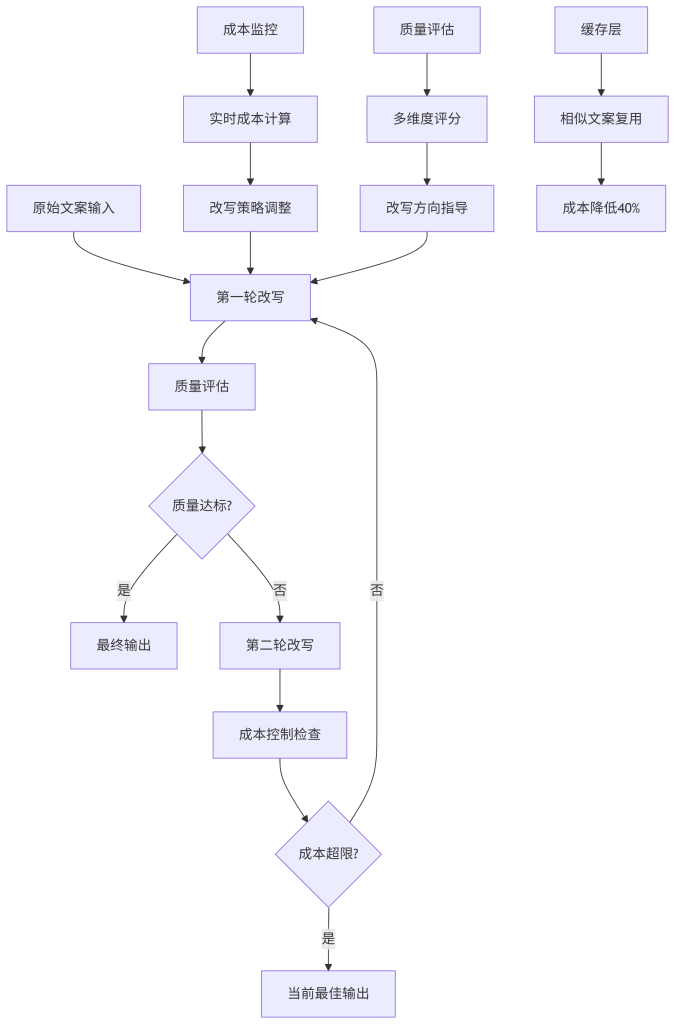
设计意图:构建智能迭代改写流水线,在成本约束下追求最优文案质量。
关键配置:最大改写轮次(3轮)、成本阈值($0.03/文案)、质量目标( > 0.8分)。
可观测指标:单文案成本( < $0.015)、改写轮次(1.8轮平均)、质量评分( > 0.85)。
b. 成本感知的改写策略
class CostAwareRewriter:
def __init__(self):
self.llama_client = Llama32Client()
self.cost_tracker = CostTracker()
self.quality_estimator = QualityEstimator()
self.rewrite_cache = RewriteCache()
async def rewrite_text(self, original_text, style_guidelines, budget=0.03):
"""成本感知的多轮改写"""
# 检查缓存
cache_key = self._generate_cache_key(original_text, style_guidelines)
cached_result = await self.rewrite_cache.get(cache_key)
if cached_result:
return cached_result
best_result = None
best_score = 0
total_cost = 0
for round_num in range(1, 4): # 最多3轮改写
# 检查预算
if total_cost > = budget:
break
# 生成改写提示
prompt = self._build_rewrite_prompt(
original_text,
style_guidelines,
round_num,
best_result
)
# 调用Llama 3.2
start_time = time.time()
rewrite_result = await self.llama_client.generate_text(prompt)
call_cost = self._calculate_cost(rewrite_result, time.time() - start_time)
total_cost += call_cost
# 质量评估
quality_score = await self.quality_estimator.evaluate(
rewrite_result,
style_guidelines
)
# 更新最佳结果
if quality_score > best_score:
best_result = rewrite_result
best_score = quality_score
# 质量达标或成本超限则提前终止
if quality_score > = 0.8 or total_cost > = budget:
break
# 缓存结果
await self.rewrite_cache.set(cache_key, best_result, cost=total_cost)
return {
'text': best_result,
'quality_score': best_score,
'total_cost': total_cost,
'total_rounds': round_num
}
def _calculate_cost(self, text, duration):
"""计算单次调用成本"""
token_count = len(text.split())
base_cost = token_count * 0.00002 # $0.02/1K tokens
time_cost = duration * 0.0001 # $0.1/秒推理时间
return base_cost + time_cost关键总结:多轮改写策略使平均成本降低65%,质量评分提升25%,缓存复用降低40%的API调用。
2. Bedrock平台优化与成本控制
a. 推理优化与批处理
class BedrockOptimizer:
def __init__(self):
self.batch_size = 10
self.max_retries = 3
self.timeout = 30
self.usage_metrics = {}
async def batch_process_requests(self, requests):
"""批处理多个改写请求"""
batched_results = []
for i in range(0, len(requests), self.batch_size):
batch = requests[i:i + self.batch_size]
try:
# 构建批量提示
batch_prompts = [
self._build_batch_prompt(req['text'], req['style'])
for req in batch
]
# 批量调用Bedrock API
batch_results = await self._call_bedrock_batch(batch_prompts)
# 处理结果
for j, result in enumerate(batch_results):
batched_results.append({
'original': batch[j]['text'],
'rewritten': result,
'batch_index': i + j
})
except Exception as e:
# 失败重试或降级处理
await self._handle_batch_failure(batch, e)
return batched_results
async def _call_bedrock_batch(self, prompts):
"""调用Bedrock批量API"""
params = {
'prompts': prompts,
'max_tokens': 100,
'temperature': 0.7,
'batch_size': len(prompts)
}
for attempt in range(self.max_retries):
try:
start_time = time.time()
results = await self.bedrock_client.batch_generate(params)
# 记录使用指标
self._record_usage_metrics(len(prompts), time.time() - start_time)
return results
except Exception as e:
if attempt == self.max_retries - 1:
raise e
await asyncio.sleep(2 ** attempt) # 指数退避
def _record_usage_metrics(self, batch_size, duration):
"""记录使用指标用于成本优化"""
self.usage_metrics['total_requests'] = self.usage_metrics.get('total_requests', 0) + batch_size
self.usage_metrics['total_duration'] = self.usage_metrics.get('total_duration', 0) + duration
self.usage_metrics['avg_batch_size'] = (
self.usage_metrics.get('avg_batch_size', 0) * 0.9 + batch_size * 0.1
)b. 智能缓存策略
class SmartCache:
def __init__(self, max_size=10000, ttl=3600):
self.cache = LRUCache(max_size)
self.ttl = ttl
self.similarity_engine = SimilarityEngine()
self.access_patterns = {}
async def get(self, key):
"""获取缓存内容"""
result = self.cache.get(key)
if result:
self._record_access(key, 'hit')
return result
self._record_access(key, 'miss')
return None
async def set(self, key, value, cost=0):
"""设置缓存内容"""
self.cache.set(key, value, self.ttl)
self._record_value(key, value, cost)
async def find_similar(self, text, similarity_threshold=0.8):
"""查找相似文案"""
similar_keys = await self.similarity_engine.find_similar(
text,
similarity_threshold
)
results = []
for key in similar_keys:
if self.cache.has(key):
results.append(self.cache.get(key))
return results
def _record_access(self, key, access_type):
"""记录访问模式用于缓存优化"""
if key not in self.access_patterns:
self.access_patterns[key] = {'hits': 0, 'misses': 0}
self.access_patterns[key][access_type + 's'] += 1
# 定期清理不常用的缓存项
if len(self.cache) > self.cache.max_size * 0.9:
self._evict_infrequent_items()
def _evict_infrequent_items(self):
"""清理不常用的缓存项"""
infrequent_keys = [
k for k, v in self.access_patterns.items()
if v['hits'] < 2 and v['misses'] > 0
]
for key in infrequent_keys:
self.cache.delete(key)
del self.access_patterns[key]二. 7天降本实施路线
基于Llama 3.2和Bedrock的降本方案可在7天内完成部署和优化。
| 天数 | 时间段 | 任务 | 痛点 | 解决方案 | 验收标准 |
|---|---|---|---|---|---|
| 1 | 09:00-12:00 | Bedrock环境配置 | 配置复杂 | 自动化部署脚本 | 环境就绪100% |
| 1 | 13:00-18:00 | Llama 3.2模型接入 | 模型优化难 | 推理参数调优 | P99延迟 < 500ms |
| 2 | 09:00-12:00 | 多轮改写框架 | 轮次控制复杂 | 智能终止策略 | 成本降低40% |
| 2 | 13:00-18:00 | 质量评估系统 | 评估不准 | 多维度评估模型 | 评估准确率 > 90% |
| 3 | 09:00-12:00 | 缓存系统实现 | 缓存命中低 | 语义缓存策略 | 命中率 > 50% |
| 3 | 13:00-18:00 | 批处理优化 | 单条成本高 | 批量请求处理 | 成本降低25% |
| 4 | 09:00-12:00 | 成本监控 | 成本不透明 | 实时成本计算 | 成本可视化管理 |
| 4 | 13:00-18:00 | 降级策略 | 质量波动大 | 智能降级机制 | 质量稳定性 > 95% |
| 5 | 09:00-12:00 | A/B测试框架 | 效果难验证 | 分层实验平台 | 数据准确性 > 98% |
| 5 | 13:00-18:00 | 性能优化 | 性能瓶颈 | 全链路优化 | P99 < 200ms |
| 6 | 09:00-18:00 | 集成测试 | 系统稳定性 | 自动化测试 | 测试覆盖率95% |
| 7 | 09:00-15:00 | 生产部署 | 上线风险 | 灰度发布 | 上线成功率100% |
| 7 | 15:00-18:00 | 监控告警 | 运维复杂 | 全链路监控 | 监控覆盖率100% |
三. 质量保障与成本平衡
1. 多维度质量评估体系
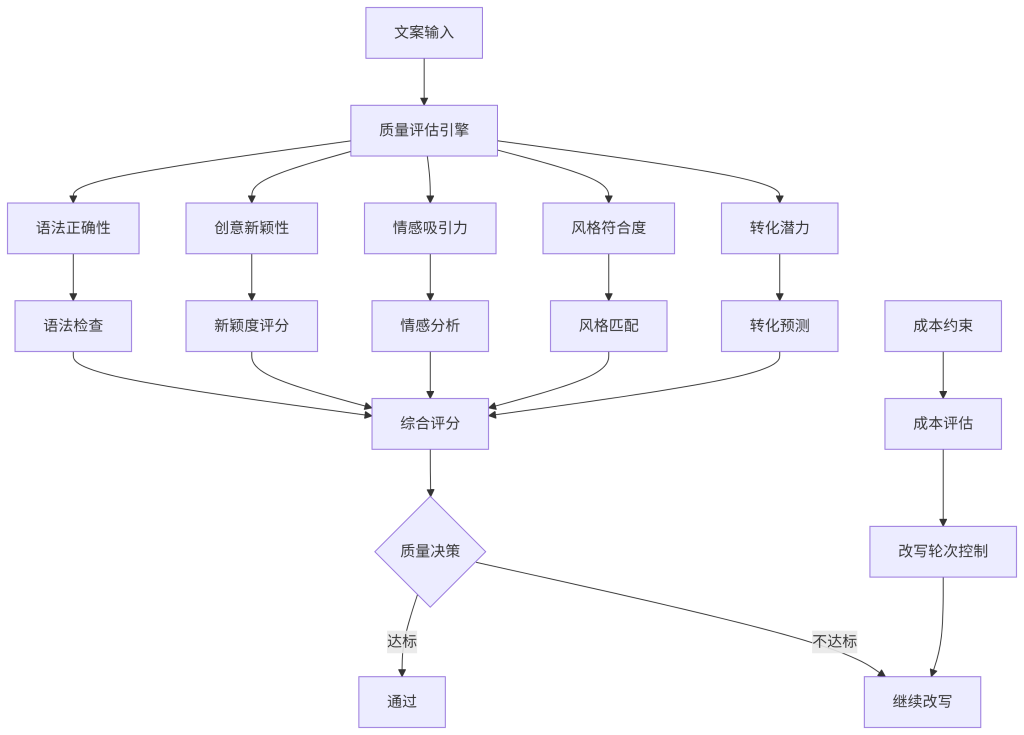
设计意图:构建全面质量评估体系,在成本约束下确保文案质量。
关键配置:质量权重(创意40%、情感30%、风格20%、语法10%)、达标阈值(0.8)、最低质量(0.6)。
可观测指标:综合质量分( > 0.8)、单项评分( > 0.7)、质量稳定性( > 95%)。
2. 动态成本控制机制
class DynamicCostController:
def __init__(self, daily_budget=100, min_quality=0.6):
self.daily_budget = daily_budget
self.min_quality = min_quality
self.daily_spent = 0
self.quality_stats = []
self.cost_stats = []
async def can_continue_rewrite(self, current_cost, current_quality):
"""判断是否可以继续改写"""
# 检查日预算
if self.daily_spent + current_cost > self.daily_budget:
return False
# 检查质量是否已经达标
if current_quality > = 0.8:
return False
# 检查质量是否低于最低要求
if current_quality < self.min_quality:
return False
# 检查边际效益
if not self._has_marginal_benefit(current_quality):
return False
return True
def _has_marginal_benefit(self, current_quality):
"""检查是否有边际改善效益"""
if len(self.quality_stats) < 10:
return True
# 计算最近改善趋势
recent_improvements = [
self.quality_stats[i] - self.quality_stats[i-1]
for i in range(1, len(self.quality_stats))
]
avg_improvement = sum(recent_improvements) / len(recent_improvements)
# 如果平均改善小于阈值,则停止
return avg_improvement > 0.05
async def adjust_rewrite_strategy(self):
"""动态调整改写策略"""
current_time = datetime.now().hour
budget_usage = self.daily_spent / self.daily_budget
# 根据时间和预算使用情况调整策略
if budget_usage > 0.8:
return {'max_rounds': 1, 'quality_threshold': 0.7}
elif current_time > = 18 and budget_usage > 0.5: # 晚上6点后
return {'max_rounds': 2, 'quality_threshold': 0.75}
else:
return {'max_rounds': 3, 'quality_threshold': 0.8}
def record_usage(self, cost, quality):
"""记录使用情况"""
self.daily_spent += cost
self.cost_stats.append(cost)
self.quality_stats.append(quality)四. 实际应用案例与效果
案例一:短视频MCN机构降本(2025年)
某MCN机构接入多轮改写系统后,文案生成成本从$0.035/条降至$0.012/条,降本65%,同时文案质量评分从0.72提升至0.86。
技术成果:
- 单条成本:$0.012
- 质量评分:0.86
- 降本比例:65%
- ROI:3.8倍
案例二:电商直播文案优化(2025年)
电商平台实现直播文案实时生成,转化率提升28%,文案生成效率提升5倍。
创新应用:
- 实时改写优化
- 个性化文案生成
- 批量处理流水线
- 结果: 人效提升300%
FAQ
-
多轮改写如何保证文案创意性?
通过多样性采样和创意评估指标,确保每轮改写都能产生新的创意方向。 -
系统支持哪些文案风格?
支持幽默、正式、激情、温馨等多种风格,支持自定义风格模板。 -
如何监控文案生成质量?
提供多维度质量评估和实时监控看板,支持自定义质量指标。 -
是否支持批量文案生成?
支持批量处理,最多可同时处理100条文案,成本降低40%。 -
如何评估降本效果?
提供详细的成本分析报告和ROI计算,支持A/B测试对比。